【中国计算机大会2017】丘成桐,沈向洋,李飞飞精彩演讲内容荟萃
点击上方“专知”关注获取更多AI知识!
丘成桐演讲全文:工程上取得很大发展,但理论基础仍非常薄弱,人工智能需要一个可被证明的理论作为基础
今天很荣幸地收到你们的邀请来做一个演讲。我本人在数学上的贡献不在计算机数学,最近这十多年来,由于我的学生顾险峰以及其他朋友的缘故,他们叫我帮忙做些跟计算机有关的学问。我发觉,纯数学,尤其是几何学在计算机方面有很大的应用。所以我今天就滥竽充数,讲讲几何跟计算机数学的关系。
一、现代几何的历史
首先,前面几分钟讲讲几何学历史。几何学一开始,就类似今天的人工智能,有很多工程上的应用以及产生的很多定理。不过随后欧几里得将当时主要的平面定理组合以后发现这些定理都可以由5个公理推出来。这是人类历史上很重要的一个里程碑,在很繁复的现象里,他找到了很简单但却很基本的五个公理,从而能将原来的这些公理全部推出来。我是很鼓励我们做人工智能的也能重复这个做法——从现在复杂多样的网络中找到它最简单的公理。
由于希腊人的工具不够,所以除了二次方程定义的图形(圆形、直线、椭圆等)以外,他们没有能力处理更一般的图形。一直到阿基米德,才开始做微积分的无限算法(积分体积),同时他们也开始做射影几何的算法。
微积分的出现使几何学进入了新纪元,微分几何也因此诞生。几何学在欧拉和高斯手上突飞猛进,变分方法和组合方法被大量地引入到几何学当中。
现代几何(近两百年的几何)主要发源于黎曼在1854年的博士论文,这篇论文奠定了整个现代几何的基础,他把几何图像看成一个抽象但是能够自足的空间。这个空间后来成为了现代物理的基础,现在物理中研究引力波等都是从黎曼这里开始的,没有黎曼这个空间,爱因斯坦不可能研究出来广义相对论。同时假如我们细看黎曼的这篇论文的话,就会发现,黎曼还认为离散空间也是一个很重要的空间。这个离散的空间包括了我们现在研究的图论,也用来研究宇宙万物可能产生的一切。所以即使是150年以后的今天,我们依然能看到黎曼的这个观点很重要。
二、对称的概念
几何学能够提供很多重要的想法,可以讲其影响是无所不在的。几何学的很多概念在高能物理和一般的物理学领域都产生重要的影响。其中一个重要的概念叫做“对称”。“对称”的概念是在1820年到1890年间由几个重要的数学家发展出来的。我们中国喜欢讲的阴阳,其实就是一个属于对称。在数学上有一个叫庞加莱对偶的概念,其实就是阴阳,但这个概念要比阴阳具体得多,同时也真正用在了数学的发展上。
19世纪,Sophis Lee发展的李群,也是物理学界最重要的工具之一,在现代物理中几乎没有一个学科可以离开李群的。
在几何学上,1870年的时候,伟大的数学家克莱因发表了《埃尔朗根纲领》,在这个纲领里克莱因提出用对称来统治几何的重要原理,随后产生了很多重要的几何学,包括仿射几何、保角几何和投影几何等。
这些几何对于图像处理都有密切的关系。我以及我的学生和朋友这十多年来就是用保角几何及种种几何来处理不同的图像。即使是当年看上去不重要的几何,现在实际上都有它重要的用处。这种种的计算都是从对称这个概念发展出来的。从大范围对称到小范围对称,这些在20世纪的基础研究中都有很成功的影响。
三、平行移动
另外一个很重要的概念,我想是很多做工程的人都没有注意到的,就是平行移动的概念。这个概念影响了整个数学界两千年。平行移动的概念其实就是一点和另外一点要有一个很好的比较的方法;计算机也好,图形学也好,在某一点上看到的事情要和其他点进行比较,比较的方法就叫平行移动。这也是一个很广泛、很重要的概念。现在在计算数学里面还没有大量的引进,但是在物理学界已经被大量地使用上了。所以我期望这些基本的概念以后能在计算机里面大量地使用。
四、几何学与计算机相互之间的影响
现在我们具体来讲一些的事情。现代几何为计算数学奠定了很多理论的基础,并且指导了计算机科学未来发展的方向。现代几何广泛应用到计算机的所有分支。举例来讲,计算机图形学、计算机视觉、计算机辅助几何设计、计算机网络等等都有广泛的应用。再例如,黎曼几何可以用来理解社交网络;现代几何理论也可以用来理解人工智能的特性。要记住,我们讲的几何并不是高中时代的几何,所有与图像或者网络有关的都是几何的一部分。
从另一方面来看,计算机学科的发展为现代几何提供了需求和挑战,也推动了跨学科的发展方向。例如:
人工智能中的机械定理证明推动了计算代数的发展;
数据安全、比特币、区块链的发展推动了代数数论、椭圆曲线和模形式的发展;
社交网络、大数据的发展催生了持续同调理论(persistent homology)的发展;
动漫、游戏的发展推动了计算共性几何学科的诞生和发展;
机器学习的发展推动了最优传输理论的发展等等。
五、计算机&几何学研究案例
我们下面举几个具体的例子,分别是图论、计算机图形学、计算机视觉、人工智能、深度学习等。这几个和几何都有密切的联系。
1、图论
我们先讲讲图论。图,就是一大堆顶点、一大堆边把它们连起来,这是最简单不过的事情。对于一个图,譬如交通图,我们要找出它们有着怎么样一个结构,什么地方比较拥挤。有时候我们也要研究怎么将这个图切成小部分,然后分解成简单的子图;如何衡量各个连通分支间的连接度;如何将图染色等。这些问题实际上都跟图上的特征函数有密切的关系。
图上的特征函数跟光滑图形上的特征函数有很类似的地方。我在40年前跟几个朋友,郑绍远、李伟光,做了一个工作,将光滑黎曼流形的特征函数推广到图上,得到了很好的结果。这些结果可以用来决定图上的连结的生成,研究图上的边创造过程,尤其是有个量的估值来控制在图上发散的过程。约束发散的过程可以应用到许多实际的过程中。我们还研究了图上的薛定谔方程,定义了图上的量子隧道概念。这些概念都是从物理上来的,被借用到图上。
假如我们在考虑有向图,就是每个点、每个边,给它一个方向,我们就可以将拓扑学整个引用到图上去,定义了图上的同调群。同调群可以用来研究图上密切的关系和它的内容。
现在我们来讲讲我们做的关于博弈理论的一个事情。进化图论为表达种群结构提供了数学工具:顶点代表个体,边代表个体的交互作用。图可以用来代表各种具有空间结构的群,例如细菌、动植物、组织结构、多细胞器官和社交网络。在进化过程中,每个个体依据自身的适应程度,进行繁殖病侵占到邻近顶点。图的拓扑反映了基因的演化——变异和选择的平衡。类似的,互联网是一个大网,一个非常复杂的网络,我可以在上面研究它的变化。社交行为的进化可以用进化博弈论来研究。个体和邻居博弈,根据收益而繁殖。个体繁殖速率受到自身与其他个体的交互作用影响,从而产生博弈的动态演化。其中心的问题就在于对于给定的图如何决定哪种策略会取得成功。
我们在今年年初的时候在nature上发了篇文章,我们得到一个结果,就是在任何给定的图上进行弱选择,自然选择从两种彼此竞争的策略中如何进行挑选,这个理论框架适用于人类决策,也适用于任何集群组织的生态演化。
我们从弱选择极限得到的结果,解释了何种组织结构导致何种行为。我们发现,如果存在成对的强纽带结构,合作就会大规模出现。我们用数学证明了社会学方面的一个结论:稳定的伙伴或者伴侣,对于形成合作型的社会起到了骨干作用。
2、计算机图形学:全局参数化 – 共形几何
下面我要讲的是“计算机图形学:全局参数化 – 共形几何”。这是我们发展了二十多年的一个学问。我和顾险峰从他还在哈佛念博士的时候(1999年)我们就开始做这个事情。
当我们将图形整体光滑映射到参数区域,使几何变得很小,会破坏掉整个图形;一般来讲这个要用手工来做,否则的话它变化非常大。针对这个问题,我们使用了纹理贴图、法向量贴图等等的方法。共性几何是一个很重要的从很古典的黎曼几何中产生的几何。

