当AI学会回忆:Deepmind提出长期信度分配新算法,登上Nature子刊
新智元报道
【新智元导读】DeepMind最近发表在Nature子刊上的论文为解决长期信度分配问题提出了一种新的算法TVT,该算法基于情景记忆检索,使AI智能体能够执行长期的信度分配。如何评价这一研究?来 新智元AI朋友圈 和AI大咖们一起讨论吧。

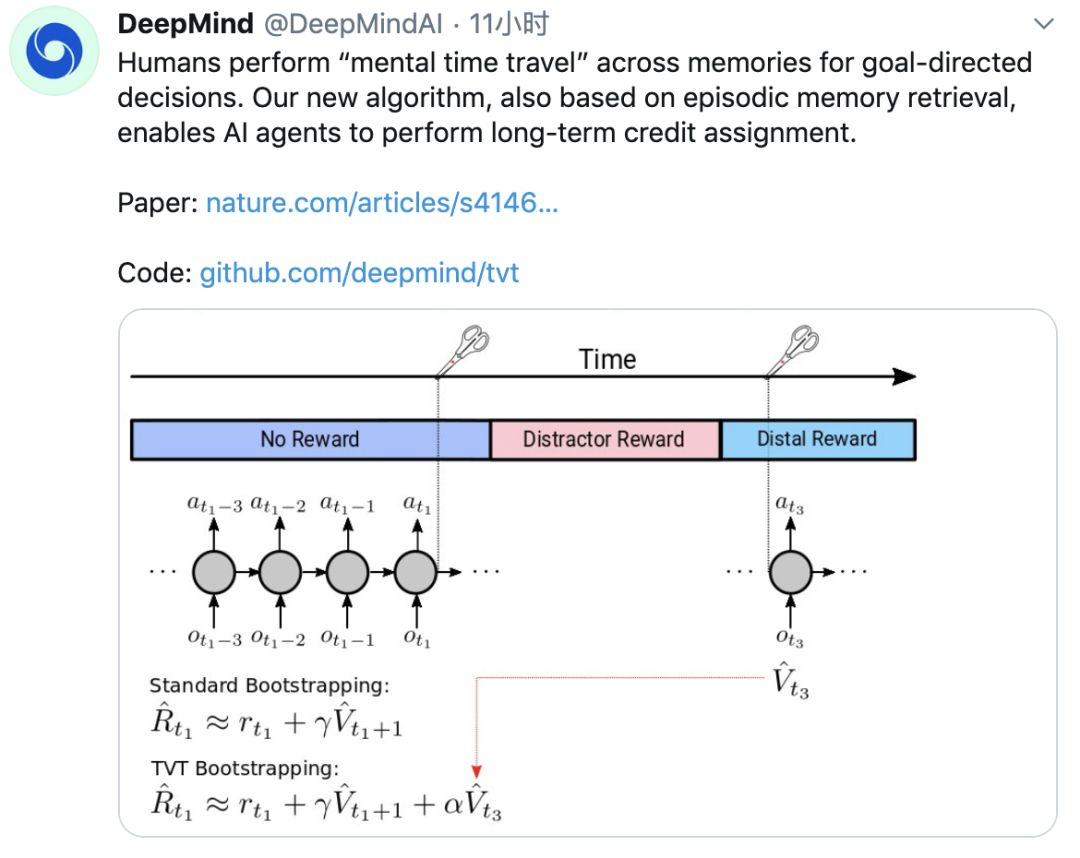
在深度强化学习基础上引入长期信度分配的原则
实验和结果:TVT学习算法解决两类基本任务
为了研究长时间延迟和干预活动下的决策,我们将任务结构形式化为两种基本类型。每个类型由三个阶段P1-P3组成(图1a)。
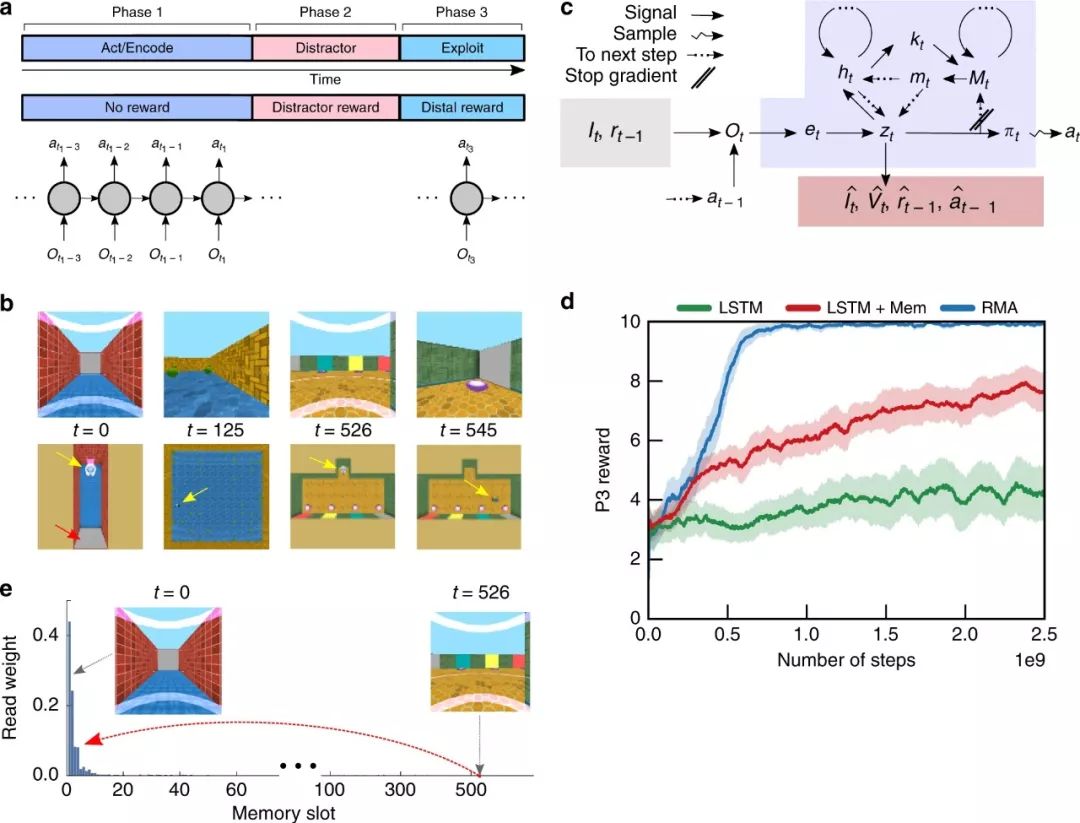
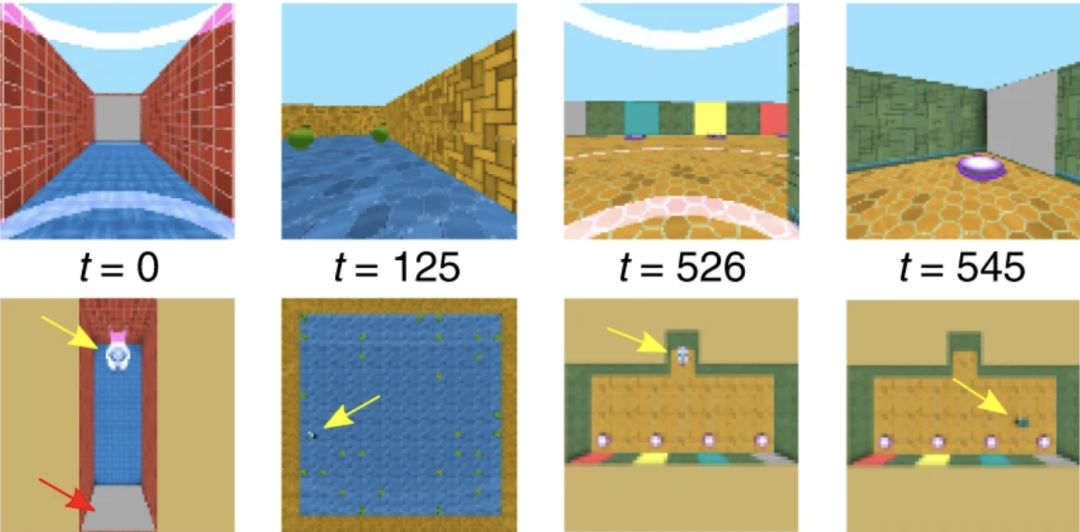
