付彦伟:零样本、小样本以及开集条件下的社交媒体分析
点击上方“深度学习大讲堂”可订阅哦!
编者按:随着社交媒体及数字采集设备的普及,网络上存在着海量的视频及图像数据,如果能够充分利用这些数据,将促进相关计算机视觉任务的发展。然而这些数据却面临着数据样本分布不均衡、以及样本无监督等问题,因此如何在样本量不足甚至零样本、以及样本无标注的情况下,充分利用社交媒体中的数据,成为了计算机视觉领域的开放式问题。本文中,来自复旦大学大数据学院的付彦伟副研究员将就这一问题进行讨论。大讲堂特别在文末提供文章以及代码的下载链接。


首先介绍一下我本人,我博士就读于伦敦玛丽女王大学,导师是向涛教授和龚少刚(Shaogang Gong)教授。之后在匹兹堡CMU的Disney Research做博士后。

我今天介绍的内容可以概括为四个单词:Overview,Definition,Embedding,More.
Overview


对社交媒体中的大数据进行分析,其数据来源分为两个部分,一是YouTube,Flicker和Instagram上的图像视频数据,二是Facebook,Wechat,Google+上的用户关系数据。这二者都属于社交媒体分析中的大数据,是我研究的主要topic。

首先来说对图像、视频数据的分析,众所周知,这种数据量非常庞大,可以用来做零样本、小样本以及开集条件下的图像分类,动作识别,活动识别,以及感情识别。基于以上四个问题,我主要介绍下面几个工作:


对于关系型数据,我们从统计里的ranking和概率图模型的角度来分析更多类型的问题,比如crowdsourcing ranking on Internet和social network。对于这类问题,也是要分析one-shot、zero-shot等条件下的识别,我们也做了一些工作:

Definition


首先说一下对one-shot,zero-shot,open-set recognition的定义。对于识别任务而言,人类通过视觉系统和听觉系统获取图像信息和声音信息,再经人脑处理得到识别结果。这就启发我们去做监督识别。
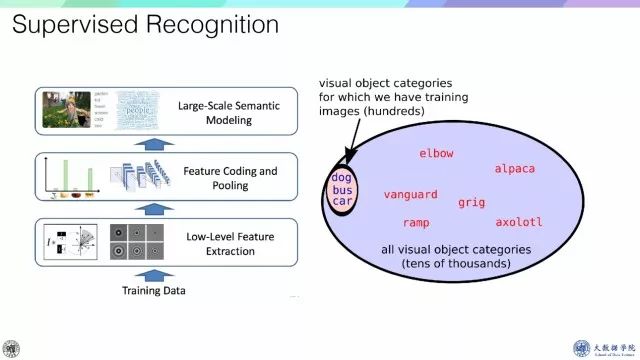
深度学习将传统方法从训练数据、低层次特征提取、特征编码和池化再到大规模语义建模的过程变为端到端的学习过程。但是大千世界芸芸众生,能收集到的样本只是一小部分,尤其人类可以动态构造一些新类别,因此需要收集一些新数据来训练模型。
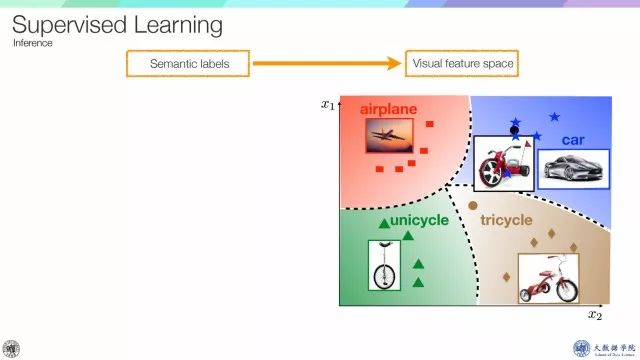
One-shot learning 是基于监督学习的,在某个空间(如视觉空间),根据语义标签训练相应的分类器,因为training inference较少,所以称之为one-shot。但是one-shot learning不能识别从未见过的物体类别,这就启发了最近的zero-shot learning。
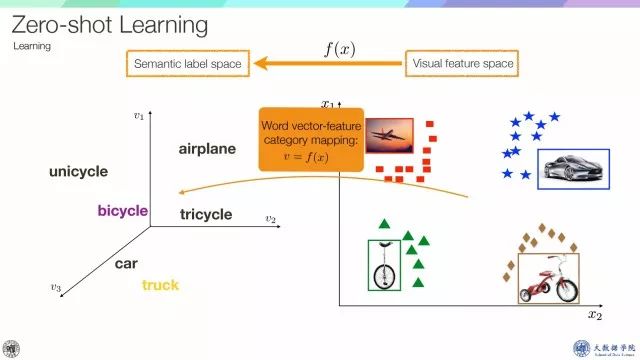
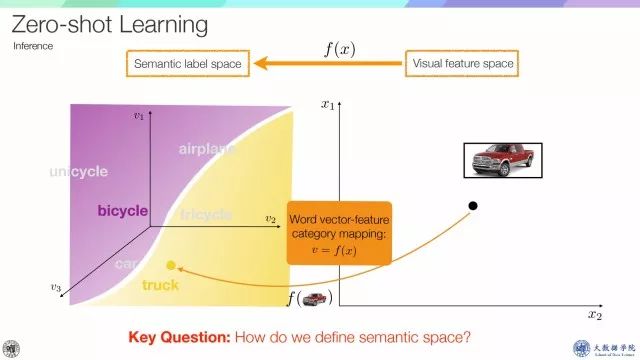
Zero-shot learning是为了识别未知类别的样本,其思想是迁移一些已知的辅助类别语义知识。如图黑色字体标签就是辅助类别,我们可以根据已知的辅助类别样本来学习从视觉空间到语义标签的映射,所有测试样本都会被投影到该语义空间,然后被赋予相应的标签信息,这里的关键是如何选取语义标签。