举例来讲,这个大卫的雕像,我们将它保角地映射到平面上去。它表面上看好像变化很大,但实际上变化不大,因为它是保角不变的。这在图像处理中是一个很重要的事情。举个例子来讲,从图上要画格点,因为我们画到平面上去以后,我们就可以将平面上画的很好的格点映射到脸上,就可以变成很漂亮的四方形的格点。这对工程处理有很多好处,其好处就是它将图上很小的圆映射到对方图上还是一个很小的圆,不会有扭曲,不会有太大的变化。

前面这些应用到一个数学上很重的定理,叫做庞加莱单值化定理,这是一个从黎曼时候开始的定理。就是讲映射的图形只跟它的拓扑性有关,这上面有三种几何,分别为:球面几何、欧氏几何、双曲几何。所有二维的几何,不管是什么样子的,我们都可以用这三种几何来分类。因此我们就可以将很复杂的事情很简单地描述出来。

上面这些我们得出了很好的结果。但是保角也有它的缺点,所以我们也发展了第二类映射,我们使得面元被保持,而角度不一定被保持。保角映射有时候可能将一个面拉的很远,左手边是保角映射,右手边是保面元映射。右面的图在不同的情形下会得出很好的结果。
3、计算机视觉,表情追踪 – 拟共映射
共性映射也可以应用到表情识别和追踪当中。我们可以自动地找到球面上曲面间的光滑映射,使得特征点匹配,使映射带来的变化很小。这是我们得到的一个很重要的结果。
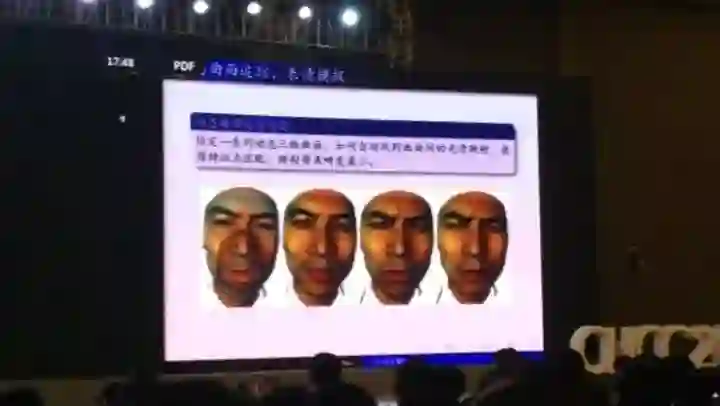
因此,我们可以用来追踪表情,表情捕捉。一个人他在笑、在哭、在种种不同的表现的时候,我们能够得到他的重要的面部特征,主要的方法就是我们将它映射到平面上,然后用共形映射或拟共形映射来研究它。这些都是很重要的数学工具,在计算上也有很重要的应用。
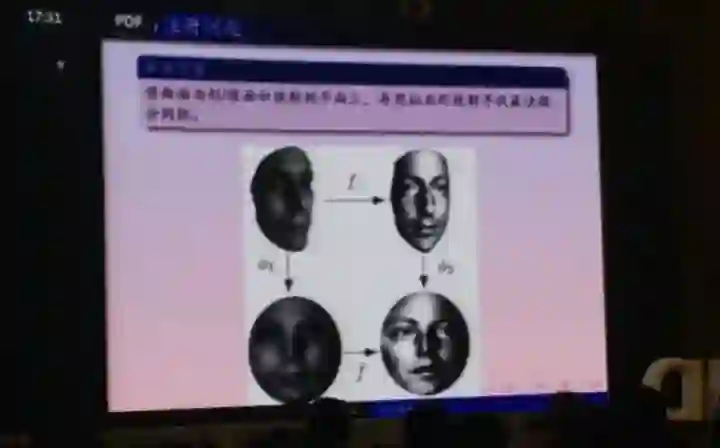
拟共形映射到目前来讲,纯数学家把它看得还是非常重要的,它不是一个正则方程,而是一个伪正则方程,也即Beltrami方程。这个方程在我们研究图像变形时在数学上是非常重要的,所以我们应用到图形处理里面去也得到很重要的结果。我们可在微分同胚的空间进行变化到最优的映射。它对医疗和动漫都有很重要的应用。
4、计算力学 – 六面体网格生成,叶状结构理论
我们也可以用同样的变化(保角映射)来产生六面体网格的生成和叶状结构理论。