图1:任务设置和Reconstructive Memory Agent
在第一种任务类型(信息获取任务)中,在P1,agent必须在没有即时奖励的情况下探索一个环境来获取信息;在P2,agent长时间从事一项不相关的干扰任务,并获得了许多附带奖励;在P3,agent必须利用P1中获取的信息获取远端奖励。
在第二种任务类型(因果任务)中,agent必须采取行动触发P1中的某个事件,该事件只有长期因果后果。P2同样是一个分散注意力的任务,但在P3中,agent必须利用其在P1中的活动所引起的环境变化来取得成功。
由于我们提出的解决方案的一个关键部分涉及到记忆编码和检索,所以我们认为P1是由随后的记忆编码的动作组成,P2是干扰因素,P3是利用(图1a)。
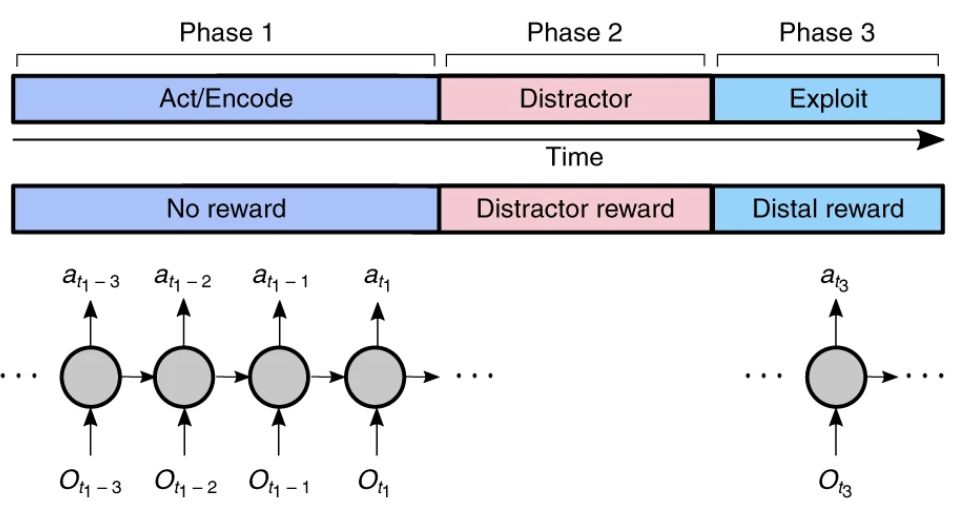
图1a:3阶段的任务结构。在P1,没有奖励,但是agent必须寻找信息或者触发事件。在P2,agent执行一个提供奖励的干扰任务。在P3, agent可以根据其在P1中的行为获得远端奖励。
