CVPR2019 | 中科大&微软提出:姿态估计新模型HRNet(已开源)
点击上方“CVer”,选择"星标"和“置顶”
重磅干货,第一时间送达

圆栗子 发自 凹非寺
转载自量子位(QbitAI)

中科大和微软亚洲研究院,发布了新的人体姿态估计模型,刷新了三项COCO纪录,还中选了CVPR 2019。
这个名叫HRNet的神经网络,拥有与众不同的并联结构,可以随时保持高分辨率表征,不只靠从低分辨率表征里,恢复高分辨率表征。
如此一来,姿势识别的效果明显提升:
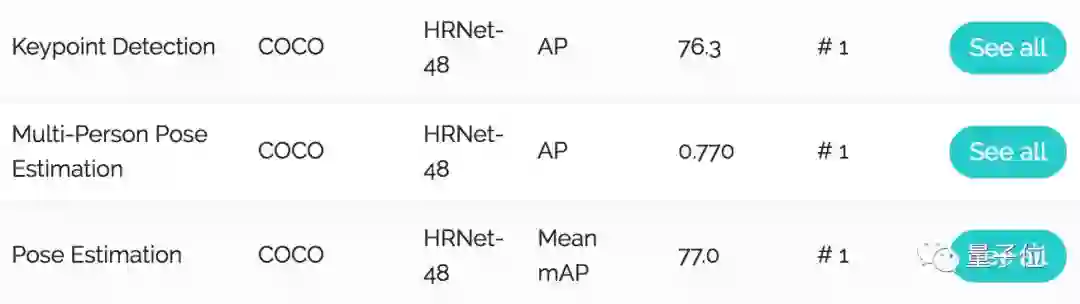
在COCO数据集的关键点检测、姿态估计、多人姿态估计这三项任务里,HRNet都超越了所有前辈。
更加优秀的是,团队已经把模型开源了。
结构不一样
HRNet,是高分辨率网络 (High-Resolution Net) 的缩写。
团队希望,在表征学习 (Representative Learning) 的整个过程中,都能保持高分辨率表征。