这是在一只兔子上找到的好的网格。但是这个网格会产生一些奇异点(拓扑学的缘故)。针对这些奇异点,我们就做了一些研究,得出了很好的结论。

再比如,我们看这个曲面,在这个曲面上我们画出一些叶状的结构,可是它也有一定的奇异点。我们将这些奇异点分类,得出了一些在计算机科学上有意义的结论。

此外,全纯二次微分的网络中间有个六边形的变化。
5、数字几何处理-几何压缩:蒙日-安培理论,几何逼近理论
下面我们来看计算机的几何压缩中的蒙日-安培理论以及几何逼近理论。如何压缩复杂几何数据,同时保证几误差最小,保证黎曼度量、曲率测度、微分算子的收敛性,这些都是很重要的问题。我们用了很多共形映射的方法将曲面映射到平面去;再用蒙日-安培方程,将高曲率区域放大;随后重采样,在共性参数域上计算Delaunay三角剖分。这样得到的简化多面体网格就能够保证黎曼度量、曲率测度、微分算子收敛。
6、区块链:数字安全,椭圆曲线理论
这方面很多人都知道,这部分我就跳过去不再讲了。
7、人工智能
目前机器学习算法需要大量的样本。虽然现在比从前进步得多了,但规模还是很庞大。所以我们的想法是,让理论来帮忙处理这种复杂的数据学习。
在机器学习中有很多统计的内容,但是很多内容我们都不是很了解它是如何产生的。所以我们需要用一些比较严格的数学的理论来从这些复杂的现象中抽取出它们的本质。我们今天介绍一下用几何的方法来研究对抗生成网络(GAN)的事情。
生成对抗网络GAN(Generative Adversarial Networks)其实就是以己之矛克己之盾,在矛盾中发展,使得矛更加锋利,盾更加强韧。这里的盾就被称为判别器(Descriminator),矛被称为生成器(Generator)。生成器G一般是将一个随机变量(例如高斯分布或者均匀分布),通过参数化的概率生成模型(通常是用一个深度神经网进行参数化),进行概率分布的逆变换采样,从而得到一个生成的概率分布。判别器D也通常采用深度卷积神经网络。

举个例子来讲,有个概率分布u,u是基本的白噪音,影射到右手边的图片,一个概率分布v。我们从映射里看到GAN的问题其实就是:在两个概率分布u和v之间,找到一个最优的传输映射,从一个空间到另外一个空间,使它的概率分布是保持的。

u通过phi映射到v上去,同时我们要将它传输的代价变得最小。这样的变化是我们所需要的,因为这就不再需要像刚才所说的矛盾变化来达到最好的结果。我们知道,映射可以用一个方程来解决,所以我们其实就是要找一个凸函数U,它的梯度是我们的映射函数phi,它满足一个方程:蒙日-安培方程。
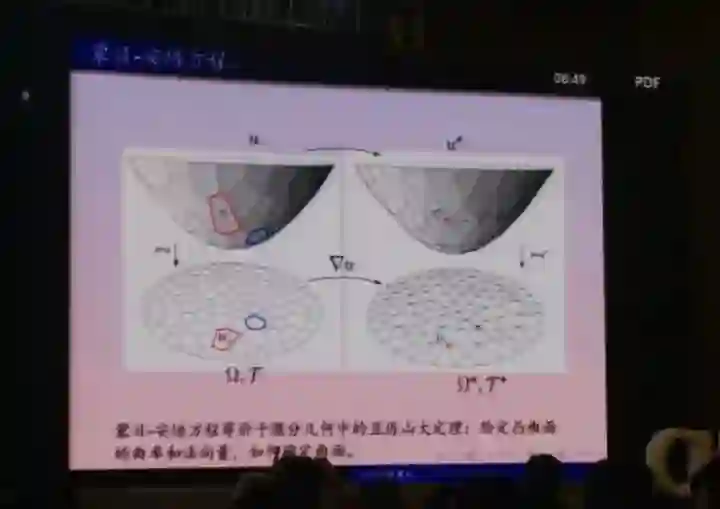
我们可以通过对这个方程进行求解的方式来找到最优传输映射,所以就节省很多生成对抗的时间。蒙日-安培方程本身其实是等价于微分几何中的亚历山大定理的。60年代就有人处理过这个方程,我自己也做过这个方程,前几年顾险峰跟他的学生也和我一起对它做了一个计算。
对抗生成网络实质上就是用深度神经网络来计算概率测度之间的变换。虽然规模宏大,但是数学本质并不复杂。应用相对成熟的最优传输理论和蒙日-安培理论,我们可以为机器学习的黑箱给出透明的几何解释,这有助于设计出更为高效和可靠的计算方法。
六、总结
我们看到现代数学和计算机科学的发展紧密相关,共形几何的单值化定理、蒙日-安培理论、最优传输理论等现代几何中的定理应用到计算机科学中的很多领域。我希望我们能够将更多那些表面上看来很高深的数学应用到我们日常的计算机上去,不但是能够有效地提出计算机的算法,同时也能够给它一个理论的基础。人工智能需要一个坚实的理论基础,否则它的发展会有很大困难。
沈向洋:人工智能正在改变世界
沈向洋简介


