本文通过从单张照片克隆整套衣服穿搭到三维人物,构建了一个包含 5621 个三维人物模型的虚拟行人数据集 ClonedPerson。这些虚拟人物在游戏环境里模拟真实监控渲染了多场景下的多摄像机视频。实验表明,该数据集在行人再辨识任务取得了良好的泛化性,并可应用于无监督域适应、无监督学习、人体关键点检测等多个相关任务。相关论文已被 CVPR 2022 接收,数据和代码已开源。
![]()
-
论文地址:https://arxiv.org/pdf/2204.02611.pdf
-
项目地址:https://github.com/Yanan-Wang-cs/ClonedPerson
大规模虚拟数据已经被证明能显著提升可泛化的行人再辨识能力。
现有的虚拟行人数据库(例如 RandPerson 和 UnrealPerson)的人物穿着与现实生活差距较大,且没有考虑服装搭配问题
。
如下图 1 所示,(a)RandPerson 的随机颜色和纹理组合生成虚拟人物的策略使其人物偏卡通化;(b)尽管 UnrealPerson 使用了真实衣服纹理来生成人物,但由于衣服纹理的尺寸问题,生成的虚拟人物和真实人物依然有较大的差异,且未考虑上下半身的协调穿搭。
![]()
图 1. RandPerson, UnrealPerson 和 ClonedPerson 的对比图
有鉴于此,
本文提出一种自动从单角度人物照片中克隆整套衣服穿搭并产生三维人物模型的方案
,并在游戏环境里模拟真实监控进行渲染,由此得到一个更真实的大规模虚拟行人数据集,并最终提升行人再辨识模型的泛化表现。
不同于已有的通过视频或多视角照片重建的方法,我们立足于克隆单张照片中的整套衣服生成虚拟人物。
这样可以使用互联网上大量人物照片进行服装克隆,达到规模化的限制条件很低
。
另外由于
本文提出的方法将照片中人物的整套衣服克隆到虚拟人物身上,有效解决了现有虚拟数据库服装搭配与现实生活不匹配的问题
。
具体而言,本文设计了
衣服配准映射(registered clothes mapping)
和
均匀布料扩展(homogeneous cloth expansion)
两种方法来克隆衣服纹理。
其中,衣服配准映射主要针对目标 UV 纹理图衣服结构清晰的人物模型,
