用好Jupyter Notebook的十个技巧
点击上方
Datartisan数据工匠
可以订阅哦!
Jupyter Notebook(也被叫做 iPython Notebook)是非常使用的编程工具。它很适用于实现重复性实验。下面是我工作以来,对Jupyter Notebook总结的10条小技巧。
1.使用Virtualenv来创建隔离环境
你可能想将所有的研究用哭都安装在你的操作系统里,并且在你所有的项目中共享。不久你会发现当你添加新的库时,被安装过的库也可能会被更新。然而有的库不能够兼容新的版本,所以当你回到曾经的项目时,你会花费很多时间来寻找问题原因,并且修复它们。
解决方法就是对你的每个项目都创建一个独立的虚拟环境。我建议通过virtualenvwrapper使用virtualenv。为了免于虚拟环境的路径问题的困扰,你可以在每个环境中独自安装Jupyter。
2.使用Python 3
版本3确实更好用。
3.包含 requirements.txt
当你的项目有了隔离的环境后,建议你保存项目必须的依赖关系列表。这会在你今后节约不少的时间。比如,当你想要重建一个环境的时候。

4.在第一个Cell中完成所有的导入
在你的Notebook中的第一个cell里完成所有的库的导入。这个任务需要的工具和依赖库能够一目了然;当你重启notebook服务器的时候,你能够在一步运行中完成所有的导入。当你不想重新执行整个notebook的时候,这会很有用。
我也会利用这个cell来定义所有需要的文件路径。
5.不要太拘泥小节,保留你的草稿
快点开始,随意一些。你越快开始你想做的越好,因为灵感很可能会稍纵即逝。但是当你发现你开始自乱阵脚,没有效率,开发过程变得一团乱麻,那么是时候开始整理你的notebook了。从头开始,保留好的代码,重写差的部分,但是不管你要做什么,都记住:保留你notebook上的草稿。
6.用函数来封装cell内容
很多的notebook的cell看起来会像这样:

在cell开始一般都有参数定义。你可以改变参数然后重新执行,或者你可以复制整个cel然后来修改参数。经过中间的计算过程,最后会输出一行结果。
在草稿里你可以这么做,但是随着项目的进展会变得难以管理。你有一大堆的中间变量填满了命名空间,你也失去了指引你到当前参数选择的步骤。
作为替代,你可以把所有的东西打包成一个函数:

你可以修改参数并且重新运行在隔离的cell中,并且保持修改的历史记录。并且中间过程不会产生冗余的变量占用内存。
7.使用joblib来存储输出
你花了三天来构思你的神经网络,并且现在你准备开始搭建。但是你忘了带你的手提电脑的充电线,而且它也快没电了。所以你尖叫道:我为什么没有保存? 管理文件名,检查文件是否存在、保存、加载等等,有什么方法可以代替呢?使用joblib

利用这三行代码,你就能够存储任何函数的输出。Joblib会跟踪传入函数的参数,并且如果这个函数在使用相同参数的情况下被调用,它会返回在硬盘上存储的结果。
8.独立的notebook段落
要松弛有度地对你的Notebook进行区域划分,并且尽可能少地使用全局变量。如果你用函数来封装cell,用joblib来储存输出,那么在不同的区域来调用这些代码简直易如反掌。相比较,通过注释让前面部分代码创造的变量更明确,远不如我们这里提到的标准化的方式。
一般来说,在你打算重新开始来继续你之前的工作的时候,试着限制你必须要运行的cell的数量。
9.重用变量名
在你可以使用已经存在的变量名的时候,不要使用太长的变量名字。这似乎和我在讲解开发其他软件时候给出的建议相违背,但是在Notebook中,这种方法确实更有效。
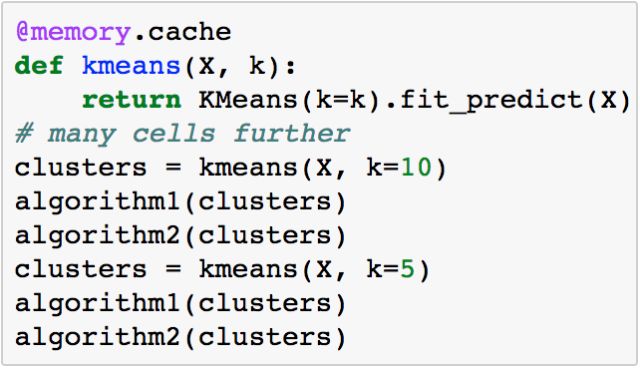
让我通过一个例子来讲解。我们假设你的算法需要一个集群。你尝试各种版本的集群和算法。你的代码如下:

但是你利用joblib和重名变量,会有:
10.利用声明来检测功能函数
当你构建了几个功能函数的时候,试着利用assert关键词来进行检测。比如:

以上就是我自己的小贴士。你自己在使用管理notebook过程中,有什么值得分享的经验吗?

更多课程和文章尽在微信号:
「datartisan数据工匠」