从头了解Gradient Boosting算法
目的
虽然大多数Kaggle竞赛获胜者使用各种模型的叠加/集合,但是一个特定的模式是大部分集合的部分是梯度提升(GBM)算法的一些变体。以最新的Kaggle比赛获胜者为例:Michael Jahrer的解决方案是在安全驾驶的预测中的表示学习。他的解决方案是6个模型的混合。1 个LightGBM(GBM的变体)和5个神经网络。虽然他的成功归因于他为结构化数据发明的新的半监督学习,但梯度提升模型也发挥了作用。
尽管GBM被广泛使用,许多从业人员仍然将其视为复杂的黑盒算法,只是使用预建的库运行模型。这篇文章的目的是为了简化所谓复杂的算法,并帮助读者直观地理解算法。我将解释基本版本的梯度提升算法,并将在最后分享其不同的变体的链接。我已经从fast.ai库(fastai/courses/ml1/lesson3-rf_foundations.ipynb)取得了基本的DecisionTree代码,最重要的是,我建立了自己的简单版本的基本梯度提升模型。
关于Ensemble, Bagging 和 Boosting
的简要描述
当我们试图用任何机器学习技术来预测目标变量时,实际值和预测值的主要差异是噪声,方差和偏差。集成有助于减少这些因素。
一个集合只是一个汇集在一起(例如所有预测的平均值)来作出最终预测的预测器集合。我们使用集成的原因是许多不同的预测变量试图预测相同的目标变量将比任何单一的预测器完成的更好。集成技术进一步分为Bagging和Boosting。
Bagging是一个简单的集成技术,我们建立许多独立的预测变量/模型/学习者,并使用一些模型平均技术将它们结合起来。(例如加权平均数,多数票或正态平均数)。
我们通常对每个模型采用随机的子样本/bootstrap数据,因此所有模型彼此之间几乎没有差别。每个观察结果在所有模型中出现的概率相同。因为这种技术需要许多不相关的学习者做出最终的模型,所以通过减少方差来减少错误。Bagging集成的例子是随机森林模型。
Boosting是一种集成技术,其中预测变量不是独立的,而是按顺序进行的。
这种技术使用了后面的预测变量从之前的预测变量的错误中学习的逻辑。因此,观测值在后续模型中出现的概率是不相同的,而误差最大的出现最频繁。预测变量可以从一系列模型中选择,如决策树,回归量,分类器等等。因为新的预测变量是从以前的预测变量所犯的错误中学习的,所以需要更少的时间/次数来接近实际的预测。但是我们必须慎重选择停机判据,否则可能导致训练数据过度拟合。梯度提升是Boosting算法的一个例子。
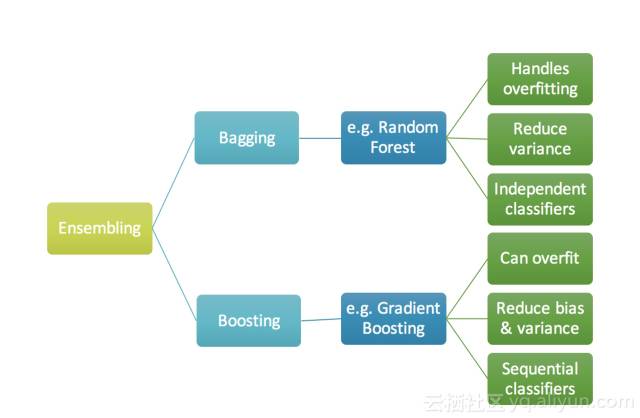
图1.集成
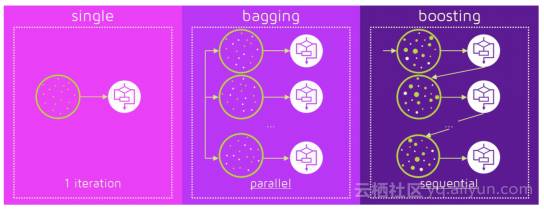
图2. Bagging (独立模式) 和 Boosting (顺序模式).