根据正面人物照片和模型纹理图中衣服对应关键点的位置进行投影变换,从而保留衣服纹理的清晰度和纹理结构
。均匀布料扩展主要针对人物背面(在正面照片中背面纹理不可见),
通过找到并扩展衣服区域面积最大的同质纹理实现自动填充人物背面纹理
。
除此之外,
本文还提出一个相似性 - 多样性人物扩展策略,通过聚类的方法使生成的虚拟人物既具有相似性,又具有多样性,从而形成最大效用的大规模虚拟行人数据集
。该方法通过克隆同一聚类的人物照片生成相似人物,同时通过克隆不同聚类的人物照片生成多样性的人物。
最后,通过在 Unity3D 的场景下进行渲染得到一个包含自动标注的虚拟行人数据集,称为 ClonedPerson。它包含 5621 个虚拟人物,6 个场景,24 个摄像机,168 段密集行人的视频,887,766 张切好的行人图片。图 1 c 展示了部分虚拟行人图片。
论文通过实验证明了 ClonedPerson 虚拟数据集可以应用在多个任务中,如行人再辨识及其跨域泛化、 无监督域适应、无监督学习、和人体关键点检测。其中,跨库泛化性测试显著超越三大主流行人再辨识数据集(CUHK03、Market-1501 和 MSMT17)和当前流行的虚拟行人再辨识数据集(RandPerson 和 UnrealPerson)。
数据匮乏一直制约着行人再辨识的发展,除了标注困难之外,近年来对监控视频数据的隐私敏感性的关注更是让这个问题雪上加霜,已经有一些公开数据集因此而下架了。与之相反,虚拟数据几乎无需标注且没有隐私敏感问题,且虚拟数据已经被证实能显著提升行人再辨识模型的泛化性能。
为此,研究人员提出了一些方法来生成大规模虚拟数据库,例如
RandPerson 和 UnrealPerson
。然而,
这些数据库中的人物衣着纹理与真实人物有很大的区别,限制了虚拟数据库的提升效果
。
![]()
图 2. ClonedPerson 和 HPBTT 生成人物的对比图
此外,研究人员采用不同的方法实现了将 2D 照片中的人映射到 3D 模型上,例如 PIFu、HPBTT 和 Pix2Surf。然而,使用这些方法生成大规模虚拟数据库存在以下问题:
-
PIFu 由于训练数据需要 3D 形状标注,限制了其得到充分有效的训练;
-