任何国家对自己自主知识产权的产品研究开发,都应该投入人力物力。不管是中国、美国还是任何一个大国都需要。从微软的角度考虑,我们也自己研发改进系统,我们也跟中国神州网信公司合作推出政府安全版Win10系统,实现中国政府可控的操作平台。
目前中国现在的软硬件研发发展特别好,国家源源不断地投入,培养了很多优秀的软硬件人才,而且中国的市场和产业体系丰富,有很多应用的场景。
目前看,全球一年生产3亿台PC,全球手机销售量也将近20亿台,目前手机的功能已经非常强大,而且有很多不是微软的系统。微软的系统,跟未来万国互联的大网络比较而言,只是一个很小的系统,这是各个国家都需要去面对的一个现象。所以业界目前的专注点是围绕人工智能的新发展,我们应该去看这样的发展。
人工智能已经开始从两个方向改变世界了,一个是感知,下一个是认知。目前感知方面的发展已经很迅速,视觉听觉的信息获取技术层出不穷,但“感知到”还不代表是“理解”的,在认知层面,人工智能的还发展比较慢,主要受限于自然语言理解技术的发展,这包括很多对语言的理解,对世界的理解,对人的理解,这方面还有多的路要走。
在感知的应用层面,比如计算机视觉,如刷脸技术,已经越来越可行,还有语音的合成,比如我们在做的机器翻译。现在全世界有6000多种语言,我们日常生活中的翻译是一个很常用到的功能,我们的Microsoft translator就是在做这个事情,下载这个应用,在手机中就可以实现人工智能的翻译,我们很有信心地说它是质量最好的,比如中文、英文、德语、西班牙语等主流语言我们都做得很好,但日语比较难做。
这些方面在短期还不能马上突破,不过人工智能在垂直行业的应用是很有前景的,如各行各业的技术应用。而从科研的角度看,最难的是自然语言的发展。地球历史这么长,人类在生物竞争中存活下来了,最重要之一就是是发明了语言,但是人类书写的语言只有5000年历史,再向前走,科技对于自然语言的理解和处理,对人类社会的发展是会有重大的影响的。
目前看,智能机器人服务人类生活,已经相当便利了。我们常提到4种智能机器人,包括智能搜索、智能聊天、智能助理和智能客服,智能助理好比是你的秘书,可以提醒你时间、地点、行程安排等,简单交流几个来回,交流更多的则是智能客服了,需要能处理一些复杂的问题。交流的次数多少,是观察智能产品的水平的关键。

这次大会不仅有计算机行业的专家和代表,还有各个基础和应用科学学科的专家。现在的科技融合越来越紧密。从前是没有计算机系的,我自己在80年代学习的时候还没有计算机系,以前是数学系研究理论的或自动化系做应用的人来做计算机。而美国最早也是60年代开始有了计算机系。未来随着计算机技术的不断普及和发展,原来做计算机的那批人第一个想到应用图片就是智能化,所以我们总提到图灵测试,这些人要做什么呢?第一个就是人工智能,以前机器可以计算,现在再向前发展,向各学科延伸发展,如脑科学、心理学、哲学,会有更大空间。
脑科学是我自己最看重的事情,但目前可能投入还远远不够,认识还需要比较深刻的突破。因为科学要大量数据,需要重复试验,但今天脑科学还没有发展到这个地步。我们对自然语言的理解,对自然语言对话中的分析还不够成熟,我们不完全清楚大脑怎样运作,不能像别的机器那也模仿着制造一个,这就像是脑科学里面的空气动力学。
自然语言理解的三部曲是“描述,对话,理解”。就像写文章,从记叙文、议论文再到诗歌散文,我自己觉得,文史哲对对一个人的能力培养的影响是巨大的,因为所有研究拼到最后的就是你的理解和悟性。做学问这个事情,不是想做就能做得出来的。所以我们开计算机大会,也需要不是本学科内的专家观点,需要融汇贯通,文学和社会学能把各方面的知识影响融合起来,所以很多科学研究都是交叉学科的成果。这种会议,主要不是让学生学到什么,而是能让听者受到启发,理解我们为什么做这样的事情,理解这些人是怎么想的。
中国企业的科研能力的正在加速发展,我个人对此充满信心,对中国的高校也充满信心。我本人在一些大学做客座教授,有包括福州的学生,他们能力非常强。人才最重要是培育环境,微软有亚洲研究院,过去19年我们培养了5000多名学生,在IT、互联网行业都体现了非常重要的作用,这些人很多是我们的院友。要有这样的环境去人才,现在中国的企业也很清楚,阿里、腾讯这么多年也有自己的想法,我自己对他们充满信心。
李飞飞:视觉智慧是人类和计算机合作沟通的桥梁

李飞飞首先介绍了构建视觉智能中的第一个里程碑,那就是物体识别。人类具有无与伦比的视觉识别能力,认知神经科学家们的许多研究都展示出了这一现象。李飞飞在现场与听众们做了一个小互动,在屏幕上闪过一系列持续时间只有0.1秒的照片,不加任何别的说明,而观众们还是能够识别到有一张中有一个人。
MIT教授Simon Thorpe在1996年的一个实验中,也通过记录脑波的方式表明,人类只需要观察一张复杂照片150ms的时间,就能辨别出其中是否包含动物,不管是哺乳动物、鸟类、鱼,还是虫子。
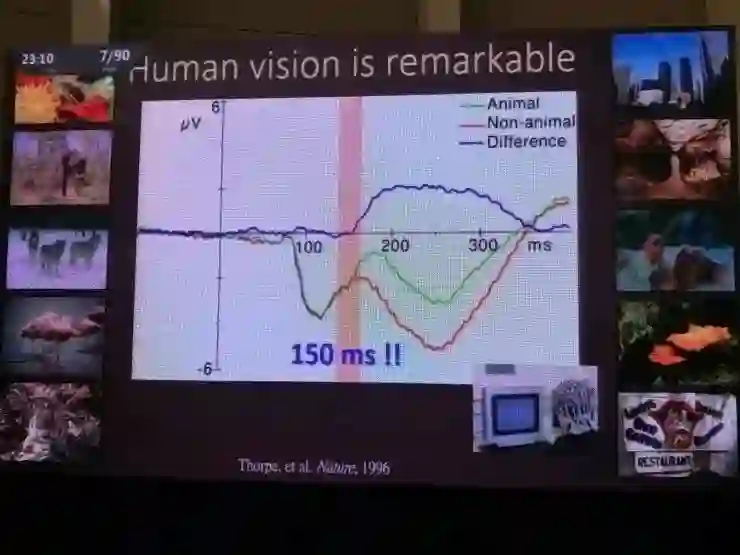
这种对复杂物体的快速视觉识别能力是人类视觉系统的基本特质,而这也是计算机视觉中的“圣杯”。在过去的20年中,物体识别都是计算机视觉社区研究的重要任务。ImageNet就是起到了贡献的数据集之一。
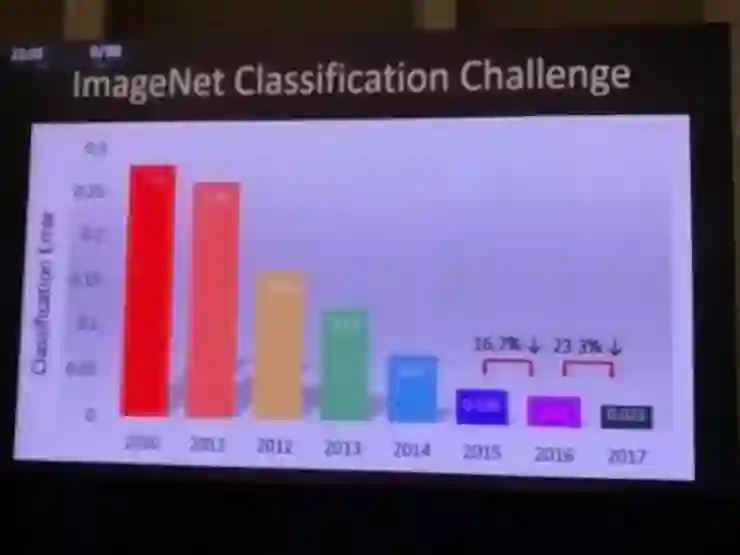
从2010年以来,从 2010 到 2017,ImageNet 挑战赛的物体识别错误率下降到了原来的十分之一。到 2015 年,错误率已经达到甚至低于人类水平。这基本表明计算机视觉已经基本攻克了简单的物体识别问题。
计算机视觉研究当然不会止步于 ImageNet 和物体识别,这仅仅是人类丰富视觉感受的基础。