参考:https://quantdare.com/what-is-the-ding-between-bagging-and-boosting /
梯度提升算法
在维基百科的定义中,梯度提升是一种用于回归和分类问题的机器学习技术,它以弱预测模型(通常是决策树)的集合的形式产生预测模型。
任何监督学习算法的目标是定义一个损失函数,并将其最小化。让我们看看梯度提升算法的数学运算。假设我们将均方根误差(MSE)定义为:

我们希望我们的预测,使我们的损失函数(MSE)最小。 通过使用梯度下降和基于学习速率更新我们的预测,我们可以找到MSE最小的值。
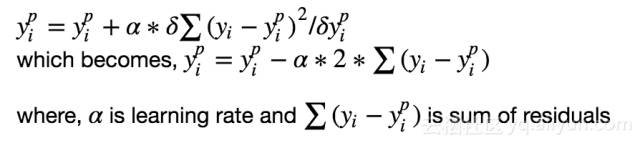
所以,我们基本上是更新预测,使我们的残差总和接近0(或最小),预测值足够接近实际值。
梯度提升背后的直觉
梯度提升背后的逻辑很简单,(可以直观地理解,不使用数学符号)。 我期望任何阅读这篇文章的人都可以熟悉简单的线性回归模型。
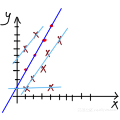
线性回归的一个基本假设是其残差之和为0,即残差应该在0左右随机分布。
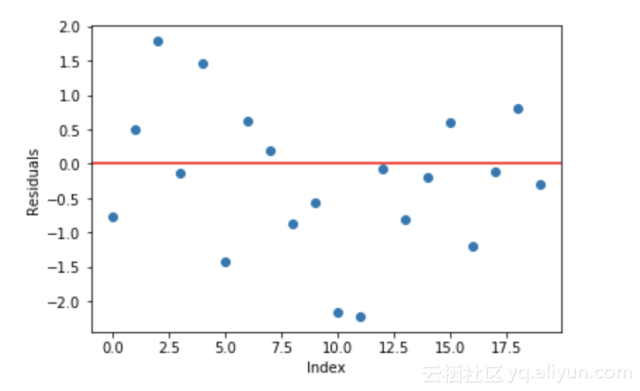
图3.抽样随机正态分布残差均值在0附近
现在把这些残差看作我们的预测模型所犯的错误。虽然基于树的模型(把决策树当作我们梯度提升的基本模型)并不是基于这样的假设,但是如果我们从逻辑上(而不是统计上)考虑这个假设,那么我们可能证明,如果我们能够看到一些残差在0左右的模式,我们可以利用这种模式来拟合模型。
因此,梯度提升算法的直觉就是反复利用残差模式,加强预测能力较弱的模型,使其更好。 一旦我们达到残差没有任何模式可以建模的阶段,我们可以停止建模残差(否则可能导致过度拟合)。 在算法上,我们正在最小化我们的损失函数,使得测试损失达到最小值。
综上所述,
我们首先用简单的模型对数据进行建模,并分析错误的数据。
这些错误通过一个简单的模型来表示数据点是很难的。
那么对于以后的模型,我们特别关注那些难以处理的数据,以使它们正确。
最后,我们通过给每个预测变量赋予一些权重来组合所有的预测变量。
