PostgreSQL查询优化器详解(物理优化篇)

作者介绍
张树杰,《PostgreSQL技术内幕:查询优化深度探索》作者,目前在Pivotal公司任职Apache HAWQ数据库内核开发工程师,具有多年数据库内核开发经验。
继《PostgreSQL查询优化器详解(逻辑优化篇)》,本文将另以物理优化角度,继续深入PostgreSQL数据库查询优化器的细枝末节。为了让大家通过通俗易懂的方式更好地理解消化其中的晦涩概念,作者别出心裁地撰写成趣味故事,虽然篇幅稍长,但细细品读定将收获匪浅。
“咚咚咚……”门外传来了敲门声,大明打开门一看,原来是同事牛二哥。牛二哥是专门从事数据库查询优化开发的码农,也有十几年从业经验了,大明感到非常happy,因为这两天给小明讲查询优化器讲得有些吃力,今天牛二哥来了正好可以帮上忙:“牛二同志,我弟弟小明最近学校要做数据库原理实践,总来问我优化器的问题,可我对优化器也是一知半解,这下你来了可以帮帮忙不?”
牛二哥痛快地说:“这难不倒我,随时都可以讲。”
小明对牛二哥早有耳闻,接到大明电话后速速赶到,见面不久便吐起了苦水:“我最近正在查看基于代价的优化,感觉付出了很多代价,但收获甚微,期望今天能得到牛二哥的指导。”
牛二哥说:“说到代价,我觉得有个东西是绕不过去的,就是统计信息和选择率,PostgreSQL的物理优化需要计算各种物理路径的代价,而代价估算的过程严重依赖于数据库的统计信息,统计信息是否能准确地描述表中的数据分布情况是决定代价准确性的重要条件之一。”
小明说:“大明和我说过,数据库有很多物理路径,这些物理路径也叫物理算子。和逻辑算子不同,物理算子是查询执行器的执行方法,我们只需要计算物理算子每个步骤的代价,汇总起来就是路径的代价了,那要统计信息有什么用呢?”
牛二哥说:“是的,我们就是要计算一个物理算子的代价,但是物理算子的计算量并不是一成不变的。”说着他从旁边的书桌上拿来纸和笔,写了两个SQL语句。
SELECT A+B FROM TEST_A WHERE A > 1;
SELECT A+B FROM TEST_A WHERE A > 100000000;
然后说:“你看,这两个语句可以用同样的物理算子来完成,但是他们的计算量一样的吗?”
小明心想:A > 1和A > 1000000000都是过滤条件,经过过滤之后,他们产生的数据量就不同了,这样投影中的A+B的计算次数就不同了,所以它们的代价应该是不同的,那它和统计信息有什么关系呢?小明灵光一闪,马上说:“我知道了,我在计算物理算子的代价的时候,要知道A > 1之后还剩下多少数据或者A > 1000000000之后还剩下多少数据,如果我们提前对表上的数据内容做了统计,剩下多少数据就不难计算了,所以必须要有统计信息。”
牛二哥点了点头说:“嗯,通过统计信息,代价估算系统就可以了解一个表有多少行数据、用了多少个数据页面、某个值出现的频率等等,然后就能根据这些信息计算出一个约束条件能过滤掉多少数据,这种约束条件过滤出的数据占总数据量的比例称之为‘选择率’,所谓选择率就是一个比例,它的公式是这样的。”说着牛二哥继续在纸上写下了选择率的公式:
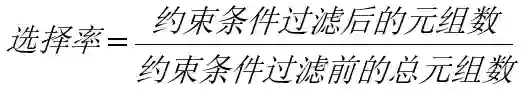
“不过上面的示例有点简单了,实际应用中通常约束条件会比较多,而且比较复杂,通常我们会计算每个子约束条件的选择率,然后就可以根据AND运算符和OR运算符计算它们的综合的选择率,AND运算符和OR运算符的选择率计算是基于概率的,你看这里的概率公式。”说着,牛二哥又继续在纸上写了起来。
P(A+B)=P(A)+P(B)-P(AB)
P(AB)=P(A)×P(B)
“有了这些,我们就可以求解多种类型的约束条件的选择率了,比如……”牛二哥继续写出:
P(ssex IS NOT NULL OR sno > 5)
= P(ssex IS NOT NULL) + P(sno > 5) – P(ssex IS NOT NULL AND sno > 5)
= P(ssex IS NOT NULL) + P(sno > 5) – P(ssex IS NOT NULL) × P(no > 5)
小明觉得牛二哥讲解的进展有点快,赶紧问:“那么统计信息是什么形式的呢?”
