赛尔推荐 | 第8期
该栏目每周将推荐若干篇由师生精心挑选的前沿论文,分周三、周五两次推送。
本次推荐了关于自然语言推理、文本蕴含识别、句子表示、文本摘要、序列标注、数据稀疏、多任务学习的四篇论文。
1
推荐组:QA
推荐人:赵得志(研究方向:文本蕴含,问答系统)
论文题目:Enhanced LSTM for Natural Language Inference
作者:Qian Chen, Xiaodan Zhu, Zhenhua Ling, Si Wei, Hui Jiang, Diana Inkpen
出处:ACL 2017
论文主要相关:自然语言推理,文本蕴含识别
简评:这篇文章发表于ACL2017,主要研究领域为自然语言推理(文本蕴含识别),在SNLI数据集上达到了目前已发表论文中最好的结果。文章中提出了名为ESIM的模型,该模型采用了BiLSTM编码、经典attention机制实现软对齐、启发式增强局部推理信息、BiLSTM再编码以及启发式Pooling的方式实现推理关系的判断,仅ESIM模型就已经达到了测试集上的最好结果。同时考虑到句法信息对判断推理关系的影响,采用句法树作为输入并使用Tree-LSTM进行编码另训练模型,并通过平均预测概率的方式整合到ESIM中,可进一步提升整体模型的性能。
在文章中可以看到很多之前提出的模型与方法的影子:ESIM基本借鉴了Decomposable Attention Model的框架;借鉴了基于句子编码方法的拼接、求差、按维度相乘等启发式方法来构建更全面的局部推理信息;借鉴了基于递归神经网络方法的思想并采用Tree-LSTM进一步提高模型的效果等等。然而作者并不是简单地堆叠模型,而是借鉴了各个方法的合理内核(实验方面的切除分析证明了各个部分对模型的作用),着眼于细致地构建序列化的推理网络(循环神经网络)而不是把模型复杂化(在本文之前出现了认为循环神经网络无法在SNLI上建模句子的复杂结构的观点,且基于递归神经网络构建了复杂的模型并取得了当时最好的结果),以单纯的序列化推理模型取得了超过复杂模型的最好结果,也证明了序列推理模型还有潜力被继续挖掘。
除模型本身的贡献外,作者这种不被最好模型结果所影响,坚持把已有的有价值的问题做得更深入的研究思路,以及不盲目地复杂化模型,而是找出现有模型的问题再充分提高的思想,值得我们学习和借鉴。
论文链接:
https://aclweb.org/anthology/P/P17/P17-1152.pdf
源代码链接:
https://github.com/lukecq1231/nli
2
推荐组:RC
推荐人:朱海潮(研究方向:篇章分析、问答)
论文题目:Learning General Purpose Distributed Sentence Representations via Large Scale Multitask Learning
作者:Sandeep Subramanian, Adam Trischler, Yoshua Bengio, Christopher J Pal
出处:ICLR 2018
论文主要相关:句子表示,多任务学习
简评:词的分布式向量表示对众多自然语言处理任务的成功起着至关重要的作用,这些表示通常采用无监督的方式从大规模文本中学习得到。这篇文章将词的向量表示进一步扩展到句子的向量表示,提出了一种简单、有效的多任务学习框架来得到通用的句子表示,综合考虑神经机器翻译(NMT)、成分句法分析(Constituency Parsing)、自然语言推理(NLI)和Skip-thought vectors的训练目标所隐含的归纳偏置到一个单独模型中。具体地,所有任务共用一个RNN句子编码器,将编码器最后一个时刻的隐含层状态作为句子的表示![]() ,同时,为了得到一个单一、固定维度的句子分布式表示,框架并没和一般的seq2seq框架一样采用attention机制,而是将
,同时,为了得到一个单一、固定维度的句子分布式表示,框架并没和一般的seq2seq框架一样采用attention机制,而是将![]() 引入到解码器GRU单元的内部计算中。在训练时,这篇文章使用了一种更为简单的任务轮换机制,模型每更新一次参数,根据一定概率随机选择一个任务进行下一次参数更新。
引入到解码器GRU单元的内部计算中。在训练时,这篇文章使用了一种更为简单的任务轮换机制,模型每更新一次参数,根据一定概率随机选择一个任务进行下一次参数更新。
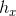 ,同时,为了得到一个单一、固定维度的句子分布式表示,框架并没和一般的seq2seq框架一样采用attention机制,而是将