下一个关键步骤就是视觉关系的识别。这项任务的定义是:“把一张照片输入算法模型中,希望算法可以识别出其中的重点物体,找到它们的所在位置,并且找到它们之间的两两关系”。
两张照片都是人和羊驼,但是发生的事情完全不同。这就是单纯的物体识别所无法描述的了。

在深度学习时代之前,这方面也有不少的研究,但多数都只能在人为控制的空间中分析空间关系、动作关系、类似关系等寥寥几种关系。随着计算力和数据量的爆发,在深度学习时代研究者们终于能够做出大的进展。这需要卷积神经网络的视觉表征和语言模型的结合。
在李飞飞团队ECCV2016的收录论文中,他们的模型已经可以预测空间关系、比较关系、语义关系、动作关系和位置关系,在“列出所有物体”之外,向着场景内的物体的丰富关系理解迈出了坚实的一步。

除了关系预测之外,还可以做无样本学习。举个例子,用人坐在椅子上的照片训练模型,加上用消防栓在地上的图片训练模型。然后再拿出另一张图片,一个人坐在消防栓上。虽然算法没见过这张图片,但能够表达出这是“一个人坐在消防栓上”。

类似的,算法能识别出“一匹马戴着帽子”,虽然训练集里只有“人骑马”以及“人戴着帽子”的图片。

在李飞飞团队的 ECCV 2016 论文之后,今年有一大堆相关论文发表了出来,一些甚至已经超过了他们模型的表现。她也非常欣喜看到这项任务相关研究的繁荣发展。
在物体识别问题已经很大程度上解决以后,李飞飞的下一个目标是走出物体本身。微软的Coco数据集就已经不再是图像+标签,而是图像+一个简短的句子描述图像中的主要内容。
经过三年的准备后,李飞飞团队推出了Visual Genome数据集,包含了10万张图像、420万条图像描述、180万个问答对、140万个带标签的物体、150万条关系以及170万条属性。这是一个非常丰富的数据集,它的目标就是走出物体本身,关注更为广泛的对象之间的关系、语言、推理等等。

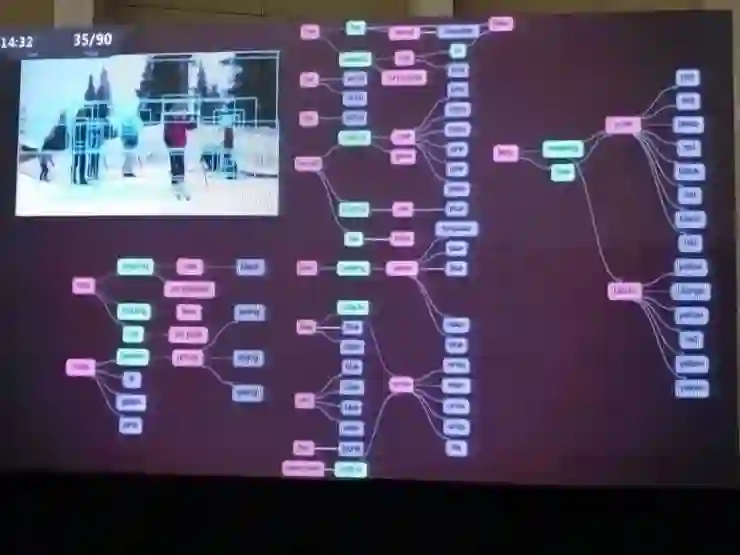
在Visual Genome数据集之后,李飞飞团队做的另一项研究是重新认识场景识别。
场景识别单独来看是一项简单的任务,在谷歌里搜索“穿西装的男人”或者“可爱的小狗”,都能直接得到理想的结果。
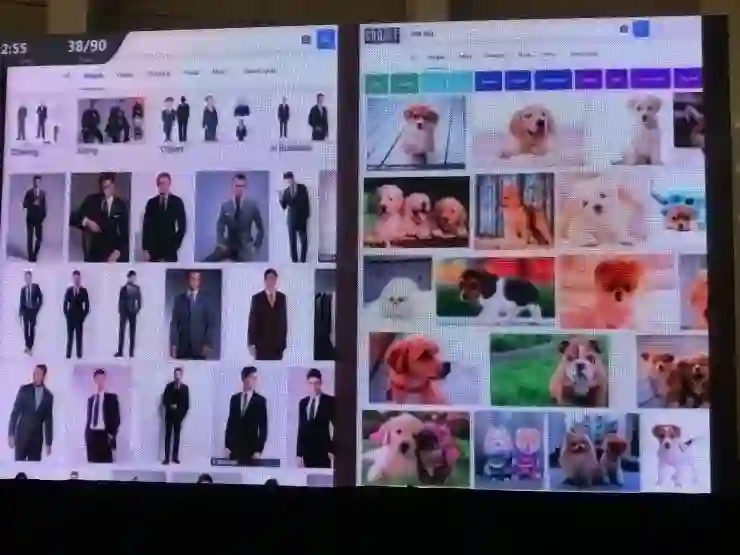
但是当你搜索“穿西装的男人抱着可爱的小狗”的时候,就得不到什么好结果。它的表现在这里就变得糟糕了,这种物体间的关系是一件很难处理的事情。
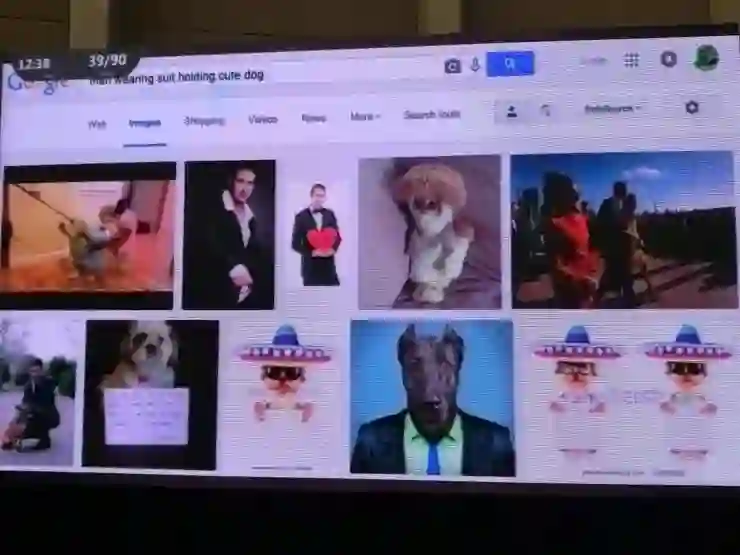
如果只关注了“长椅”和“人”的物体识别,就得不到“人坐在长椅上”的关系;即便训练网络识别“坐着的人”,也无法保证看清全局。