牛二哥挠挠头说:“这个还真是有点麻烦,我们说常用的统计信息的形式就是distinct率、NULL值率、高频值、直方图、相关系数这些,它们分别有不同的作用。比如说distinct率,你可以获知某一列有多少个独立值,这种信息对于像性别这种列就显得特别有用。NULL值率呢,在统计的过程中,NULL值是不好处理的,因此把它独立出来,形成NULL值率,这样在高频值、直方图这些里面就不用考虑NULL值的情况了。高频值属于奇异值,顾名思义,就是出现得比较多的一些列值。去掉了NULL值,再去掉高频值,剩下的值可以用来做一个等频的直方图。”
大明看小明有点跟不上,过来说:“统计信息嘛,主要的还是高频值、直方图和相关系数,实际上我建议还是不要纠结于统计信息有哪些形式,只要知道它是用来算代价的就可以了。”
牛二哥对大明说:“这怎么可以,我还没有说统计信息是如何生成的呢,比如它通过了两阶段采样,然后对样本进行统计时使用的统计方法,哪些值可以作为高频值,直方图有几个桶,相关系数是怎么计算的,相关系数在计算索引扫描路径代价的时候怎么用的……而且我和你说,PostgreSQL还出了基于多列的扩展统计信息,多列统计信息分成了哪些类型,分别是什么含义,各自是怎么计算的,还有选择率是怎么结合统计信息计算的,这些我还没说呢……”
大明忍不住说:“像你这样讲优化器,岂不是要出一本书了?”
牛二哥做痛苦状:“那好吧,统计信息我们就说到这里,但是它确实是代价计算的基石,小明同学,你理解了它的作用就可以了。”
大明继续神秘地说:“实际上统计信息往往也不准,你想想本来就是采样的结果嘛,样本是否显著压根就不好说,而且随着应用程序对表的更新,统计信息可能更新不及时,那就更会出现偏差。更严重的是,如果我们遇到a > b这样的约束条件,使用统计信息计算选择率也很不好计算,即使算出来,也不准嘛。”
牛二哥说:“是的,统计信息确实也有不准确的问题。我听说有个DBA,他家后院出了一口泉水,他爸爸觉得是吉兆,去找风水大师看。风水大师掐指一算说:你儿子是个DBA,每次数据库性能慢就知道更新统计信息,可是统计信息太水了,都从你家后院冒出来了。”
三个人顿时笑做一团。
玩笑过后,小明说:“不如给我说说物理路径吧,我们代价算来算去,最终还是为了物理路径计算代价嘛。大明和我说过它大体分成扫描路径和连接路径,我查过一些说明,知道扫描路径有顺序扫描路径、索引扫描路径、位图扫描路径等等;而连接路径通常有嵌套循环连接路径、哈希连接路径、归并连接路径,另外还有一些其他的路径,比如排序路径、物化路径等等。”
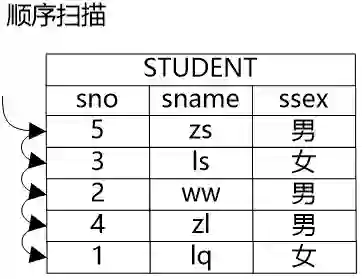
牛二哥说:“是的,我们就来说说这些路径的含义吧。如果要获得一个表中的数据,最基础的方法就是将表中的所有的数据都遍历一遍,从中挑选出符合条件的数据,这种方式就是顺序扫描路径。顺序扫描路径的优点是具有广泛的适用性,各种表都可以用这种方法,缺点自然是代价通常比较高,因为要把所有的数据都遍历一遍。”大明同时在纸上画了个图,说:“这个图大概就是顺序扫描路径。”