如图所示,一般的语义标签大体上可以分为两类,一类是Semantic Attributes(语义属性),它具有很好的解释性但需要大量的人工标注,而另一类是Semantic Word Vectors(语义向量),可以从大量文本中训练出来,并不需要人工标注,并有大量的free vocabulary。
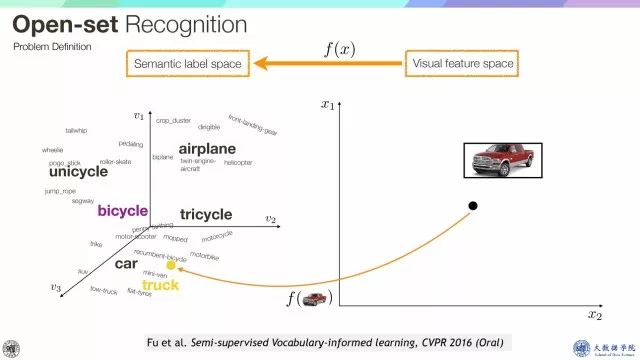
Attribute learning识别的未知类别数量一般并不大,可以把这类思想推广到open-set recognition,open-set recognition就是从大量图片词汇类别中识别图像视频的语义标签。
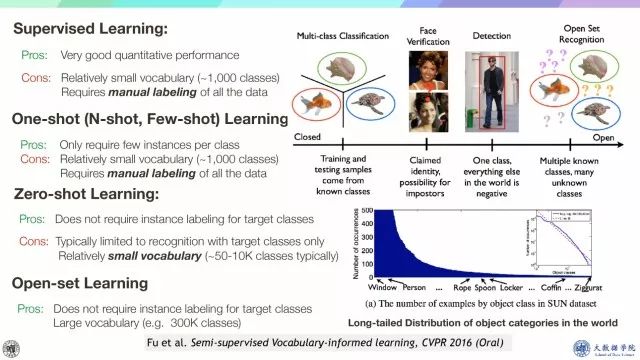
以识别问题为例,总结一下零样本、小样本以及开集条件下的任务。也可以扩展到其他类似问题。
有监督学习:能够取得较好的表现效果,但需大量人工标注;
小样本学习(one-shot, N-shot, Few-shot):每类只需很少样本,但也需大量人工标注;
零样本需学习:不需要样本标签,但是目标类别数受限;
Open-set Learning:不需要样本标注,有大量的样本库。
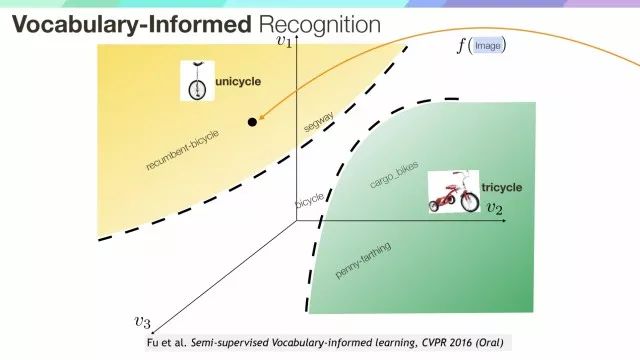
另一方面我们可以利用free-vovabulary词汇来帮助整个学习过程,比如图像被映射到语义空间,在这个空间中,只知道unicycle或tricycle,在零样本学习情况下,我们更倾向于把它归为unicycle,因为它靠近unicycle的语义原型。
而空间里面如果含有其他的free vocabulary,比如segway,recumbent bicycle,测试样本如果和它们靠的更近,那么可能就不能把这个样本认为是unicycle,也就是说通过这个free-vocabulary,可以更新这个从特征空间到语义空间的matrix。
Embedding