HPBTT 通过神经网络模型生成的纹理相对模糊,衣服的纹理结构不够清晰(如图 2c 所示);
-
Pix2Surf 则需要输入背景相对简单且拥有正背面纹理的衣服照片;
-
HPBTT 和 Pix2Surf 所采用的 SMPL 模型可能缺乏通用性,如图 2c 所示的裙子问题。
因此,为了解决上述问题,本文提出一种通过克隆单角度照片中的衣服生成大量三维人物模型的方案,并针对该方案设计了两种克隆方法。基于此方法可以将照片中的衣服纹理克隆到虚拟人物身上。
图 2 展示了此方法和 HPBTT 生成人物的对比图。考虑到生成数据的相似性和多样性,本文设计了一个相似性 - 多样性人物扩展策略来扩展人物模型。最后得到了一个包含自动标注的虚拟行人数据集 ClonedPerson。
该方法
降低了对输入图片的要求(可以应用在互联网上获取的大量人物照片中),且设计的两种克隆方法能够得到清晰的正面纹理并自动补全背面纹理,因此可以不需要输入背面图片
。
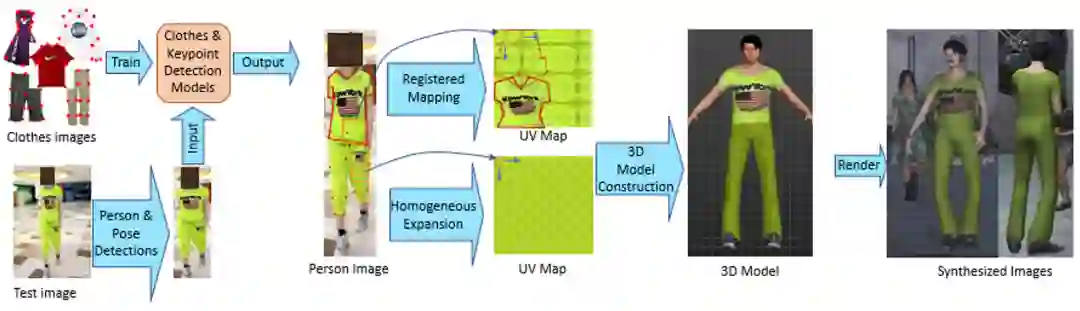
下图 3 展示了本文提出的克隆方案,包含以下步骤:首先在预处理阶段,使用行人检测、人物关键点检测、服装类型和服装关键点检测筛选图片;其次使用衣服配准映射和均匀布料扩展两种方法克隆衣服纹理并生成虚拟人物;最后将人物导入虚拟环境生成数据。
![]()
图 3. ClonedPerson – 从单角度人物照片到虚拟数据的方案图
其中,预处理阶段的方法是为了提升生成人物的成功率。由于存在大量单角度的照片可以克隆,选择一些正面且衣服图案未被遮挡的照片来生成人物可以显著提高服装分类和服装关键点检测的成功率,而且由这些照片生成的虚拟人物更具有完整的衣服纹理和服饰搭配。
![]()
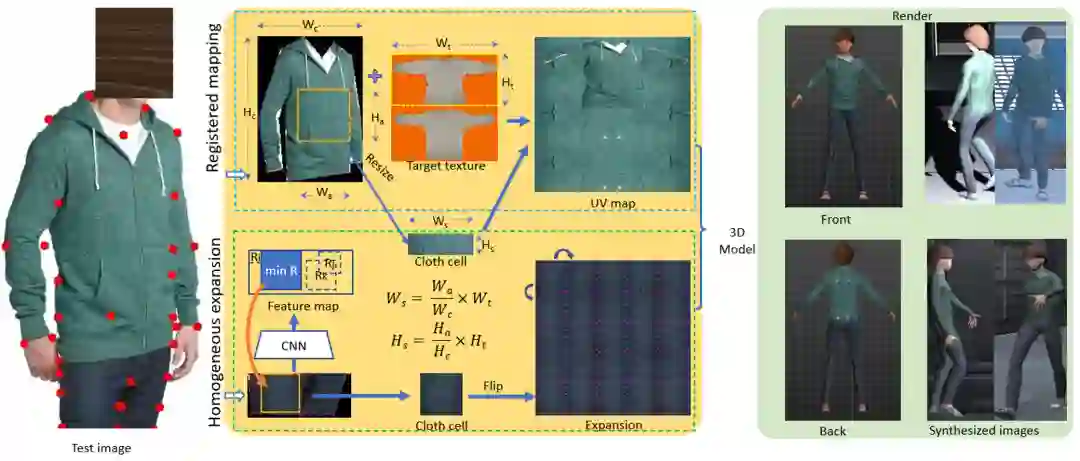
本文采用了 MakeHuman 来制作三维人物。该软件的用户社区资源中包含多种衣服模型,其中大部分模型的 UV 纹理图具有清晰的纹理结构,如上图 4b 所示,称为规则纹理图。由此可以通过经由关键点配准的投影方法将真实照片中的图案投影到模型的 UV 纹理图上。