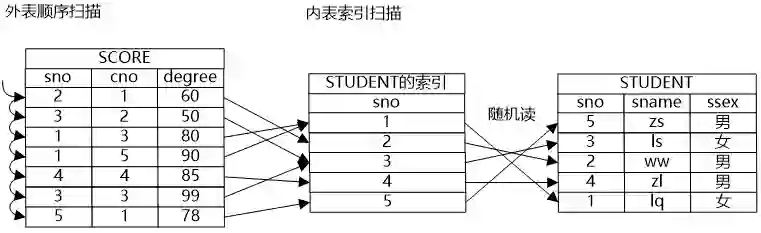
牛二哥则继续说:“如果将数据做一些预处理,比如建立一个索引,如果要想获得一个表的数据,可以通过扫描索引获得所需数据的‘地址’,然后通过地址将需要的数据获取出来。尤其是在选择操作带有约束条件的情况下,在索引和约束条件共同的作用下,表中有些数据就不用再遍历了,因为通过索引就很容易知道这些数据是不符合约束条件的,更有甚者,因为索引上也保存了数据,它的数据和关系中的数据是一致的,因此如果索引上的数据就能满足要求,只需要扫描索引就可以获得所需数据了,也就是说在扫描路径中还可以有索引扫描路径和快速索引扫描路径两种方式。”
大明则继续为牛二哥“捧哏”,在纸上画出了索引扫描和快速索引扫描的图。
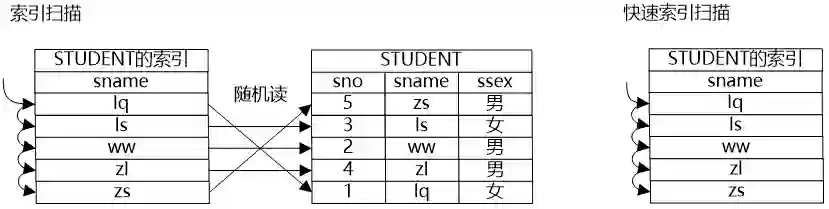
小明看到图上写了“随机读”三个字,问道:“我看这个索引扫描有随机读的问题,这个问题能否解决掉呢?也就是说即利用了索引,还避免了随机读的问题,有这样的办法吗?”
牛二哥说:“索引扫描路径确实带来随机读的问题,因为索引中记录的是数据元组的地址,索引扫描是通过扫描索引获得元组地址,然后通过元组地址访问数据,索引中保存的“有序”的地址,到数据中就可能是随机的了。位图扫描就能解决这个问题,它通过位图将地址保存起来,把地址收集起来之后,然后让地址变得有序,这样就通过中间的位图把随机读消解掉了。”大明则继续在纸上画出了位图扫描的示意图。
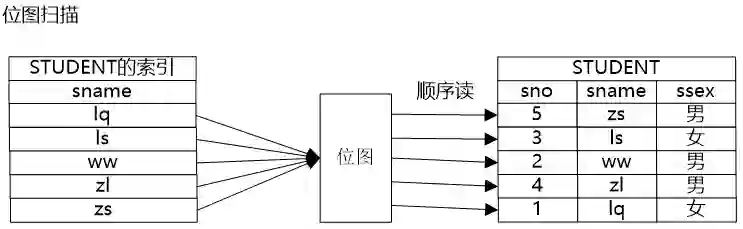
大明补充说道:“扫描过程中还会结合一些特殊的情况有一些非常高效的扫描路径,比如TID扫描路径,TID实际上是元组在磁盘上的存储地址,我们能够根据TID直接就获得元组,这样查询效率就非常高了。”
牛二哥点了点头继续说:“扫描路径通常是执行计划中的叶子结点,也就是在最底层对表进行扫描的结点,扫描路径就是为连接路径做准备的,扫描出来的数据就可以给连接路径来实现连接操作了。”
大明一边在纸上画一边说:“要对两个关系做连接,受笛卡尔积的启发,可以用一个算法复杂度是O(mn)的方法来实现,我们叫它Nestlooped Join方法。这种方法虽然复杂度比较高,但是和顺序扫描一样,胜在具有普适性。”
牛二哥说:“嵌套循环连接这种方法的复杂度比较高,看上去没什么意义,但是如果Nestlooped Join的内表的路径是一个索引扫描路径,那么算法的复杂度就会降下来。索引扫描的算法复杂度是O(logn),因此如果Nestlooped Join的内表是一个索引扫描,它的整体的算法复杂度就变成了O(mlogn),看上去这样也是可以接受的。”
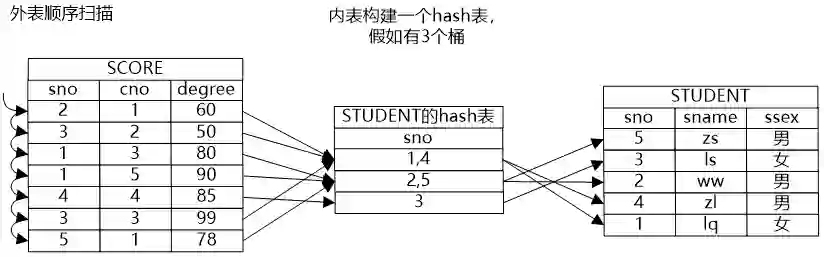
小明点了点头说:“嗯,索引实际上是对数据做了一些预处理,我想如果哈希连接方法就是将内表做一个哈希表,这样也等于将内表的数据做了预处理,也能方便外表的元组在里面探测吧?”