虽然我们有时会报告P2中的性能,但为了确保agent在执行干扰任务时的性能是相同的,我们将主要关注P3中agent获得的性能。挑战在于在P1中产生有助于P3表现的行为,从而实现LTCA。虽然这种任务结构是设计的,但它使我们能够系统地控制延迟时间和干扰奖励的差异。
在这些假设下,我们可以通过在策略梯度估计中定义一个引起P1行为适应的信噪比(SNR)来理解为什么干扰阶段会对LTCA造成损害。
重建记忆智能体(Reconstructive Memory Agent, RMA)
我们使用一个AI智能体来解决这个任务,将其命名为RMA(图1c),它是从以前的模型简化而来的。关键的是,这个模型结合了一个重建过程来压缩有用的感官信息和记忆存储,这些存储可以通过基于内容的寻址查询来通知agent的决策。RMA本身不具有支持LTCA的专门功能,但是为TVT算法的操作提供了基础。
现在我们转到需要LTCA的第1类的信息获取任务,即Active Visual Match。这里,在P1阶段,agent必须主动地在一个两个房间的迷宫中随机找到一个彩色正方形,这样它才能决定P3中的匹配项(图2a)。
如果一个agent在P1中偶然发现了视觉线索,那么它可以在P3中使用这个信息,但这只能是随机成功的。在被动的视觉匹配中,agent在P2阶段执行一个30秒的收集苹果干扰任务。
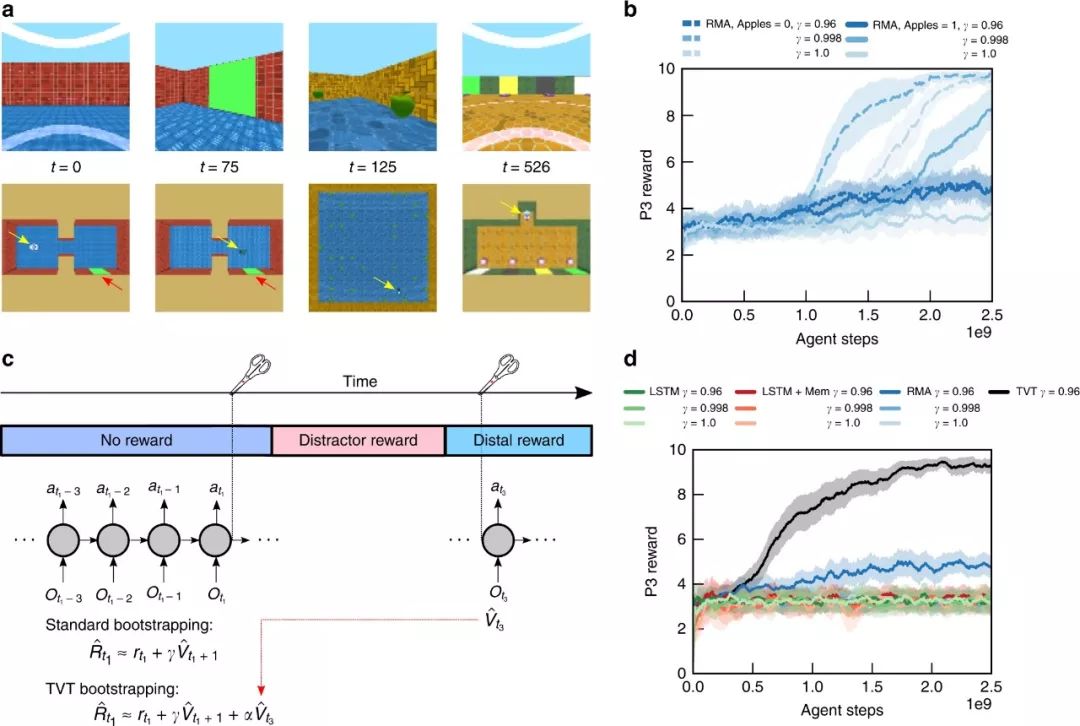
图2:Temporal Value Transport 和第一类信息获取任务。
Temporal Value Transport
TVT是一种学习算法,它增强了基于记忆的智能体解决LTCA问题的能力。我们可以将注意力记忆访问与RL结合起来,通过自动发现如何忽略它来有效地将问题转换成一个没有延迟的问题,从而对抗偏差。