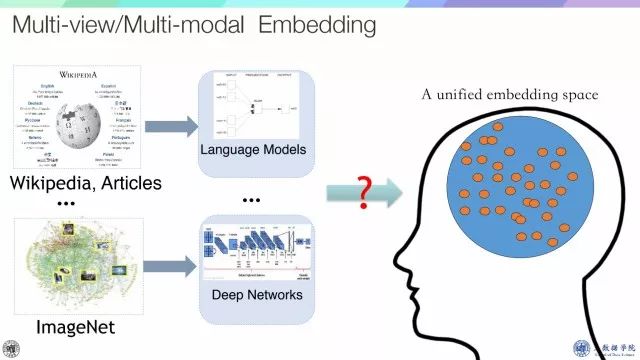
下面说一下其他的工作embedding,再从实际来看,人类摄入很多文章和照片,对于文章和图片都可以训练很好的深度学习模型,那么人脑会不会形成统一的embedding space呢?假设这个观点是成立的,那么研究出发点就是如何做mutli-view/multi-modal embedding。

我们第一个工作是Learning multi-modal latent attributes。
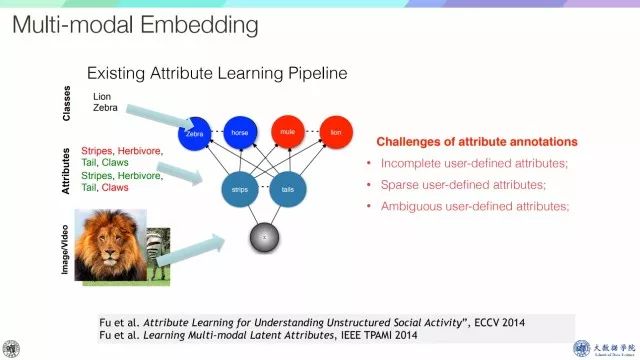
回顾一下属性学习,从浅层特征到属性,再到类别,这里的关键是属性,但是属性一般较依赖于人工的标注,对属性的定义常常有很多挑战,比如不完整、稀疏或者比较模糊,这就依赖从数据中挖掘属性。

这里给出一些例子,这是我们的数据集,模型可以从这些类别中挖掘对应的latent attribute。
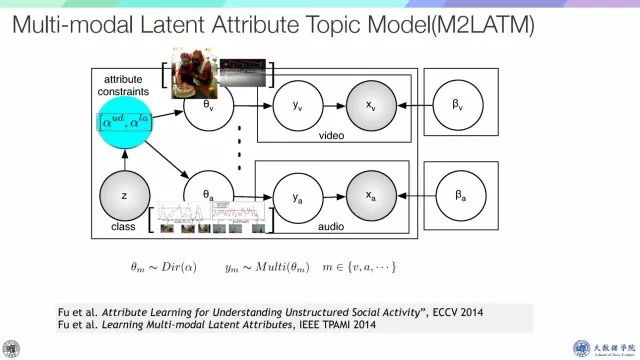
基本的模型结构如图所示,通过multi-modal latent attribute topic model来建模视频、音频等模态数据之间的关系,这里的属性可以是用户自定义的,也可以是潜在的属性,我们可以在attribute claim 中加以限定,通过topic挖掘对应的信息。