牛二哥点了点头说:“假设Hash表有N个桶,内表数据均匀的分布在各个桶中,那么Hash Join的时间复杂度就是O(m * n /N),当然,这里我们没有考虑上建立Hash表的代价。”
大明则在纸上画出了Hash连接的示意图,并补充道:“Hash连接通常只能用来做等值判断。”
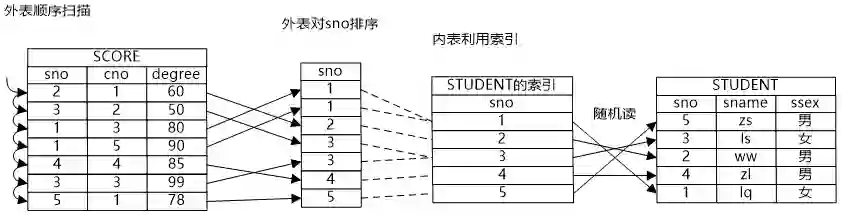
牛二哥继续说:“如果将两个表先排序,那么就可以引入第三种连接方式,Merge Join。这种连接方式的代价主要浪费在排序上,如果两个关系的数据量都比较小,那么排序的代价是可控的,MergeJoin就是适用的。另外如果关系上有有序的索引,那就可以不用单独排序了,这样也比较适用于MergeJoin。你看我画的这个归并连接的示意图,外表是需要排序的,而内表则借用了原有的索引的顺序,消除了排序的时间,降低了物理路径的代价。”
“这些路径属于SPJ路径,在PostgreSQL的优化器中,通常会先生成SPJ的路径,然后在这基础上再叠加Non-SPJ的路径,比如说聚集操作、排序操作、limit操作、分组操作……”牛二哥继续补充道。
小明说:“可是算来算去,物理路径的代价还是有选不准的时候啊。”
牛二哥说:“最优路径选得不准是谁的原因?那就是代价模型不行啊。代价模型不行赖谁?那就是程序员没建好啊,所以要怪就怪到程序员自己头上。”
小明问道:“可是我看PostgreSQL的代价计算已经很复杂了啊。”
“但数据库的周边环境更复杂啊。你想想,在实际应用中,数据库用户的配置硬件环境千差万别,CPU的频率、主存的大小和磁盘介质的性质都会影响执行计划在实际执行时的效率。”牛二哥说。
大明接过来继续说道;“虽然在代价估算的过程中,我们无法获得‘绝对真实’的代价,但是‘绝对真实’的代价也是不必要的。因为我们只是想从多个路径(Path)中找到一个代价最小的路径,只要这些路径的代价是可以‘相互比较’的就可以了。因此可以设定一个‘相对’的代价的单位1,同一个查询中所有的物理路径都基于这个“相对”的单位1来计算的代价,这样计算出来的代价就是可以比较的,也就能用来对路径进行挑选了。”
牛二哥接着说:“PostgreSQL采用顺序读写一个页面的IO代价作为单位1,而把随机IO定为了顺序IO的4倍。”
小明说:“我知道,这个我查过相关的书。首先,目前的存储介质很大部分仍然是机械硬盘,机械硬盘的磁头在获得数据库的时候需要付出寻道时间。如果要读写的是一串在磁盘上连续的数据,就可以节省寻道时间,提高IO性能。而如果随机读写磁盘上任意扇区的数据,那么会有大量的时间浪费在寻道上。其次,大部分磁盘本身带有缓存,这就形成了主存→磁盘缓存→磁盘的三级结构。在将磁盘的内容加载到内存的时候,考虑到磁盘的IO性能,磁盘会进行数据的预读,把预读到的数据保存在磁盘的缓存中。也就是说如果用户只打算从磁盘读取100个字节的数据,那么磁盘可能会连续地读取磁盘中的512字节(不同的磁盘预读的数量可能不同)并将其保存到磁盘缓存。如果下一次是顺序读取100个字节之后的内容,那么预读的512字节的数据就会发挥作用,性能会大大的增加。而如果读取的内容超出了512字节的范围,那么预读的数据就没有发挥作用,磁盘的IO性能就会下降。”说完小明得意地说:“怎么样,我说得对吧?”