,同时,为了得到一个单一、固定维度的句子分布式表示,框架并没和一般的seq2seq框架一样采用attention机制,而是将为了评估得到的句子表示,作者将得到的表示作为特征,在新的任务或领域上训练一个简单的分类器(训练时不更新编码器参数),同时也评价了只有少量训练数据时句子表示的作用。另外,作者也对训练模型时得到的词向量表示进行了评价。最后,实验表明,基于多任务学习框架得到的句子表示取得比先前通用的句子表示相比更好的结果。
论文链接:
https://openreview.net/pdf?id=B18WgG-CZ
源代码链接:
https://github.com/Maluuba/gensen(后续放出)
3
推荐组:CR
推荐人:李凌志(研究方向:人机对话)
论文题目:A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents
作者:Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, Nazli Goharian†
出处:NAACL 2018
论文主要相关:文本摘要
简评:目前文本摘要领域的热点和方法比较集中在短文本摘要,这篇文章提出了一种建模规范长文本摘要的有效方案,使用层次化编码器(hierarchical encoder)建模长文本段落内和段落间的论述信息,然后使用与论述过程相关的注意力解码器(attentive discourse-aware decoder)进行解码,生成文本摘要。文章中给出了ArXiv和PubMed两个处理后的论文数据集,并与三种抽取式方法和当前最好的生成式方法进行对比实验,实验结果表明,该方案显著超过了当前最好的生成式文本摘要方法。文章中模型创新性并不十分显著,但考虑到建模文本论述规律对于生成摘要的有效提升作用,这一点可以借鉴到其他工作。此外,文章开源了相关数据集,文中提出的方法可以作为日后规范长文本生成式摘要的基线方法。
论文链接:
https://128.84.21.199/pdf/1804.05685.pdf
源代码链接:
https://github.com/acohan/long-summarization
4
推荐组:SA
推荐人:傅科达(研究方向:情感分析)
论文题目:Semi-supervised Multitask Learning for Sequence Labeling
论文作者:Marek Rei【University of Cambridge】
出处:ACL 2017
论文主要相关:序列标注,数据稀疏,多任务学习
简评:序列标注模型通常由字符的标签学习特征,但数据集里面的相关标签很少,比如(无关标签占90%,有关标签占10%),标签容易被识别成无关标签。
文章中提出的主要方法如下:1) Neural sequence Labeling:将输入的句子分词,通过双向lstm分别用前后2个时间节点的隐藏层状态和当前时间节点的词向量作为输入,得到每一个词获取一个基于上下文的表示,之后通过非线性变换以及softmax,输出标签。2)Language Modeling Objective:之前的模型是对于正确的标签做的优化,但是忽略了其他标签的作用。为了解决这个标签数据稀疏的问题,引入语言模型,即在原有的预测当前单词的标签任务上,再加一个任务——预测前后词。前向的lstm预测后一个单词,后向的lstm预测前一个单词,从而让模型学习更多语义和句法成分,提高预测标签的准确率。
实验结果方面,1)在error detection上,即系统需要测出哪个字符标记错误,该数据集的特点是标签很少,错误的标签很分散。加了语言模型之后,P,R,F值均提高2个点以上。2)在NER和Chunking数据集任务上,在CoNLL-00,CoNLL-03,CHEMDNER上,加了语言模型,均领先baseline1个点以上。3)Pos Tagging任务中,在这些数据集上,baseline性能已经几乎达到0.972,所以加了语言模型提升0.002,不是十分显著。由实验结果可得出以下结论,在各个数据集中,加入语言模型的模型性能几乎都使准确率得到了提升,可见这样的修改对标签数据稀疏是有一定成效的,可以学到更多特征。
论文链接:
https://arxiv.org/pdf/1704.07156.pdf
源代码链接:
https://github.com/marekrei/sequence-labeler
往期链接:
点击文末“阅读原文”即可查看完整赛尔推荐目录
(词向量、RNN计算复杂性、事件检测、推敲网络、编码器-解码器、序列生成)
(语言模型、对话生成、情感因素、任务型对话、用户模拟、问答系统)
(推荐系统、情感分析、序列生成)
(自动文摘技术、自动文摘评价、自然语言推理、阅读理解和文本风格迁移)
本期责任编辑: 赵森栋
本期编辑: HFL编辑部
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。