再如图 4 所示,目标模型纹理图中标注了一系列关键点位置(如 4b 红点所示),真实照片中衣服相应关键点位置可以通过训练检测器检测得到(如 4a 红点所示),再通过求解投影变换矩阵,便可以对照片中衣服区域的每个像素点计算出它在纹理图上的对应点,以此实现衣服配准映射。下图 5 的上部分展示了衣服配准映射的过程。
![]()
通过衣服配准映射可以将衣服正面纹理映射到规则纹理图的相应位置,但不能处理衣服模型的背面纹理和不规则纹理图(如图 4c 所示)。因此,本文提出了第二种方法 —— 均匀布料扩展来解决这个问题。
如上图 5 下半部分所示,首先通过一个训练好的行人再辨识模型对衣服图片抽取特征,然后在特征中遍历不同的矩形块。通过计算每个特征的均值方差,可以找到块内平均方差与矩形面积之比的最小矩形块,其对应区域为最优同质块。
对于规则模型,如图 5 所示,由于投影变换造成了图像尺寸变化,获得的同质块需要进行相应的尺度变换来保证纹理的一致性。对于不规则模型则保持同质块的原始尺寸。获得同质块后,使用图片翻转的策略扩展同质块来填充纹理图。
![]()
本文使用 DeepFashion 和 DeepFashion2 数据库生成虚拟人物。通过预处理阶段筛选后,仍然有数万张照片可以用来生成虚拟人物。考虑到生成的数据应该具备相似性和多样性,本文设计了一个相似性 - 多样性人物扩展策略。
由于照片中存在同一人多角度的照片,首先需要去除这些相同衣服纹理不同角度的照片。因此本文对照片进行两次聚类:第一次去除重复图片,第二次选取具有相似性和多样性的照片。第一次聚类使非常相似(同一人的不同角度)的照片聚在一起,并抽取每类距离中心点最近的一张图片和聚类失败的图片混合后进行第二次聚类。
两次聚类后,如上图 6 所示,相似性 - 多样性人物扩展策略通过采样克隆同一聚类内的人物照片生成相似人物,通过克隆不同聚类的人物照片生成多样性的人物。本文从聚类结果中的每一类抽取 7 张照片进行克隆(5 张生成训练集,2 张生成测试集),最终生成 5621 个虚拟人物。将这些虚拟人物渲染后得到数据集 ClonedPerson。
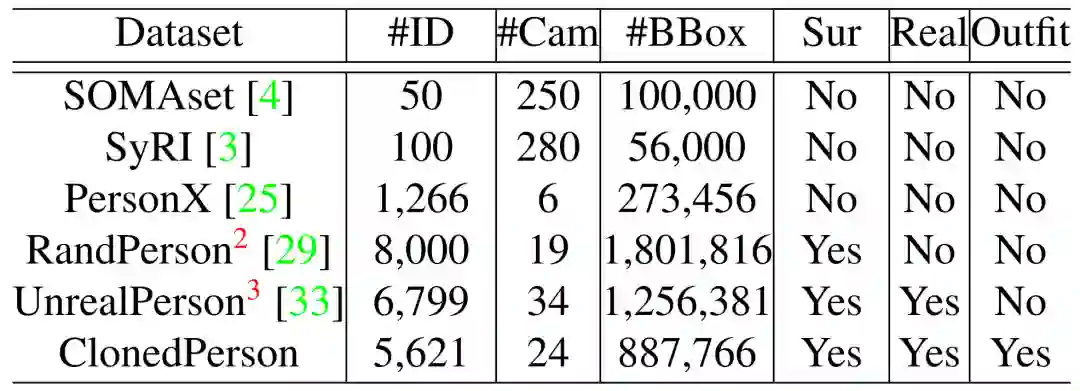
下表 1 统计了 ClonedPerson 和其他虚拟行人数据集的一些特征。
![]()