牛二哥说:“你说得对,目前PostgreSQL的查询优化大量的考虑了随机IO和顺序IO所带来的性能差别,在这方面做了不少优化。但是现在的磁盘技术越来越发达了,以后随机IO和顺序IO是不是还差这么多,就值得商榷了。”
“那到底还有哪些代价基准单位呢?”小明继续问道。
大明回答:“基于磁盘IO的代价单位当然就是和Page有关的了,也就是说我们刚才说的顺序IO和随机IO都属于IO方面的基准代价。让牛二哥给你介绍一下CPU方面的代价基准单位吧。”
牛二哥说:“CPU方面的基准单位有哪些呢?比如说我们通过IO把磁盘页面读到了缓存,但我们要处理的是元组啊,所以还需要把元组从页面里解出来,还要处理元组,这部分主要消耗的是CPU,所以会有一个元组处理的代价基准单位。另外,我们在投影、约束条件里有大量的表达式,这些表达式求解也主要消耗CPU资源,所以还有一个表达式代价的基准单位。”
牛二哥继续说道:“现在PostgreSQL增加了很多并行路径,因此它也产生了通信代价,这个也需要计算的。”
小明听后说:“那我们就能得到一个这样的公式。”说着在纸上写了一个公式:
总代价 = CPU代价 + IO代价 + 通信代价
然后继续说:“可是我通过EXPLAIN还查看过PostgreSQL的执行计划,从执行计划中还看到有启动代价和总代价,这是怎么回事呢?”
牛二哥想了想,在纸上写了一个公式:
总代价 = 启动代价 + 执行代价
然后说:“这是从另一个角度来计算代价,启动代价是指从语句开始执行到查询引擎返回第一条元组的代价(另一种说法是准备好去获得第一条元组的代价),总代价是SQL语句从开始执行到结束的所有代价。”
“可是……为什么要区分启动代价和执行代价呢?”
“这个嘛……”牛二哥思考了一下,觉得一两句话不容易说清楚,于是写了个例子:
SELECT * FROM TEST_A WHERE a > 1 ORDER BY a LIMIT 1;
“我们假设这个在TEST_A(a)上有一个B树索引,晓得不,那这个语句可能会形成什么样的执行计划呢?”
小明想了想,觉得空想可能有点困难,于是在纸上画了一下,最终画出了两个执行路径:
执行路径1:LIMIT 1
-> SORT(a)
-> SeqScan WHERE A > 1;
执行路径2:LIMIT 1
-> IndexScan WHERE A > 1;
(小明注:B树索引有序,不用再排序了)
小明说:“我觉得这两个都可以,不过第二个更好,因为节省了排序的时间。”
牛二哥问:“你知道的,PostgreSQL采用动态规划的方法来实现路径的搜索,它是一种自底向上的方法,也就是说会先建立筛选扫描路径,然后用筛选后的扫描路径再去形成连接路径。那么在我们筛选扫描路径的时候,是不知道它的上层有没有LIMIT的,这时候如果单独看SeqScan + SORT和IndexScan你觉得哪个好呢?”
“嗯,我知道陷阱在哪里,大明和我说过,A > 1的选择率高的话会选择顺序扫描,而A > 1的选择率低的情况下,会选择索引扫描。这是因为索引扫描会产生随机IO,也就是说在选择率高的情况下,有可能SeqScan + SORT会优于IndexScan。虽然SeqScan + SORT会有排序,但是IndexScan的随机IO实在是太可观了。”
牛二哥点了点头说:“对的,假设选择率比较高,这时选择了SeqScan + SORT,是因为它不知道再上层是LIMIT 1。如果上面是LIMIT 1,就会导致索引扫描不用全部扫完,只要扫一丢丢就可以了。这时随机IO就很小了,但是SeqScan + SORT就还必须全部执行完才能获取到LIMIT 1,也就是说SeqScan + SORT、或者说SORT要获取第一条元组的启动代价是比较高的。如果上面有LIMIT 1这样的子句,那么启动代价高的路径可能就没有优势了,这就是启动代价的作用。”
小明恍然大悟地说:“SORT要全部做完才能获取第一条元组,它的启动代价大,但是总代价小。而索引扫描呢,因为本身有序,它的启动代价是小的,但是由于有随机IO,所以它的总代价是大的。如果我们只按照总代价进行筛选,就没办法获得最优的代价了。”
“什么什么?启动代价……你们进展很快嘛。”这时大明跑过来说:“让我们想一下晚上吃点什么吧?”