他们有个想法是,把物体之外、场景之内的关系全都包含进来,然后再想办法提取精确的关系。

如果有一张场景图(graph),其中包含了场景内各种复杂的语义信息,那场景识别就能做得好得多。其中的细节可能难以全部用一个长句子描述,但是把一个长句子变成一个场景图之后,我们就可以用图相关的方法把它和图像做对比;场景图也可以编码为数据库的一部分,从数据库的角度进行查询。
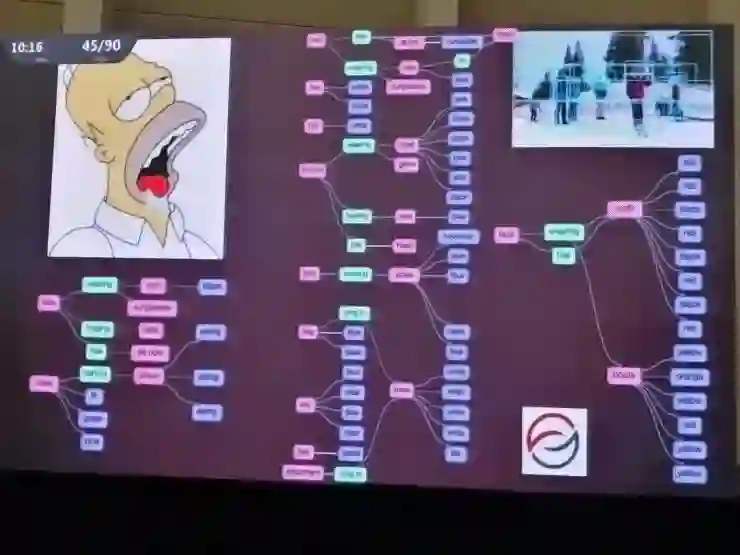
李飞飞团队已经用场景图匹配技术在包含了许多语义信息的场景里得到了许多不错的量化结果。不过,这些场景图是谁来定义的呢?在Visual Genome数据集中,场景图都是人工定义的,里面的实体、结构、实体间的关系和到图像的匹配都是李飞飞团队人工完成的,过程挺痛苦的,他们也不希望以后还要对每一个场景都做这样的工作。所以在这项工作之后,他们也正在把注意力转向自动场景图生成。

比如这项她和她的学生们共同完成的CVPR2017论文就是一个自动生成场景图的方案,对于一张输入图像,首先得到物体识别的备选结果,然后用图推理算法得到实体和实体之间的关系等等;这个过程都是自动完成的。
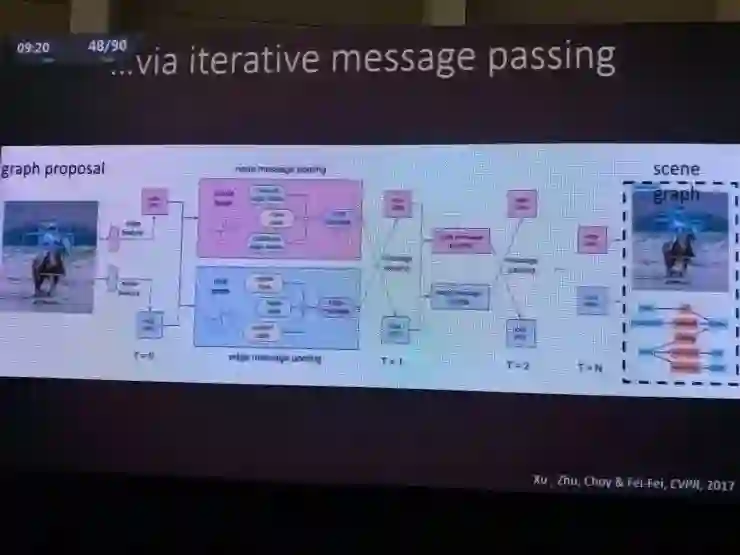
这里涉及到了一些迭代信息传递算法,李飞飞并没有详细解释。但这个结果体现出的是,这个模型的工作方式和人的做法已经有不少相似之处了。

这代表着一组全新的可能性来到了人类面前。借助场景图,们可以做信息提取、可以做关系预测、可以理解对应关系等等。
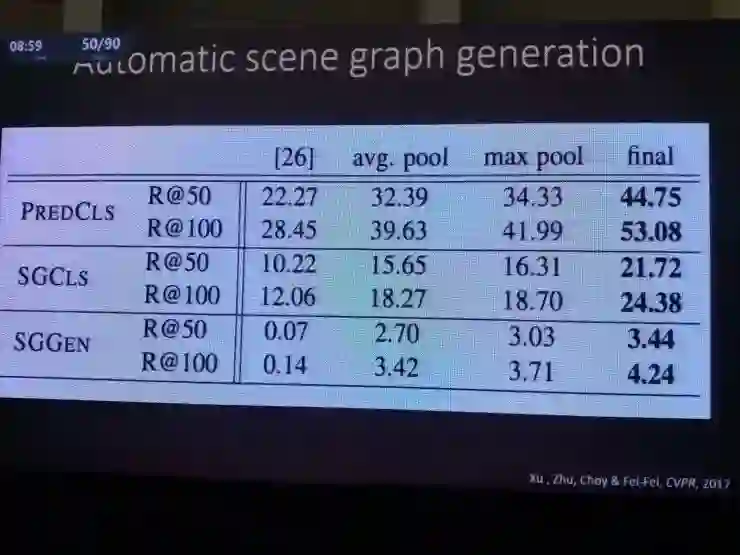
QA问题也得到了更好的解决。

还有一个研究目标是,给图片配上整段的说明文字。
当李飞飞在加州理工学院读博士的时候做过一个实验,就让人们观察一张照片,然后让他们尽可能地说出自己在照片中看到的东西。当时做实验的时候,在受试者面前的屏幕上快速闪过一张照片,然后用一个别的图像、墙纸一样的图像盖住它,它的作用是把他们视网膜暂留的信息清除掉。
接下来就让他们尽可能多地写下自己看到的东西。从结果上看,有的照片好像比较容易,但是其实只是因为我们选择了不同长短的展示时间,最短的照片只显示了27毫秒,这已经达到了当时显示器的显示速度上限;有些照片显示了0.5秒的时间,对人类视觉理解来说可算是绰绰有余了。

对于这张照片,时间很短的时候看清的内容也很有限,500毫秒的时候他们就能写下很长一段。进化给了我们这样的能力,只看到一张图片就可以讲出一个很长的故事。
在过去的3年里,CV领域的研究人员们就在研究如何把图像中的信息变成故事。

他们首先研究了图像说明,比如借助CNN把图像中的内容表示到特征空间,然后用LSTM这样的RNN生成一系列文字。这类工作在2015年左右有很多成果,从此之后我们就可以让计算机给几乎任何东西配上一个句子。

比如这两个例子,“一位穿着橙色马甲的工人正在铺路”和“穿着黑色衬衫的男人正在弹吉他”。


这都是CVPR2015上的成果。两年过去了,李飞飞团队的算法也已经不是最先进的了,不过那时候确实是是图像说明这个领域的开拓性工作之一。
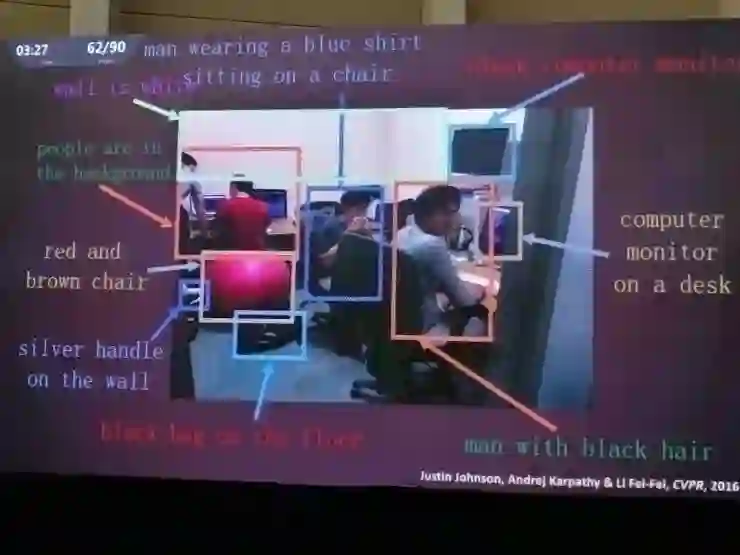
沿着这个方向继续做研究,他们迎来的下一个成果是稠密说明,就是在一幅图片中有很多个区域都会分配注意力,这样有可以有很多个不同的句子描述不同的区域,而不仅仅是用一个句子描述整个场景。在这里就用到了CNN模型和逻辑区域检测模型的结合,再加上一个语言模型,这样就可以对场景做稠密的标注。
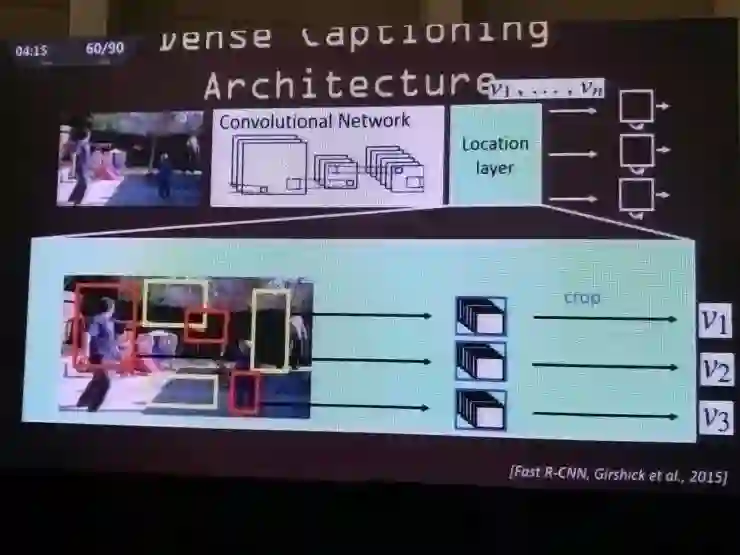
比如这张图里就可以生成,“有两个人坐在椅子上”、“有一头大象”、“有一棵树”等等

另一张李飞飞的学生们的室内照片也标出了丰富的内容。
在最近的CVPR2017的研究中,他们让表现迈上了一个新的台阶,不只是简单的说明句子,还要生成文字段落,把它们以具有空间意义的方式连接起来。这样我们就可以写出“一只长颈鹿站在树边,在它的右边有一个有叶子的杆子,在篱笆的后面有一个黑色和白色的砖垒起来的建筑”,等等。虽然里面有错误,而且也远比不上莎士比亚的作品,但我们已经迈出了视觉和语言结合的第一步。

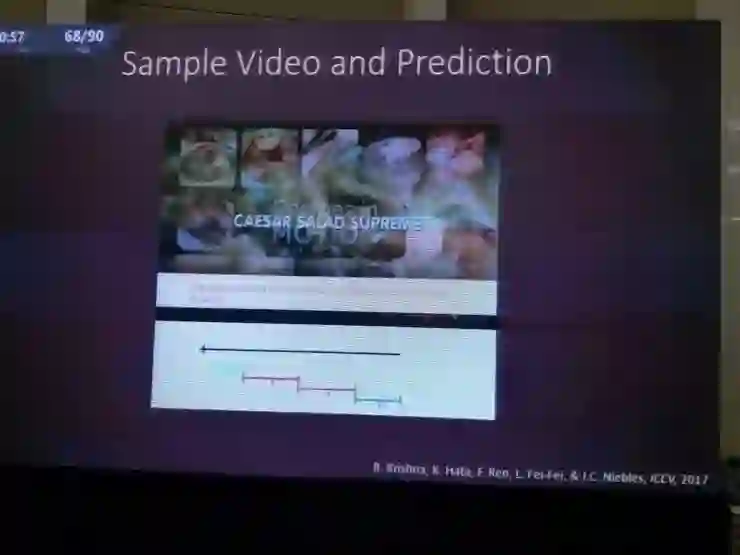
而且,视觉和语言的结合并没有停留在静止的图像上,刚才的只是最新成果之一。在另外的研究中,他们把视频和语言结合起来。

比如这个CVPR2017的研究,可以对一个说明性视频中不同的部分做联合推理、整理出文本结构。这里的难点是解析文本中的实体,比如第一步是“搅拌蔬菜”,然后“拿出混合物”。如果算法能够解析出“混合物”指的是前一步里混合的蔬菜,那就棒极了。
在语言之后,李飞飞还介绍了任务驱动的视觉问题。对整个AI研究大家庭来说,任务驱动的AI是一个共同的长期梦想,从一开始人类就希望用语言给机器人下达指定,然后机器人用视觉方法观察世界、理解并完成任务。
这是一个经典的任务驱动问题,人类说:“蓝色的金字塔很好。我喜欢不是红色的立方体,但是我也不喜欢任何一个垫着5面体的东西。那我喜欢那个灰色的盒子吗?” 那么机器,或者机器人,或者智能体就会回答:“不,因为它垫着一个5面体”。它就是任务驱动的,对这个复杂的世界做理解和推理。

李飞飞团队和Facebook合作重新研究这类问题,创造了带有各种几何体的场景,然后给人工智能提问,看它会如何理解、推理、解决这些问题。这其中会涉及到属性的辨别、计数、对比、空间关系等等。

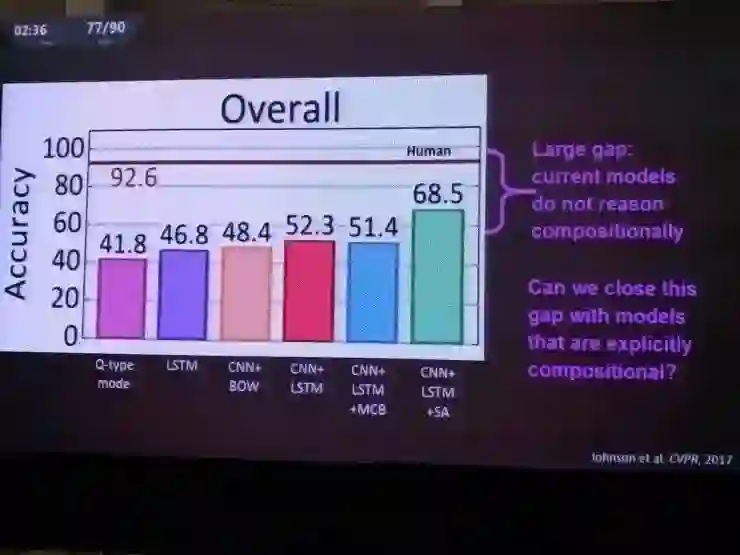
在这方面的第一篇论文用了CNN+LSTM+注意力模型,结果算不上差,人类能达到超过90%的正确率,机器虽然能做到接近70%了,但是仍然有巨大的差距。有这个差距就是因为人类能够组合推理,机器则做不到。
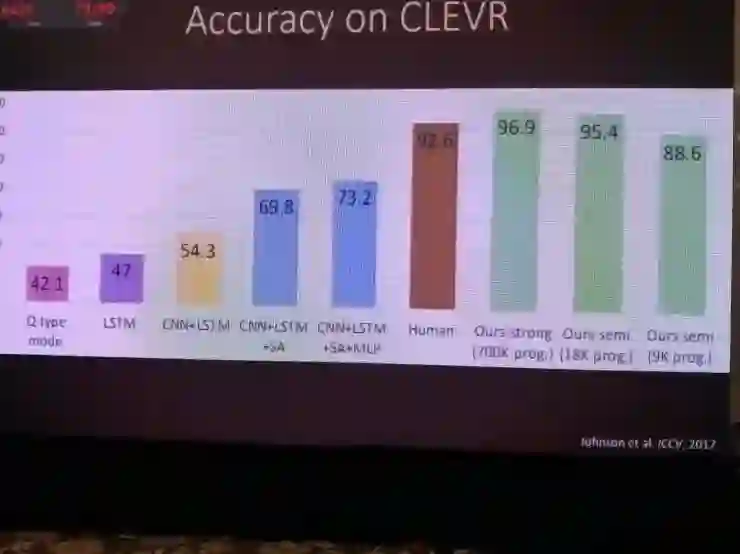
而在ICCV上,他们介绍了新一篇论文中的成果。借助新的CLEVR数据集,把一个问题分解成带有功能的程序段,然后在程序段基础上训练一个能回答问题的执行引擎。这个方案在尝试推理真实世界问题的时候就具有高得多的组合能力。

在测试中也终于超出了人类的表现。
模型的实际表现当然不错。比如这个例子里,我们提问某种颜色的东西是什么形状的,它就会回答“是一个立方体”这样,表明了它的推理是正确的。它还可以数出东西的数目。这都体现出了算法可以对场景做推理。热力图也展示出了模型正确地关注了图中的区域。

图像相关的任务说了这么多,李飞飞把它们总结为了两大类
首先是除了物体识别之外的关系识别、复杂语意表征、场景图;
在场景gist之外,我们需要用视觉+语言处理单句标注、段落生成、视频理解、联合推理;

李飞飞最后展示了她女儿的照片,她只有20个月大,但视觉能力也是她的日常生活里重要的一部分,读书、画画、观察情感等等,这些重大的进步都是这个领域未来的研究目标。

视觉智慧是理解、交流、合作、交互等等的关键一步,人类在这方面的探索也只称得上是刚刚开始。

(完)
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!