RL里的一个标准技术是通过bootstrapping来估计策略梯度计算的收益:使用学习的值函数,它是确定的,因此方差小,但有偏差,以减少回报计算中的方差。
在图2c中,我们强调了TVT背后的基本原理。在之前的Passive Visual Match 任务中,我们看到RMA读取机制学会了从P1中检索记忆,以生成P3中的值函数预测和策略。
当应用于具有较大干扰奖励的Active Visual Match 任务时,具有TVT的RMA模型在P1阶段学习了正确的行为,甚至比没有干扰奖励的RMA更快。(图2 b, d)。学习行为的差异是戏剧性的:TVT可靠地找到了P1中的彩色方块,而RMA表现随机(图3)。
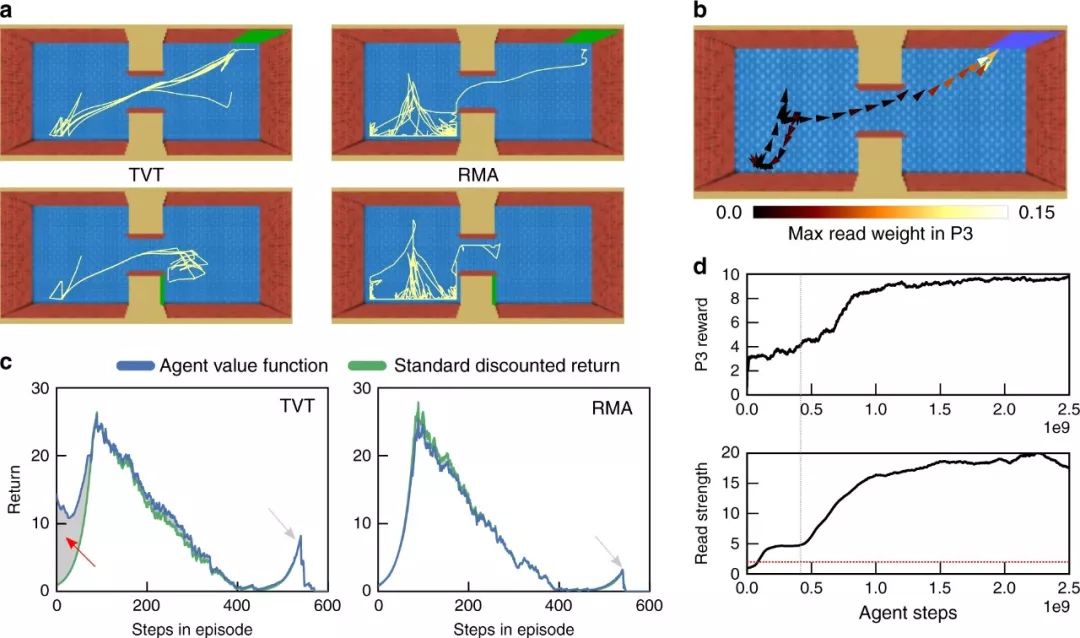
图3:主动视觉匹配任务中agent的分析