所以,他们为模型设计了并联结构,把不同分辨率的子网络,用新的方式连在一起:
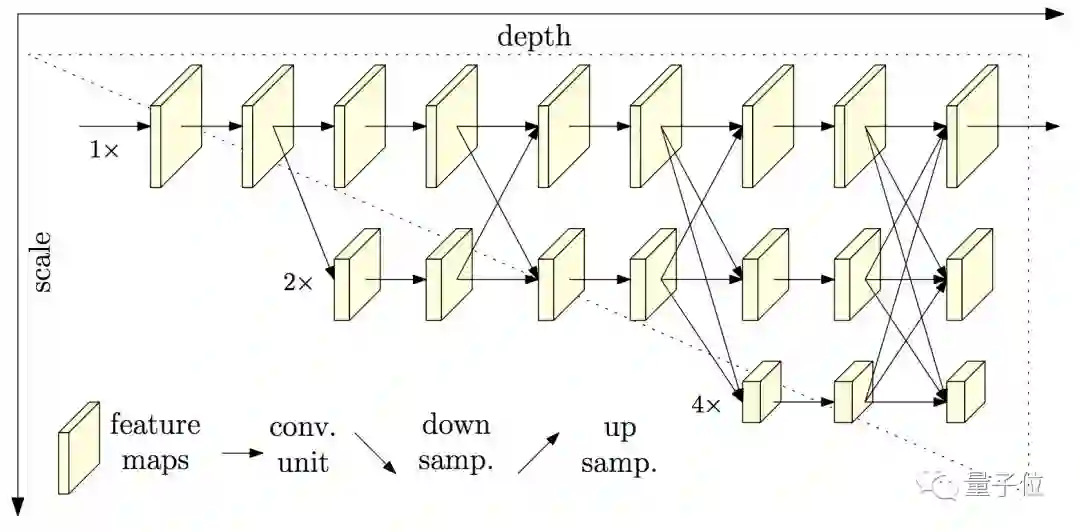
△ 并联
对比一下,前辈们连接各种分辨率,常常是用简单的串联,不论由高到低,还是由低到高:
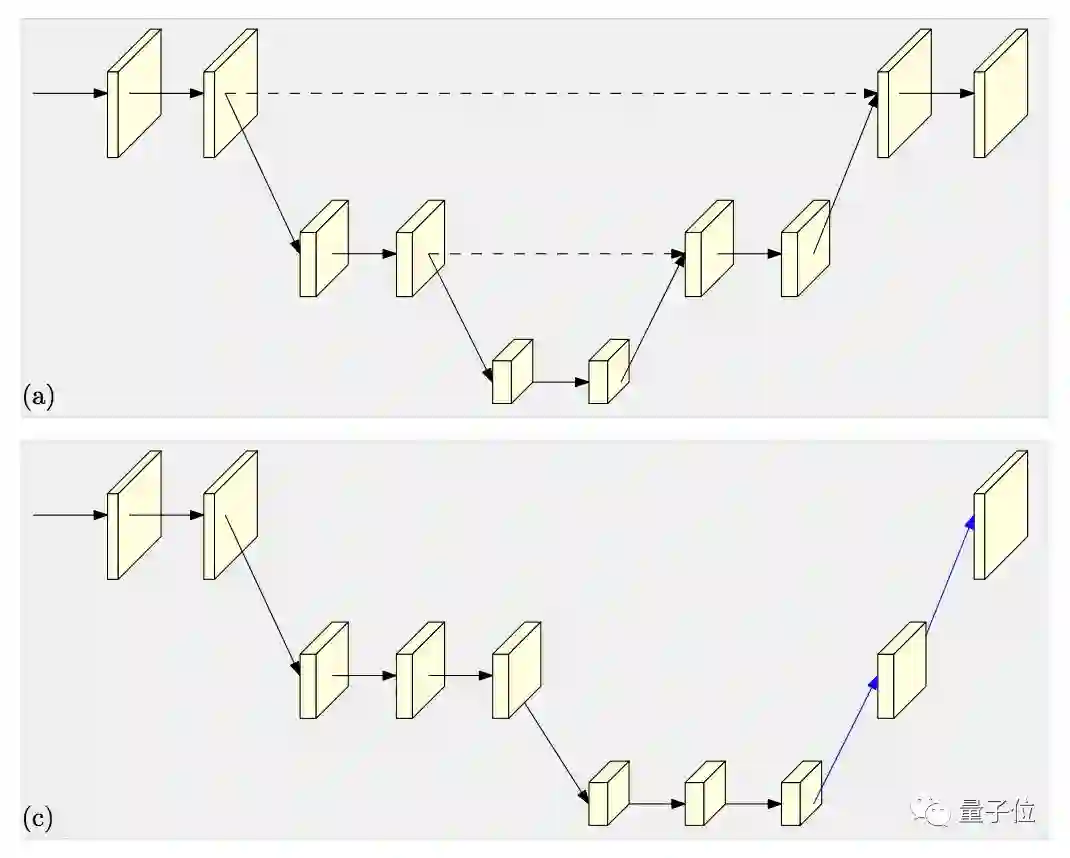
△ 串联
那么,仔细观察一下HRNet的并联网络。
它从一个高分辨率的子网络开始,慢慢加入分辨率由高到低的子网络。
特别之处在于,它不是依赖一个单独的、由低到高的上采样 (Upsampling) 步骤,粗暴地把低层、高层表征聚合到一起;
而是在整个过程中,不停地融合 (Fusion) 各种不同尺度的表征。
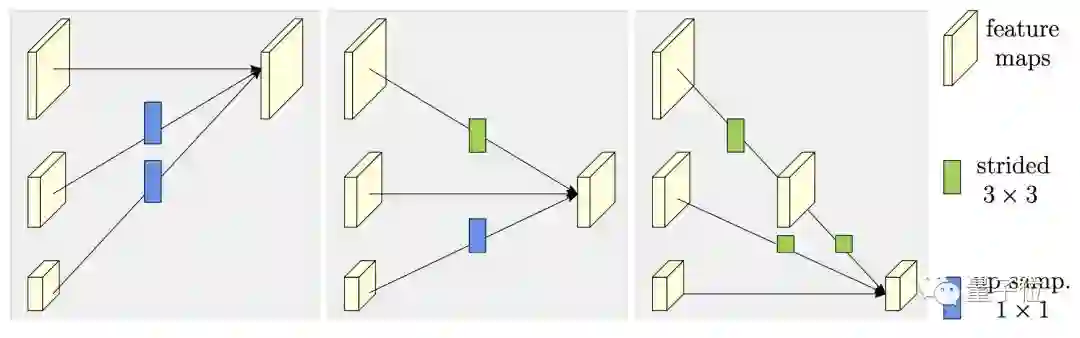
△ 交换单元
这里,团队用了交换单元 (Exchange Units) ,穿梭在不同的子网络之间:让每一个子网络,都能从其他子网络生产的表征里,获得信息。
这样不断进行下去,就能得到丰富的高分辨率表征了。
横扫各大数据集

