厉害了!这款百度炼丹神器绝了!
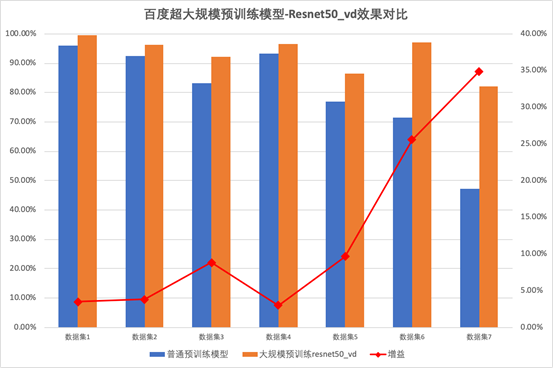
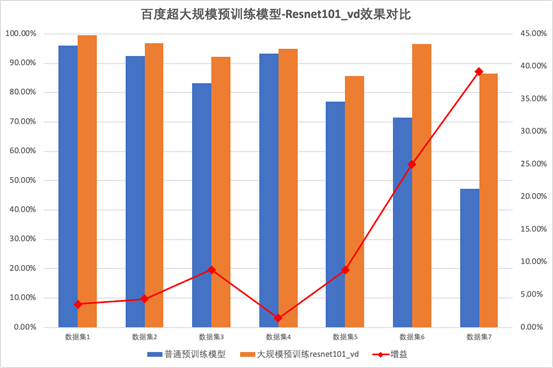
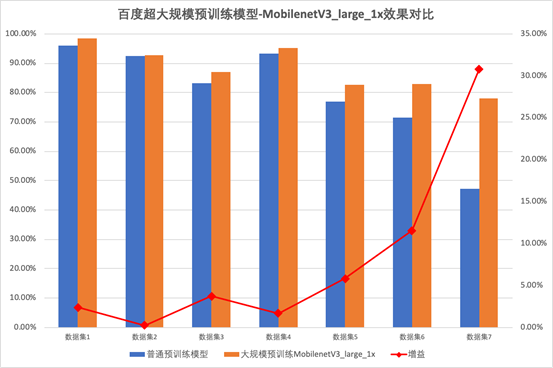
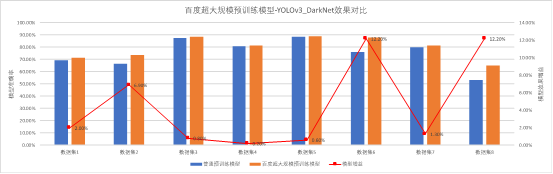
同时,也会在线上同步直播, 扫描海报二维码或点击阅读原文,报名进群获取完整课表与直播链接!

登录查看更多
相关内容

Arxiv
0+阅读 · 2021年1月31日
Arxiv
0+阅读 · 2021年1月29日
Arxiv
0+阅读 · 2021年1月29日
Arxiv
9+阅读 · 2019年2月21日
Arxiv
10+阅读 · 2018年12月4日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月31日
Arxiv
0+阅读 · 2021年1月29日
Arxiv
0+阅读 · 2021年1月29日
Arxiv
9+阅读 · 2019年2月21日
Arxiv
10+阅读 · 2018年12月4日