史上最全排序算法总结 | 原力计划




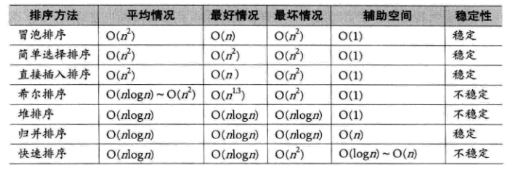
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。

每个节点都大于或是等于其左右孩子节点的值,称为大顶堆
每个节点都小于或是等于其左右孩子节点的值,称为小顶堆
根节点是整个堆的最大值,将它移走。
将剩余n-1个节点重新构造成一个堆,再将根节点移走
重复执行1,2。直到没有节点可移动,就生成了有序序列。
如何将一个无序序列构建一个堆。
移除根节点后,如何用剩余的节点重建堆。



热 文 推 荐
☞讯飞轮值总裁胡郁:大数据是人工智能产业落地的必要保障| BDTC 2019
点击阅读原文,与作者面对面交流!

登录查看更多
相关内容

Arxiv
8+阅读 · 2019年5月20日
Arxiv
10+阅读 · 2018年3月20日




相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2019年5月20日
Arxiv
10+阅读 · 2018年3月20日