关于同一逻辑的更为技术性的引用写在Probably Approximately Correct: Nature’s Algorithms for Learning and Prospering in a Complex World,“这个想法是多次使用弱的学习方法来获得连续的假设,每一个调整的例子是以往发现困难和错误分类的。...但是,请注意,能做到这一点并不明显”。
拟合梯度提升模型的步骤
让我们思考下面的散点图中显示的模拟数据,其中1个输入(x)和1个输出(y)变量。
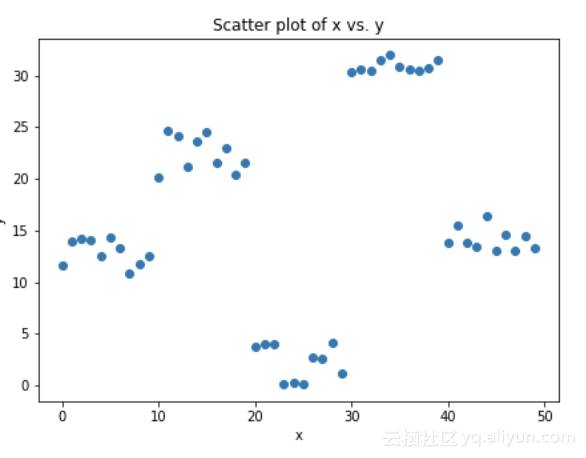
图4.模拟数据(x:输入,y:输出)
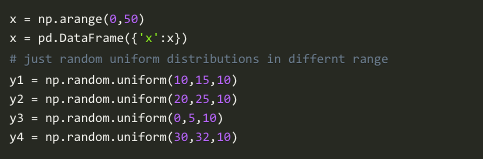
上面显示的图的数据是使用下面的python代码生成的:
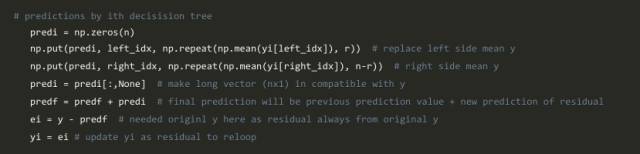
1、对数据拟合一个简单的线性回归或决策树(我在我的代码中选择了决策树)[将x作为输入,将y作为输出]
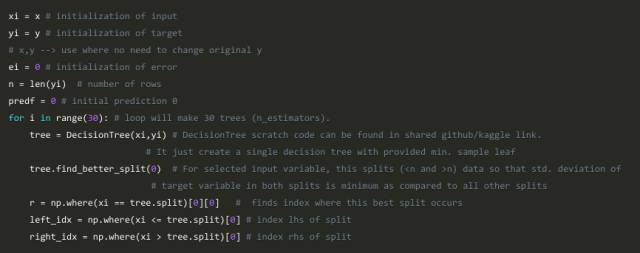
2、计算误差残差。实际目标值减去预测目标值[e1 = y_predicted1 - y]
3、将误差残差的新模型作为具有相同输入变量的目标变量[称为e1_predicted]
4、将预测的残差添加到先前的预测中[y_predicted2 = y_predicted1 + e1_predicted]
5、在剩余的残差上拟合另一个模型。即[e2 = y-y_predicted2]并重复步骤2到5,直到它开始过拟合或残差总和变成恒定。过度拟合可以通过持续检查验证数据的准确性来控制。
为了帮助理解基本概念,下面是从零开始完整实现简单梯度提升模型的链接。
https://www.kaggle.com/grroverpr/gradient-boosting-simplified/?spm=5176.100239.blogcont304535.17.OodOmp
共享代码是一种非优化的梯度提升的普通实现。库中的大多数梯度提升模型都经过了很好的优化,并且有很多超参数。
工作梯度提升树的可视化
蓝点(左)是输入(x)与输出(y)的关系•红线(左)显示由决策树预测的值•绿点(右)显示第i次迭代的残差与输入(x)•迭代表示拟合梯度提升树的顺序。
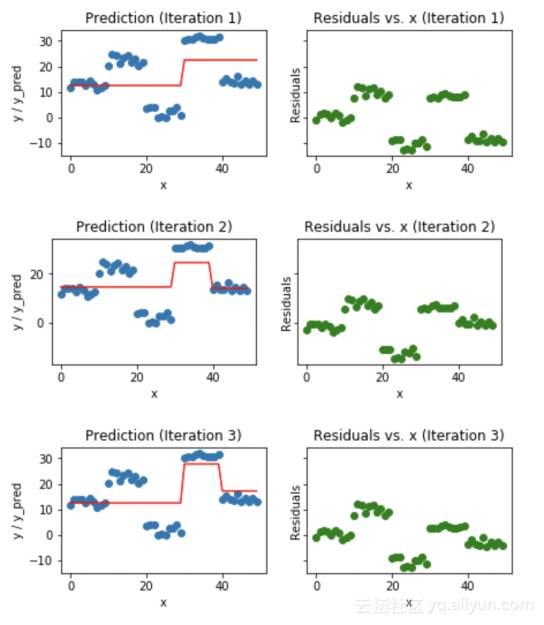
图5.梯度提升预测的可视化(前4次迭代)
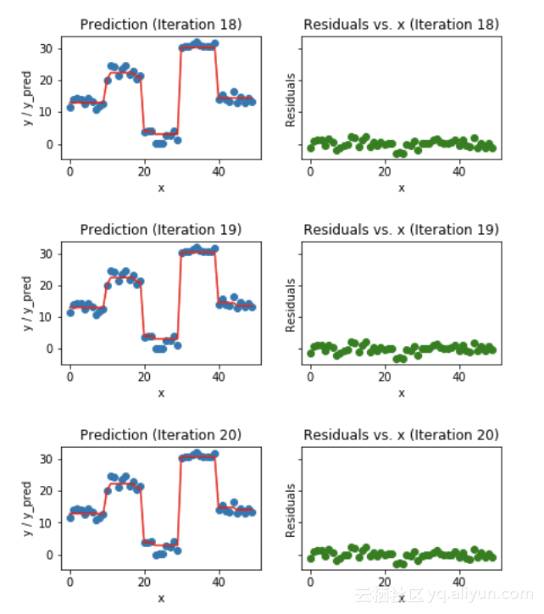