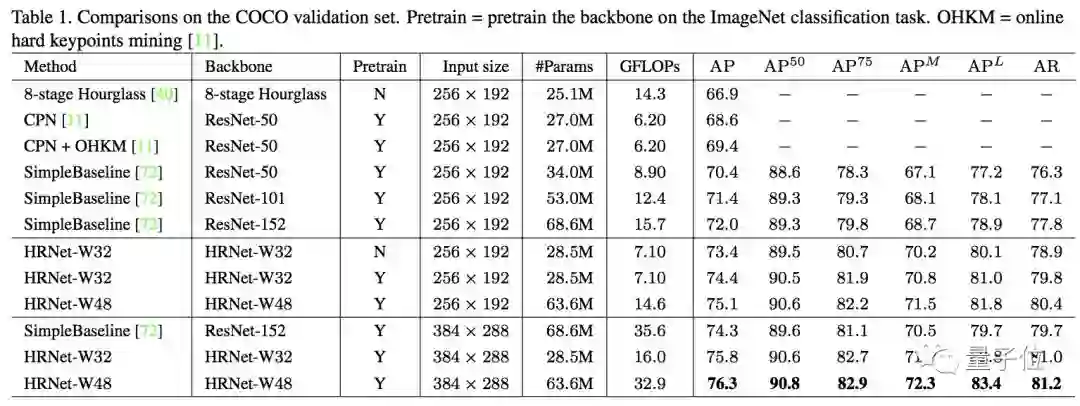
团队先在COCO数据集的val2017验证集上,对比了HRNet和一众前辈的关键点检测表现。
结果是,在两种输入分辨率上,大模型HRNet-W48和小模型HRNet-W32,都刷新了COCO纪录。
其中,大模型在384 x 288的输入分辨率上,拿到了76.3的AP分。
然后,团队又在COCO的test-dev2017测试集上,为HRNet和其他选手举办了姿态估计比赛。
结果,大模型和小模型,也都刷新了COCO纪录。大模型的AP分达到了77.0。
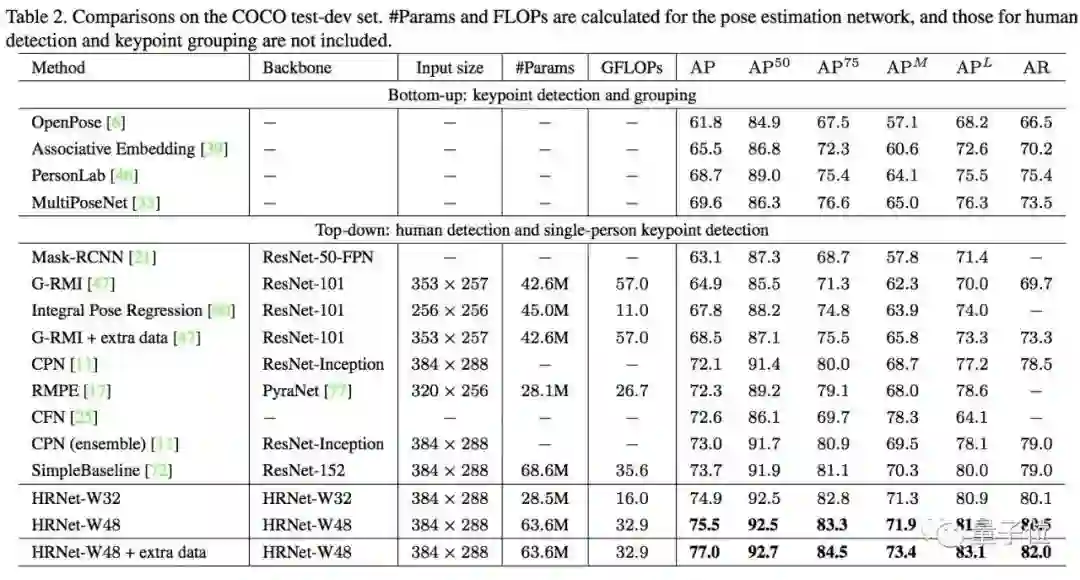
另外,在多人姿态估计任务上,HRNet又超越了前辈们在COCO数据集上的成绩。
那么,其他数据集能难倒它么?
在MPII验证集、PoseTrack、ImageNet验证集上,HRNet的表现都好过所有同台的对手。

详细的成绩表,请从文底传送门前往。
开源啦
刷榜活动圆满结束。
团队把这个振奋人心的模型开了源,是用PyTorch实现的。
除了估计姿势,这个方法也可以做语义分割,人脸对齐,物体检测,等等等等。
所以,你也去试一试吧。
论文传送门:
https://arxiv.org/abs/1902.09212
代码传送门:
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
CVer姿态估计群
扫码添加CVer助手,可申请加入CVer-姿态估计群。一定要备注:姿态估计+地点+学校/公司+昵称

▲长按加群
这么硬的论文速递,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!