表 1. 虚拟行人数据集统计表。Cam:摄像头数,Sur:模拟真实监控场景,Real:使用真实衣服纹理,Outfit:考虑服装搭配
实验结果表明,ClonedPerson 可以被应用在传统的单库行人再辨识(表 3)、跨库可泛化的行人再辨识(表 2、3、4)、无监督学习(表 3)、无监督域适应(表 3、4)和人体关键点检测(图 7)中,且 ClonedPerson 训练出的模型在跨库测试中有良好的泛化性能。
![]()
表 2. 使用 QAConv 2.0 在不同数据库上的跨库测试结果
![]()
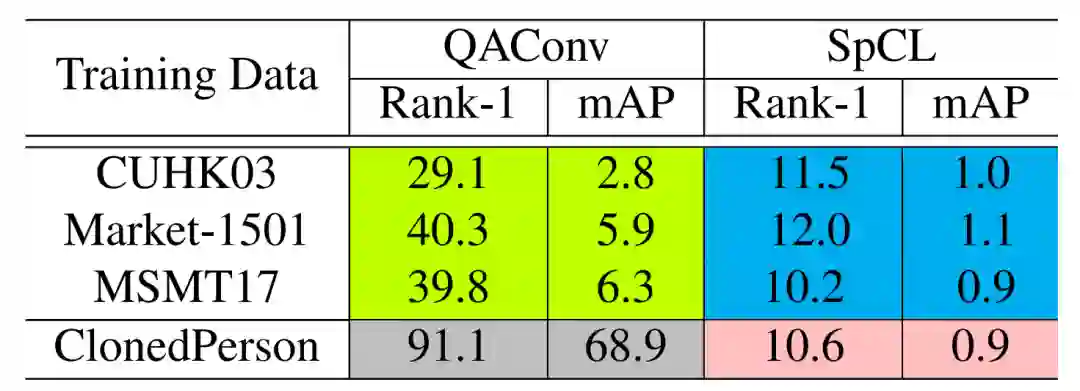
表 3. 不同模型在 ClonedPerson 测试集的结果。绿色区域:跨库测试;灰色:库内测试;蓝色:UDA;粉色:无监督学习
![]()
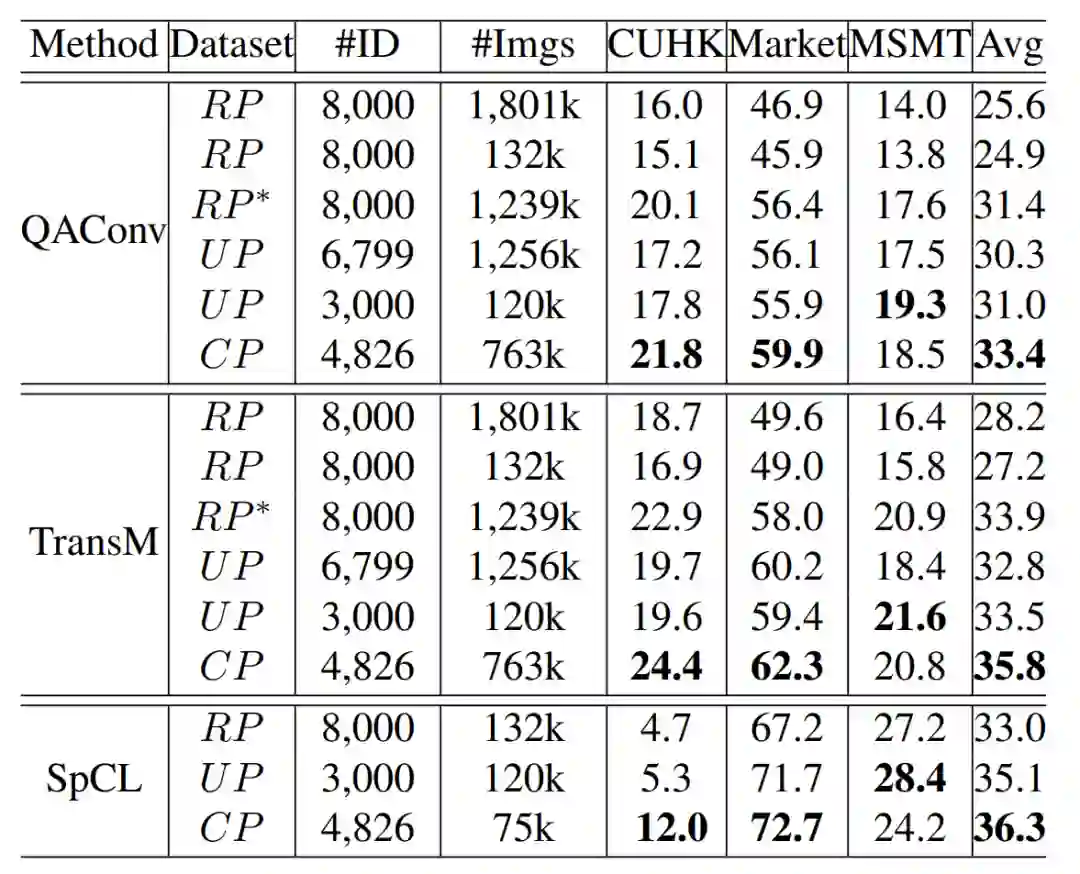
表 4. 不同任务在不同数据库上的 mAP 结果。TransM:TransMatcher,RP: RandPerson, RP*:RandPerson中的人物在 ClonedPerson 环境中渲染, UP:UnrealPerson,CP:ClonedPerson
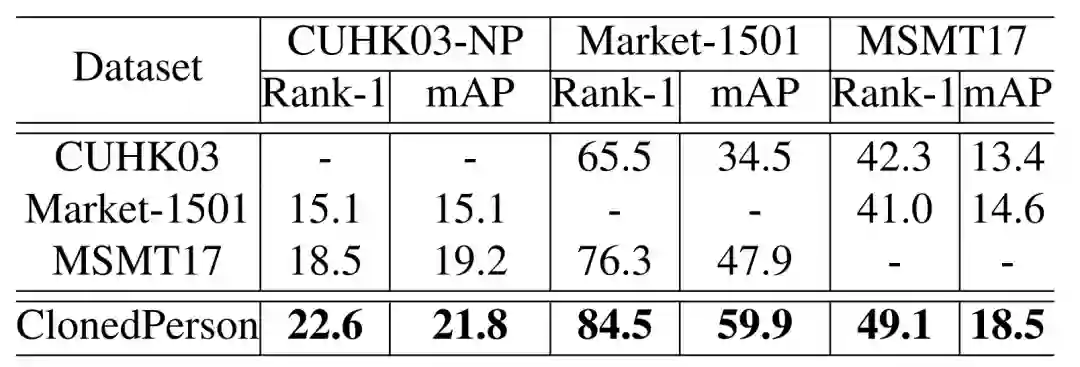
从跨库测试(表 2 和表 4)的结果可以看出,ClonedPerson 数据库能很好地应用在可泛化的行人再辨识任务中。例如,表 2 表明,对比真实数据库,ClonedPerson 上训练的模型泛化性能显著超过在真实数据库(CUHK03,Market-1501 和 MSMT17)上训练的模型。
表 4 表明,对比已有的虚拟数据库,ClonedPerson 训练的模型在 CUHK03 和 Market-1501 上具有更好的泛化性能。UnrealPerson 更真实的场景(采用虚幻引擎)和更多的摄像头数可能导致 ClonedPerson 在 MSMT17 上的泛化性能弱于 UnrealPerson。但是,考虑到三个真实数据库的平均泛化性能,ClonedPerson 则更胜一筹,证明了从照片中克隆衣服生成虚拟数据的有效性。