TVT还可以解决第二类因果关系任务,其中,agent不需要为P3获取P1中的信息,而是必须引起将影响P3中环境状态的事件。这里我们研究的是Key-to-Door(KtD)任务,在这个任务中,一个agent必须学会在P1中捡起一把钥匙,这样它才能打开P3中的一扇门,从而获得奖励(图4a)。
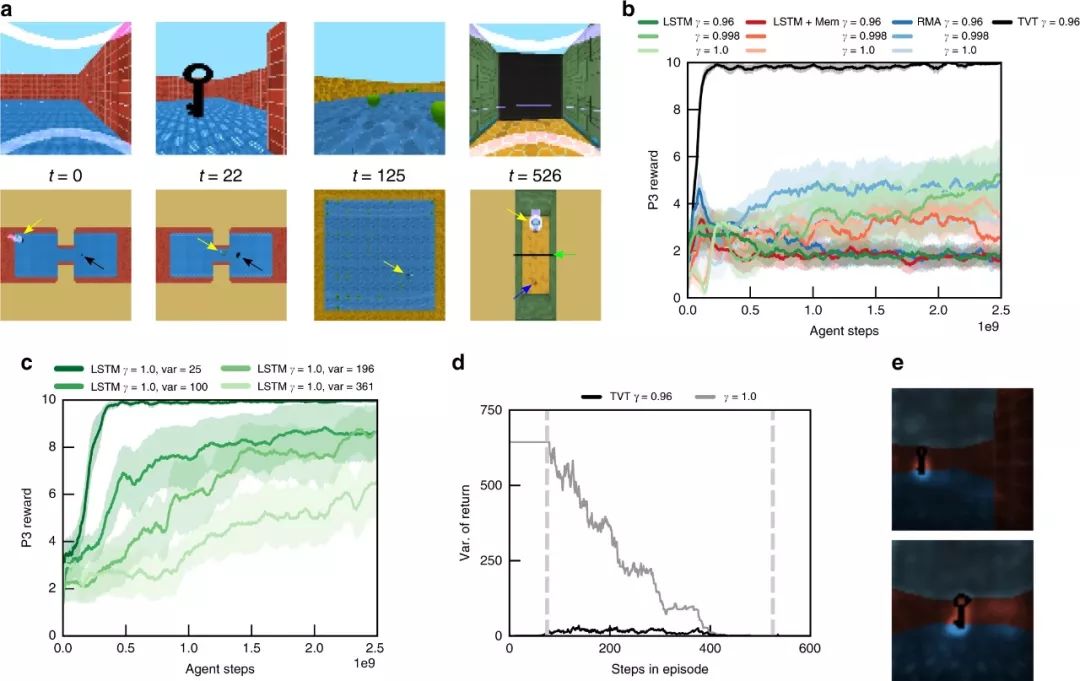
图4:第二类因果任务。
在确定TVT能够解决简单问题之后,我们现在将在两个更复杂的场景中演示TVT的能力。第一个是KtD和Active Visual Match 任务的结合,演示了跨多个阶段的TVT——捡钥匙开门到匹配任务(KtDtM);在这种情况下,agent必须表现出两个非连续行为才能获得远端奖赏。
这个任务有P1–P5五个阶段(Fig. 5a).
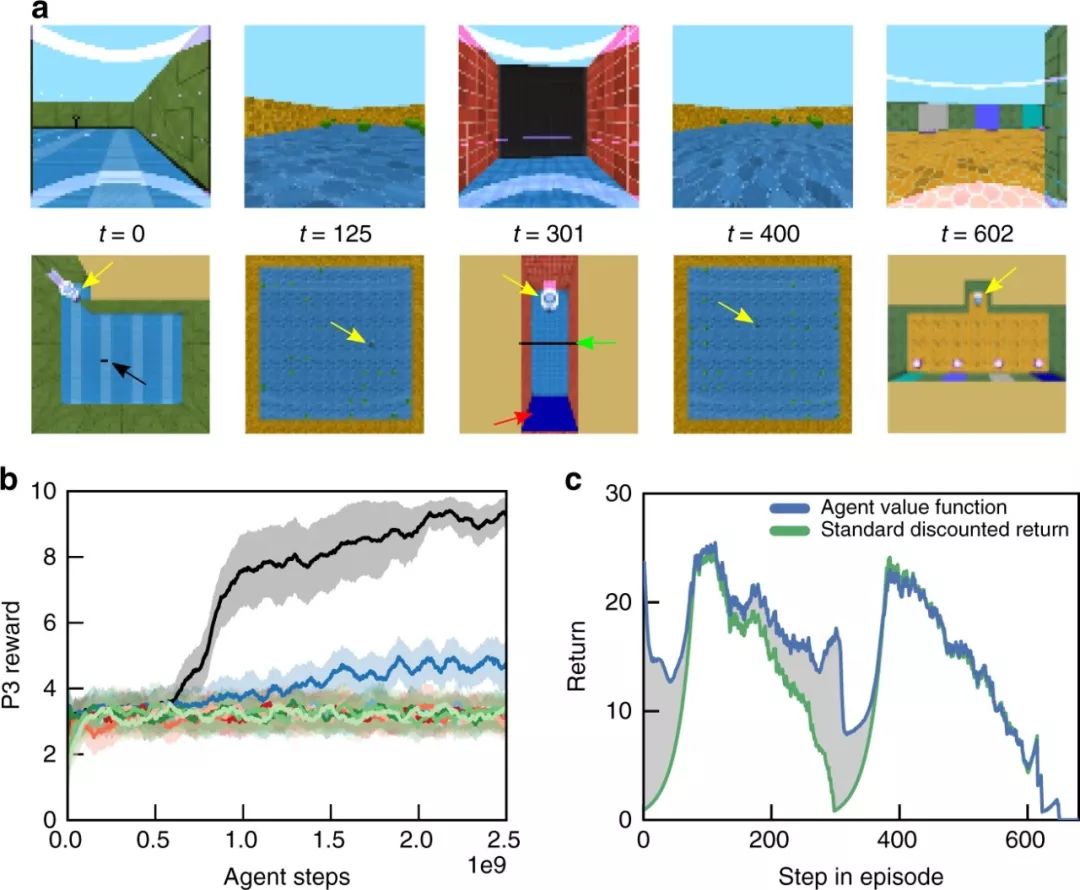
图5:Transport across multiple phases.