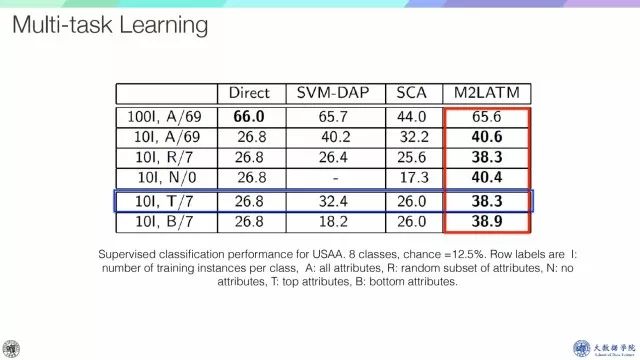
我们在USAA数据集和AwA数据集上进行了实验,结果如上表所示,把属性当作video attention的话,可以做多任务学习。
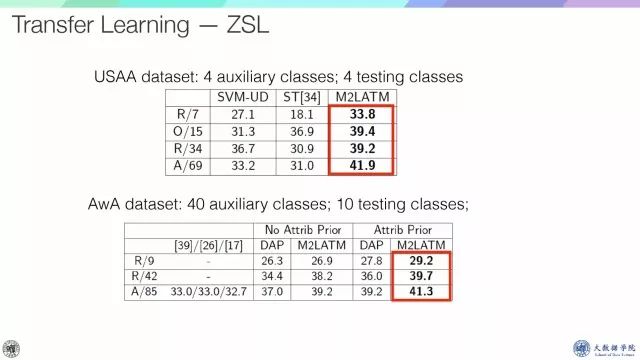
对于不同的用户自定义属性,结果也非常好。

在这个框架下,还可以做one-shot learning。

还可以可视化哪些浅层特征对应哪些属性,是用于自定义的还是自身潜在的属性。

第二个工作是multi-view embedding。
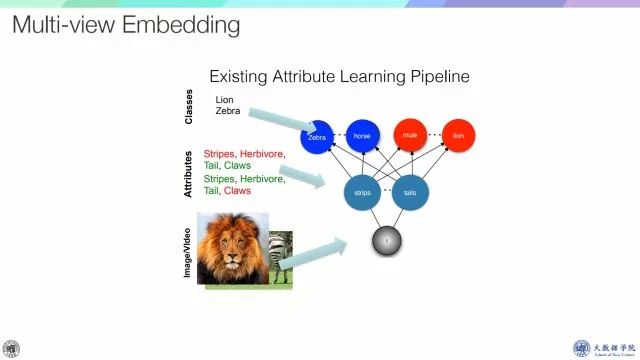
再回顾一下这个框架,从浅层特征到属性、类别。
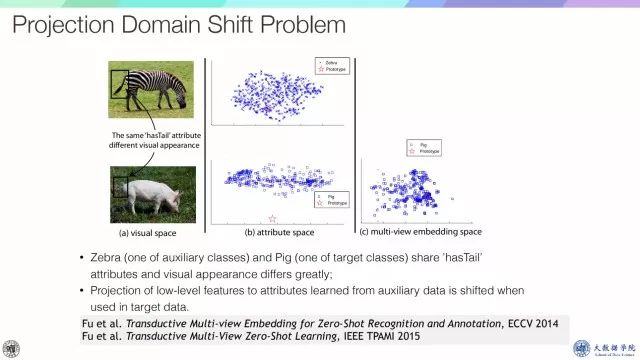
在零样本学习中,有两个问题。第一个是projection domain shift问题,比如,斑马和猪,斑马是辅助训练数据,而猪是目标数据,它们都有hasTail这个属性,但是它们的视觉属性是非常不一样的,把从辅助数据中学习到的浅层特征直接映射到未知数据上,一定会出现domain shift的问题,而这个domain shift其实是一个多维问题,我们称之为projection domain shift问题。
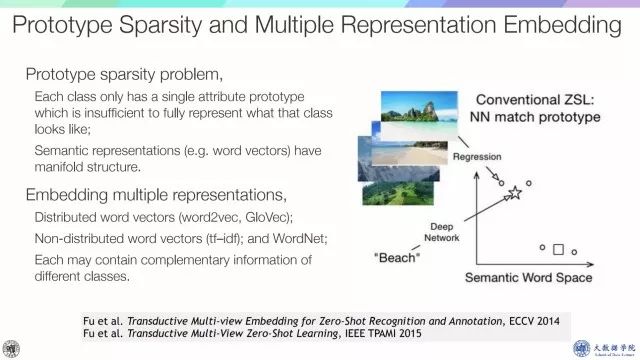
第二个问题是prototype sparsity问题,也就是每一个新类其实只有一个attribute prototype,那么就需要考虑是否能利用数据本身的信息,比如manifold information,第三个是embedding multiple representations,我们现在已有semantic attribute,semantic word vector,考虑把它们嵌到一起。
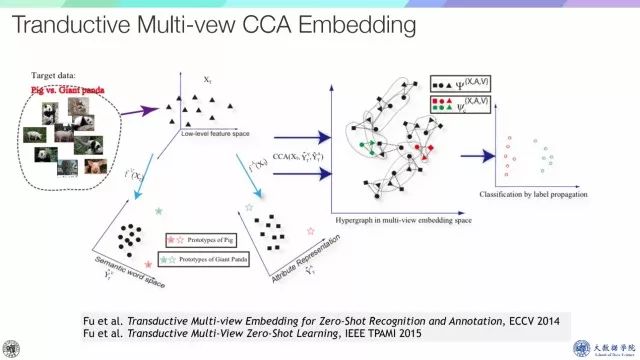
基于这三个问题,我们提出了一个算法框架。假设在目标数据上可以得到不同的子空间,每一个空间代表每一个view,利用一个multi-view CCA把数据投影到CCA space,在这个空间里面构造一个graph或者hyper graph,然后进行ranking,这样就可以做one-shot learning,zero-shot learning,甚至open set learning。
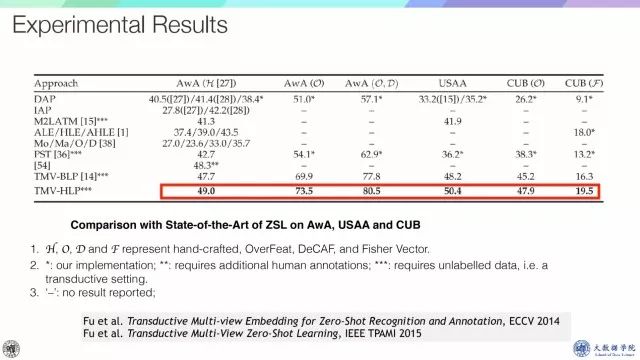
在三个标准测试集上的结果显示效果非常好,尤其是AwA,这是2014年的结果,AwA的结果已经能达到80.5。
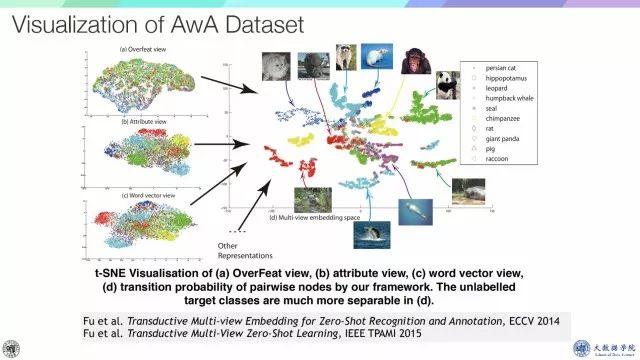
通过可视化可以得知,在原始空间中,可能有些测试类别是无法分开的,但是在embedding space中这些类别是可以区分得非常好。

下面来介绍一下Pairwise Graph Embedding。

关系类型的数据标注,可以统称为Subjective visual properties。比如比较两幅图像哪一个更漂亮,哪一个更有意思,哪一个笑得更多一些,这是更好的语义表示,它的歧义性更小,更有利于迁移学习。我们定义subjective visual properties,类似的问题包括image/video interestingness & aesthetics,以及image memorability & image/video quality等。

对于这类数据,我们一般是要做Crowdsourced Paired Comparisons来收集它的标注信息,这里的优势在于,标注起来更节省成本,可以标注大规模的数据集。这里有个问题,一个是outliers,另一个是sparsity,因为毕竟是一个稀疏空间。

我们提出了一个robust learning to rank框架来解决上述两个问题,这里图像是一些合成样本,左边是若干人脸,比较他们的年龄,我们收集了一些temporation,绿色是predict,红色是outline,根据得到的信息预测ranking。

我们可以构造一个有向图,在这个有向图上,我们可以outline,用form乘Lasso,这里的gamma是一个outline variable,叫incidental parameter。

所以我们提出了一个Preconditioned Lasso方法。
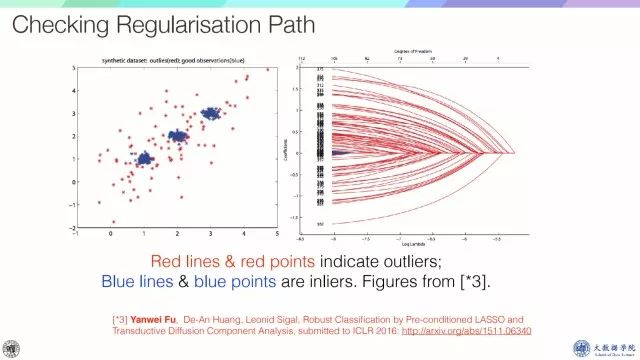
我们的解法是用Regularisation Path,左边蓝色点对应inline,红色点对应outline,如果check regularisation path会发现,从右到左变换拉姆达值的时候,outline会首先出现,所以就可以对所有这些点进行排序,然后top就是outline。
More

最后简单回顾一下我们其他的一些工作。
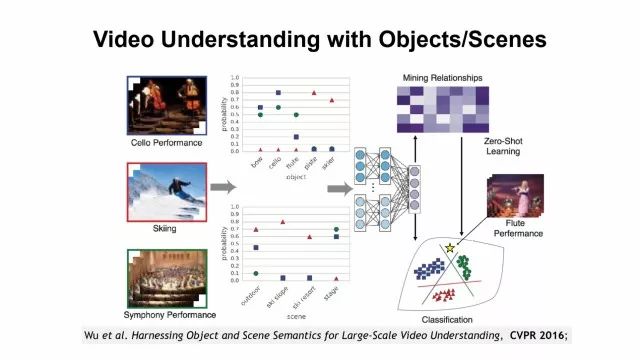
视频理解,通过深度学习来embedding 目标或者场景,做action,activity,one-shot learning,zero-shot learning。上图为video emotion understanding的工作。
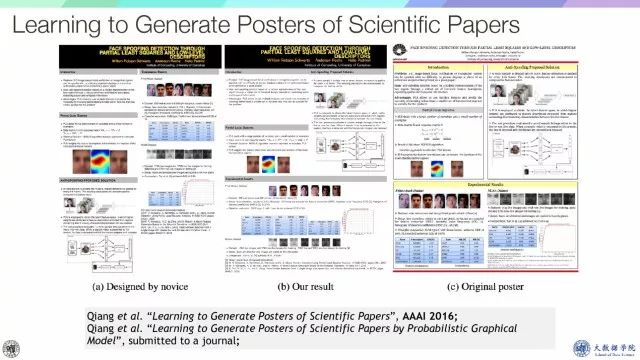
以及如何利用概率图模型来自动生成海报。
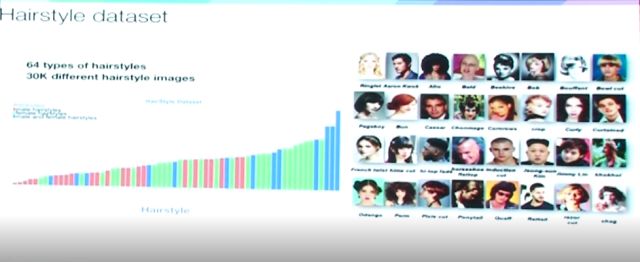
最后,分享一个我们建的发型数据集,其中收集了64种不同的发型,大约三万张不同人脸标注。

文中引用文章的下载链接为:
https://pan.baidu.com/s/1i5KTjXr

本文主编袁基睿,编辑杨茹茵。

该文章属于“深度学习大讲堂”原创,如需要转载,请联系 astaryst。
作者信息:
作者简介:

付彦伟,青年副研究员,2014年获得伦敦大学玛丽皇后学院博士学位。入选2017年度上海市青年科技英才扬帆计划。主要研究领域包括计算机视觉与模式识别、机器学习与统计学习、情感计算、多媒体视频分析与处理等,有IEEE TPAMI, CVPR等顶级期刊会议论文20篇,10项中国、3项美国专利。
VALSE是视觉与学习青年学者研讨会的缩写,该研讨会致力于为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。2017年4月底,VALSE2017在厦门圆满落幕,近期大讲堂将连续推出VALSE2017特刊。VALSE公众号为:VALSE,欢迎关注。

往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站