此外,本文还使用 ClonedPerson 作为测试集进行测试(表 3)。实验结果表明,一方面,ClonedPerson 可以支持多个行人再辨识任务;另一方面,在 ClonedPerson 上的测试结果(表 3)显著低于在真实数据库上的测试结果(表 2),表明 ClonedPerson 本身也是一个相当有挑战性的数据库。
ClonedPerson 还可以用在无监督域适应(UDA)任务中。当 ClonedPerson 作为源数据集时(如表 4 所示),对比 RandPerson 和 UnrealPerson,ClonedPerson 具有更高的平均泛化性能。当 ClonedPerson 作为目标数据集时(如表 2 蓝色区域所示),由于多样化的摄像头和大量的相似人物,在 ClonedPerson 上的 UDA 性能还有很大的提升空间。
除此之外,ClonedPerson 的关键点信息也可以用来训练人体关键点模型。图 7 展示了用 ClonedPerson 训练的人体关键点检测模型在真实数据集上的检测效果示例图。为了节省存储空间,ClonedPerson 目前只记录了 7 个基本关键点,但数据渲染过程中可记录更多关键点的位置信息用于后续扩展。
![]()
本文提出了一种通过克隆单角度照片中的衣服生成大量三维人物模型的方案,并在该方案中设计了两种克隆方法和一种相似性 - 多样性人物扩展策略,最终得到了一个包含自动标注的虚拟行人数据集 ClonedPerson。本文通过实验证明在克隆照片生成的数据库上训练能提升行人再辨识模型的泛化能力和支持相关的多个任务。
本文所提方法的优势是能生成服装纹理清晰,并与照片中人物的衣服穿搭表观相似的虚拟人物。使用这些更真实的虚拟人物生成的虚拟数据具有更好的泛化性能。本文提出的方法由于只需要单一角度的人物照片,对输入图片的要求较小,因此可以采用大量互联网图片进行后续扩展。
此外,ClonedPerson 公开了相应的图片和视频数据,未来可以探索更多的相关任务,如行人检测,行人跟踪,多摄像机行人跟踪等等。
王雅楠,现任阿联酋起源人工智能研究院工程师。研究兴趣为行人分析。
廖胜才,阿联酋起源人工智能研究院(IIAI)主任研究员。IEEE 高级会员。研究兴趣为行人和人脸分析。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com