小明:“吃点好的,很有必要。我这脑细胞已经快用没了。”
小明、大明和牛二哥在外卖APP里搜索附近的饭店,大明突然感叹道:“看,这就是蓝海,我们可以创业搞一个AI点评,只能推荐最优的饭店啊,我准确地找到了吃货们的痛点,这里面隐含着很大的商机啊!”
牛二哥瞥了他一眼说:“AI推荐当然好,可是要推荐得准才行啊。一个人一个口味,你这个需求太‘智能’了,我估计不好弄。”
小明突然说:“我最近在算法课上学过一些最优解问题的解决方法,应该能用得上。”
牛二哥叹口气说:“可是这些方法用到优化器里都不一定够用,何况用到一个更加智能的项目上呢?”
“嗯?优化器里也用到最优解问题的方法了吗?我们学过动态规划、贪心算法……”小明如数家珍地说起来。
大明说:“用到了啊, 虽然物理路径看上去也不多,但实际上枚举起来,它的搜索空间也不小。例如在扫描路径中,我们就可以有顺序扫描、索引扫描和位图扫描。假如一个表上有多个索引,就可能产生多个不同的索引扫描,那么哪个索引扫描路径好呢?还有索引扫描和顺序扫描、位图扫描相比,哪个好呢?”
大明看着小明迷离的眼神后继续说:“数据库路径的搜索方法通常有3种类型:自底向上方法、自顶向下方法、随机方法,而PostgreSQL采用了其中的两种方法。”
“采用了哪两种方法?”牛二哥明知故问。
“采用了自底向上和随机方法,其中自底向上的方法是采用动态规划方法,而随机方法采用的是遗传算法。”
“那有谁使用了自顶向下的方法呢?”牛二哥继续“捧哏”道。
“嗯……这个嘛,Pivotal公司的开源优化器ORCA用的就是自顶向下的方法。可以让牛二哥先给你说说怎样用动态规划方法搜索最优物理路径。”
牛二哥拿出纸来画了几个圈,然后说:“这代表四个表,自底向上嘛,所以是从底下向上堆积,这是最底层,我们叫它第一层”。

“动态规划方法首先考虑两个表的连接,其中优先考虑有连接关系的表进行连接,两个表的连接可以建立一个新的表,我们把这些新表叫做第二层。”牛二哥通过连线,产生了一些新的“表”。
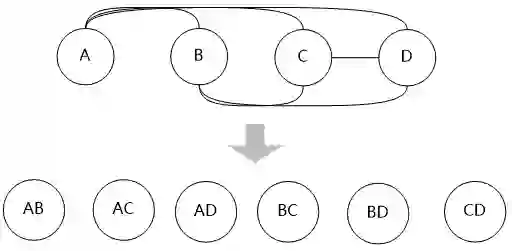
“第二层的表和第一层的表再连接,可以生成基于三个表连接的新的‘表’,这样就又向前推进了一层,我们产生了第三层”
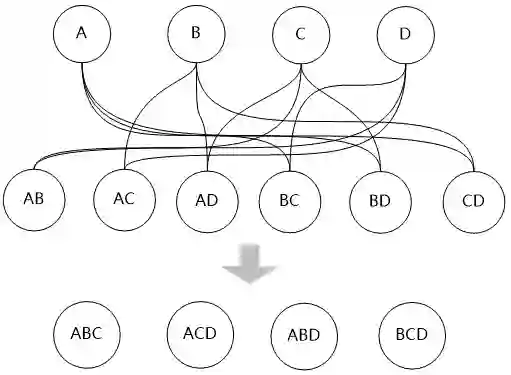
“然后再用第三层的表和第一层的表进行连接,最终生成整个问题的最优路径。”
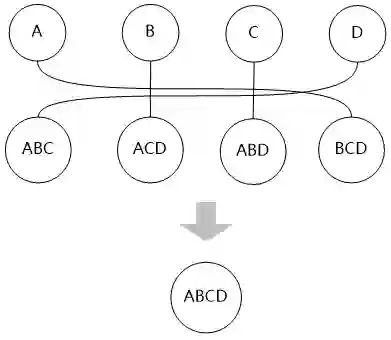
“可是,这不就是穷举吗?”小明问道。
牛二哥解释说:“动态规划有两个特点,一个是要重复地利用子问题的解,这样能减少计算量,降低复杂度;另外一点就是通过子问题的最优解能够构造出最终的最优解,也就是说需要具有最优子结构的性质,所以动态规划的复杂度和穷举是不一样的。”
大明继续解释说:“还有,虽然你看图里的连线比较多,但在实际情况里,并不是所有的圈圈之间都能产生连线,连接关系也有个合法性的问题嘛,所以复杂度是可以控制住的。”
小明感觉好像明白了一点,然后赶紧追问:“那遗传算法呢?”