最后,我们来看一个更丰富的任务——潜在信息获取(图6a)。
TVT agent单独完成了任务(图6b,黑色曲线),通常在P1中接触所有三个对象(图6d),而RMA平均只接触一个对象(图6b,其他颜色)。在P1中,对象被放置在6个可能位置的网格中(与P3位置无关)。只有TVT学习到一种探索性的扫描行为,可以有效地覆盖对象所在的位置(图6c);RMA移动到同一角落,因此意外地触及了一个物体。
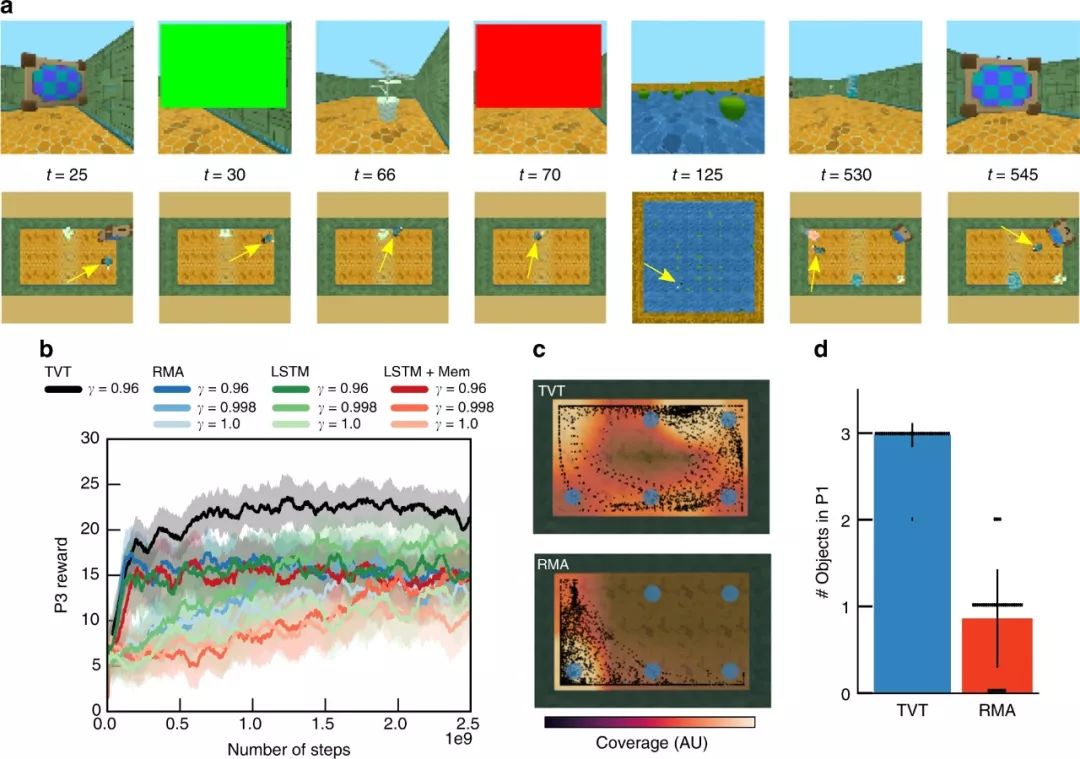
图6:更复杂的信息获取任务
该研究的代码已开源:
https://github.com/deepmind/deepmind-research/tree/master/tvt
-
与国内外一线大咖、行业翘楚面对面交流的机会 -
掌握深耕人工智能领域,成为行业专家 -
远高于同行业的底薪 -
五险一金+月度奖金+项目奖励+年底双薪 -
舒适的办公环境(北京融科资讯中心B座) -
一日三餐、水果零食
新智元邀你2020勇闯AI之巅,岗位信息详见海报:




