案例分享|爱奇艺 TF Serving 负载均衡问题研究及改进实践


发布人: 爱奇艺技术产品团队
通常来说,负载均衡的职责是将网络请求或者其他形式的负载“均摊”到不同的机器上,避免集群中部分服务器压力过大,而另一些服务器比较空闲的情况,让每台服务器获取到适合自己处理能力的负载。在为高负载服务器分流的同时,还可以避免资源浪费,一举两得。
负载均衡可分为软件负载均衡和硬件负载均衡,其中软件负载均衡比较常见,比如 Nginx,它会对接受请求进行分配,避免少数服务提供者负载过大而导致的部分请求超时。因此将负载均衡到每个服务提供者上,是非常必要的。
在分布式的微服务系统中,多台服务器同时提供一个服务,并统一到服务配置中心,消费者通过查询服务配置中心,获取服务到地址列表,需要选取其中一台来发起 RPC 远程调用。如何选择则取决于具体的负载均衡算法,对应于不同的场景选择不尽相同。负载均衡算法的种类有很多种,常见的负载均衡算法包括轮询法、随机法、源地址哈希法、加权轮询法、加权随机法、最小连接法、Latency-Aware 等,需根据具体的应用场景选取对应的算法。
本文将围绕爱奇艺内容理解业务对 TF Serving 服务调用的几个问题,以及应对这些问题的解决思路和方案进行介绍。

爱奇艺内容理解业务大多使用深度学习模型,而模型的在线服务依赖于爱奇艺深度学习推理平台。通常,推理平台使用 gRPC 作为服务框架,部署在 QAE 平台上,使用 QLB 四层(以下简称 QLB-4 )作为负载均衡方案。理论上一个 VIP 对应多台后端服务器,通过 QLB-4 自身的负载均衡策略,可以实现有效的服务器负载均衡访问,但是在大量的深度学习模型在线服务调用过程中,我们发现有以下几类问题:
1. QLB-4 未能实现真正的负载均衡,流量未被均匀分配,存在部分服务器访问量明显过多问题。
2. 当有新的服务端实例时(包括重启和新增场景),客户端流量不能分配到新的服务端实例上,需要重启客户端,流量才会重新分配到新的服务端实例。
3. 当客户端数量小于服务端数量时,一定会有部分服务端一直没有接收到客户端请求。
本次实验将 gRPC 客户端和服务端均部署在 QAE 上,服务端入口网络流量这一指标能直接体现服务端请求接收情况,因此选用服务端入口网络流量作为观测指标。以下实验图x轴为时间轴,y 轴为当前时间段网络流量的平均值,具体实验如下:
问题 1:QLB-4 未能实现真正的负载均衡,流量未被均匀分配,存在部分服务器访问量明显过多问题。
实验机器数量配置如下表:

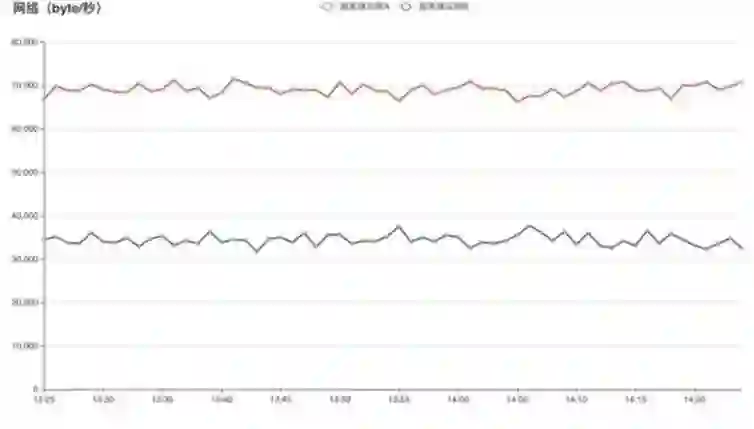
图 (a) 使用 QLB-4 的 gRPC 客户端在服务端的流量分布情况
图 (a) 中,两个服务端实例接收到的流量大概为 2:1,说明是有两个客户端请求流向了同一个服务端。
问题 2:当有新的服务端实例时,客户端流量不能分配到新的服务端实例上。
实验机器数量配置如下表:

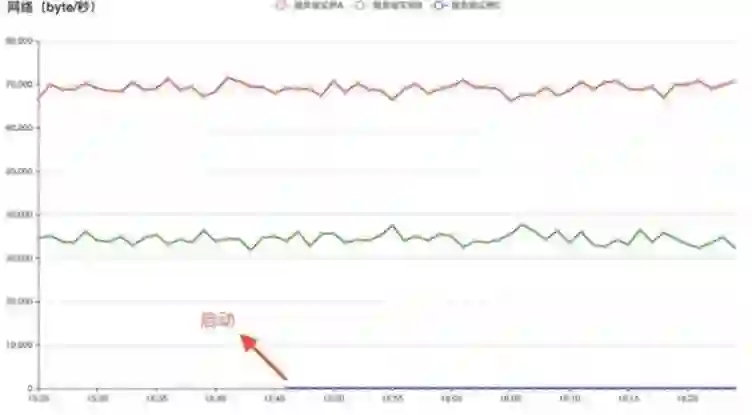
图 (b) 使用 QLB-4 的 gRPC 客户端在新增服务端的流量分布情况
图 (b) 中,新增的服务器实例 C 启动后,并没有客户端流量打向新增节点 C;
问题 3:当客户端数量小于服务端数量时,一定会有部分服务端一直没有接收到客户端请求。
实验机器数量配置如下表:

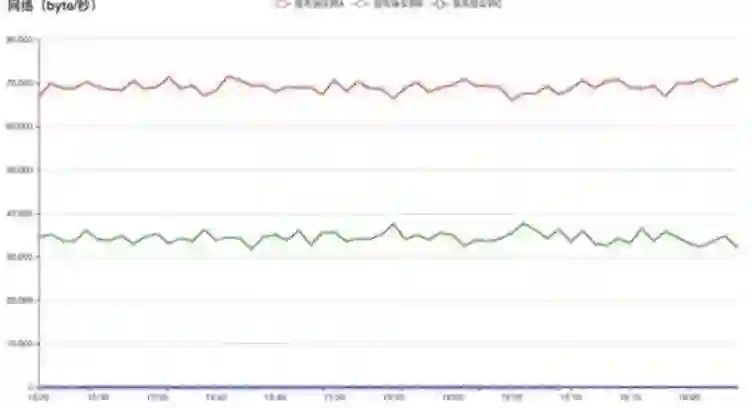
图 (c) 使用 QLB-4 的 gRPC 调用在服务器数
大于客户端数情况下流量分布情况
从图 (c) 中可以看出,在服务器数大于客户端数的情况下,服务器 C 一直没有流量进入。
QLB-4 是工作在 OSI 第四层 (TCP) 的负载均衡器,主要工作流程如下图(一)所示:客户端通过 VIP(VirtualIP Addres) 访问网络服务,请求报文到达调度器,调度器根据连接调度算法从一组真实服务器中选出一台服务器,将报文发送给选出的服务器。同时,调度器在连接 Hash 路由表中记录这个连接,当这个连接的下一个报文到达时,从连接 Hash 路由表中可以得到原选定服务器的地址和端口,用同样的方式将报文传给原选定的服务器。整体流程如下图1所示:
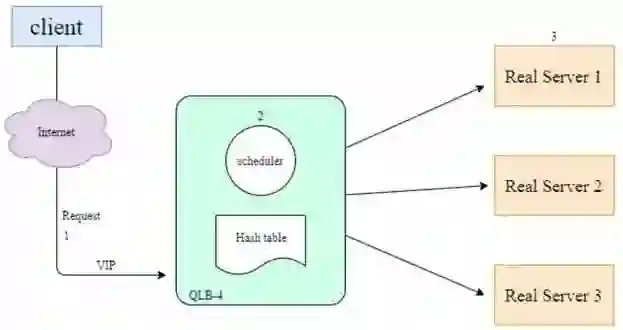
图 1. QLB-4 负载均衡原理图
对于问题 1,由于初次调用路由表会作记录,就相当于调度器会为每个客户端连接分配一台固定的服务器,未能实现实时的请求动态路由转发,进而不能实现真正的负载均衡调用;
对于问题 2,当新的服务端实例启动时,虽然 QLB-4 会增加,但由于客户端连接在 Hash 路由表中没有改变,报文到达 QLB-4 后,还是会被转发到原选定的服务器。当客户端重启后,TCP 连接重新建立,调度器会为客户端重新选择服务器,此时新的服务器实例有可能被调度器选择,将报文转发到新的服务实例。如果一定要实现新的服务端调用,为此就需要重启客户端,带来极大的上线运维问题;
对于问题 3,如果服务器数量多于客户端,由于一个客户端只会对应固定的一台服务器,就一定会存在服务端没有被调度器选中的情况,即使按照每个客户端都由不同的服务器来提供服务计算,也会有大于客户端数量的服务器资源浪费,而 GPU 资源本身就比较昂贵,所以浪费成本会比较大。
解决方案一:基于 QLB-4 的负载均衡优化
QLB-4 负载均衡的主要问题是在于 Hash 路由表中缓存记录的时效性和全面性,QLB-4 负载均衡中 Hash 路由表的存在主要是为了快速查找后端服务器,但是由于在服务器发生变化时未能及时更新,进而引起了上述的一些问题。故基于 Hash 路由表的改进点如下:
1. 在服务器发生变化时清空 Hash 路由表,再重建,可以解决 Hash 路由表中缓存记录的全面性问题;
2. 对 Hash 路由表中缓存记录设置过期时间,这样在某一个时间点来看,可能还有负载不均衡问题,但可以实现全局性的负载均衡。
QLB-4 负载均衡的所有问题基本都来自于 Hash 路由表,故亦可以考虑去掉 Hash 路由表的方案,即进行实时的负载均衡调度,但是效率上会比 Hash 路由表有所下降,不适合高并发场景。
解决方案二:客户端负载均衡
使用客户端负载均衡策略,基于公司服务注册中心,客户端负载均衡工作方式是将服务列表清单存储在本地,通过定时任务刷新本地缓存,然后对服务列表进行轮询的方式达到负载均衡的作用,与 QLB-4 相比的优点主要有:
1. 客户端负载均衡是基于请求端做的负载均衡,能够均匀地将流量分配到各个服务端;
2. 客户端负载均衡中客户端与服务端是直连方式,比 QLB-4 要少一跳,能有效减少网络转发耗时对 RPC 的影响。实现客户端负载均衡的重点是如何自动的获取服务列表并保证服务列表的有效性,结合公司 Skywalker 微服务框架,我们引入 Consul 组件作为客户端负载均衡的服务发现引擎,原理如下图 2 所示:
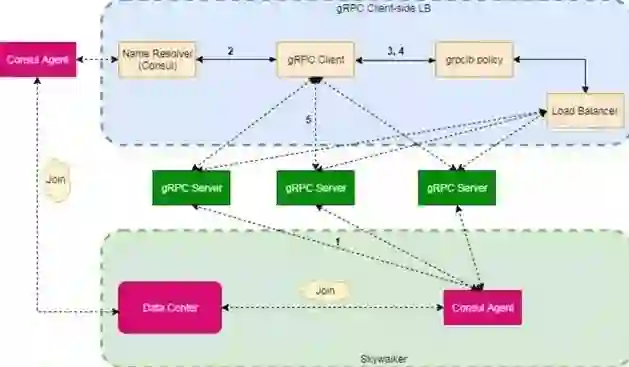
图 2. 客户端负载均衡原理图
整体工作原理详细描述:
1. 基于 gRPC 的 TF Serving 服务端实例启动,首先会向 ConsulAgent 注册实例,ConsulAgent 定时向服务进行健康检查。这一步 Skywalker 已经实现,我们只需要简单的配置就能实现将服务注册到相应的数据中心。在同一个数据中心下,ConsulAgent 之间的数据是共享的,因此我们只需要部署一个 ConsulAgent 加入对应的数据中心,就能方便的查询相关 TF Serving 服务的健康节点信息。
2. gRPC 客户端向 Consul Agent 发送请求,通过服务名获取相关服务的节点信息。为了维护客户端服务列表的有效性,我们需要定时向 Consul 发送请求信息,及时获取最新的服务列表。特别注意的是,如果在定时请求服务列表的间隙,服务端某个实例变得不可用,这种情况下,我们通过 gRPC 客户端重试机制来解决,客户端重试的时候会为此次请求轮询地选择下一服务节点发送 RPC,避免此次请求失败。
3. 客户端负载均衡器为服务列表创建 Channel 连接池,里面包含和每一个 TF Serving 服务器的连接通道。
4. 客户端调用时负载均衡器会根据具体的负载均衡算法选择一个 TF Serving 服务器 Channel 连接。
5. 客户端通过该 Channel 连接向选择的服务器发送 gRPC 请求,若成功,则结束;若失败,则重试最大次数至成功。
方案对比:方案一依赖于 QLB-4 的改进和实现,由公司中间件平台主要负责,考虑到其他业务场景的限制,最终我们选择了方案二,在客户端实现负载均衡,不仅实现了功能,还提升了调用效率。
最终的解决方案上线后,线上的 TF Serving 服务调用稳定,不再出现负载不均和上下线服务无法发现和调用问题。不仅解决了之前服务发布后,客户端需要重启的运维难题,降低了运维成本,而且实现了服务器的合理调度,避免了公司昂贵的 GPU 资源的浪费,降低了整体的硬件成本。

推荐阅读


点击“阅读原文”访问 TensorFlow 官网
不要忘记“一键三连”哦~

分享

点赞

在看