大明说:“虽然动态规划的复杂度是可以控制的,但是如果表比较多,它的搜索空间还是很大,所以如果在表比较多的时候,可以尝试使用遗传算法,这个算法获得的不一定是全局最优解,可能是局部最优解。”
“那遗传算法是怎么实现物理路径搜索的呢?”小明问。
牛二哥从书柜里找到了一本算法的书,恰好里面有遗传算法的介绍,于是朗读了起来:“遗传算法的实现步骤如下:
种群初始化:对基因进行编码,并通过对基因进行随机的排列组合,生成多个染色体,这些染色体构成一个新的种群。另外,在生成染色体的过程中同时计算染色体的适应度;
选择染色体:通过随机选择(实际上通过基于概率的随机数生成算法,这样能倾向于选择出优秀的染色体),选择出用于交叉和变异的染色体;
交叉操作:染色体进行交叉,产生新的染色体并加入到种群;
变异操作:对染色体进行变异操作,产生新的染色体并加入到种群;
适应度计算:对不良的染色体进行淘汰。”
大明笑着说:“尽信书不如无书,我来说一下遗传算法是如何解决货郎问题的。我们可以将城市作为基因,走遍各个城市的路径作为染色体,路径的总长度作为适应度,适应度函数负责筛选掉比较长的路径,保留较短的路径,算法的步骤如下:
对各个城市进行编号,将各个城市根据编号进行排列组合,生成多条新的路径(染色体)。然后根据各城市间的距离计算整体路径长度(适应度),多条新路径构成一个种群;
选择两个路径进行交叉(需要注意交叉生成新染色体中不能重复出现同一个城市),对交叉操作产生的新路径计算路径长度;
随机选择染色体进行变异(通常方法是交换城市在路径中的位置),对变异操作后的新路径计算路径长度;
对种群中所有路径进行基于路径长度有小到大排序,淘汰掉排名靠后的路径。”
大明一口气说完了整个流程,长舒了一口气,继续说道:“怎么样,是不是so easy?”
小明想了想牛二哥和大明说的流程,然后说,“我来猜想一下PostgreSQL是如何实现遗传算法的。PostgreSQL应该是模拟了解决货郎问题的方法,它将表作为基因,最终生成的执行计划作为染色体,执行计划的总代价作为适应度,适应度函数则是基于路径的代价进行筛选,对不对?”
牛二哥赞叹道:“说得非常好,不过需要注意的是,PostgreSQL的基因算法实现方式和通常的遗传算法略有不同,在于其没有变异的过程,只通过交叉产生新的染色体,不过这都不是重点了。”
大明说:“哎哎哎,我们不是在搜索饭店吗,怎么就说起最优路径了?先点餐吧,再晚饭都没得吃了。”
于是三个人又热火朝天地搜起饭店来……
本故事到此暂时剧终了。通过上下两篇文章,我们基本已了解到大部分查询优化的概念,但篇幅有限,没能把细节说得特别到位,请大家多多包涵。
两篇文章中大部分内容均摘录自我的新书《PostgreSQL技术内幕:查询优化深度探索》,然后以小明、大明和牛二哥的对话方式展现出来。而书中介绍的代码分析部分以及比较深入的实现细节,由于不太便于展示,所以在故事中没有涉及到,有兴趣的同学欢迎从书中获取相关知识。

近期热文
MariaDB 10.3首推系统版本表,误删数据不用跑路了!
近期活动