图6.梯度提升预测的可视化(第18次至第20次迭代)
我们观察到,在第20次迭代之后,残差在0附近是随机分布的(我并不是说随机的正态分布),我们的预测非常接近真实值。(迭代在sklearn实现中被称为n_estimators)。这将是一个很好的点来停止或开始过度拟合模型。
让我们看看我们的模型在第五十次迭代中的样子。
我们可以看到,即使在第50次迭代之后,残差对x的曲线看起来也与我们在第20次迭代中看到的相似。 但是,模型变得越来越复杂,预测过度的训练数据,并试图学习每个训练数据。 所以,最好是停止在第20次迭代。
用于绘制所有上述数据的Python代码片段:
更多有用的资源
1.我的github repo和关于从头开始GBM的kaggle核心链接:
https://www.kaggle.com/grroverpr/gradient-boosting-simplified/
https://github.com/groverpr/Intro-to-Machine-Learning/blob/master/algo_scratch/gradient%20boosting%20from%20scratch.ipynb
2.关于从头开始决策树的Fast.ai github repo链接(Massive
ML / DL相关资源):
https://github.com/fastai/fastai
3. Alexander Ihler的视频。这个视频真的帮助我了理解梯度提升算法。
4. 一位Kaggle专家解释梯度提升:本戈曼
http://blog.kaggle.com/2017/01/23/a-kaggle-master-explains-gradient-boosting/
5.广泛使用的GBM算法:
XGBoost || Lightgbm|| Catboost ||
sklearn.ensemble.GradientBoostingClassiber
作者及译者信息
Prince Grover,南佛罗里达大学数据科学硕士学生,Manifold.ai数据科学实习生。
本文由阿里云云栖社区组织翻译。文章原标题《Gradient Boosting from scratch》作者:Prince Grover 译者:董昭男 审核:海棠
往期精彩文章
-END-

云栖社区
ID:yunqiinsight
云计算丨互联网架构丨大数据丨机器学习丨运维