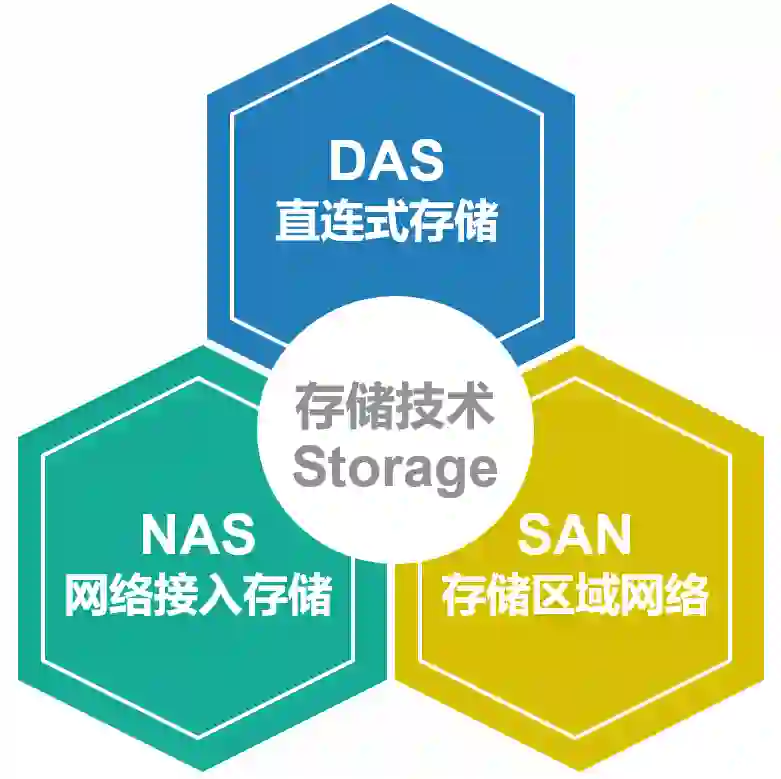
我们知道,在很长的一段时间里,这三种架构几乎统治了数据存储市场。所有行业用户的数据存储需求,都是在这三者中进行选择。
然而,随着时代的发展,一种新的数据存储形态诞生,开始挑战前面三者的垄断地位。
没错,它就是云计算时代存储技术的新网红——对象存储。
对象存储,也称为“面向对象的存储”,英文是Object-based Storage。现在很多云厂商,也直接称之为“云存储”。
不同的云厂商对它有不同的英文缩写命名。例如阿里云把自家的对象存储服务叫做OSS,华为云叫OBS,腾讯云叫COS,七牛叫Kodo,百度叫BOS,网易叫NOS……五花八门,反正都是一个技术。
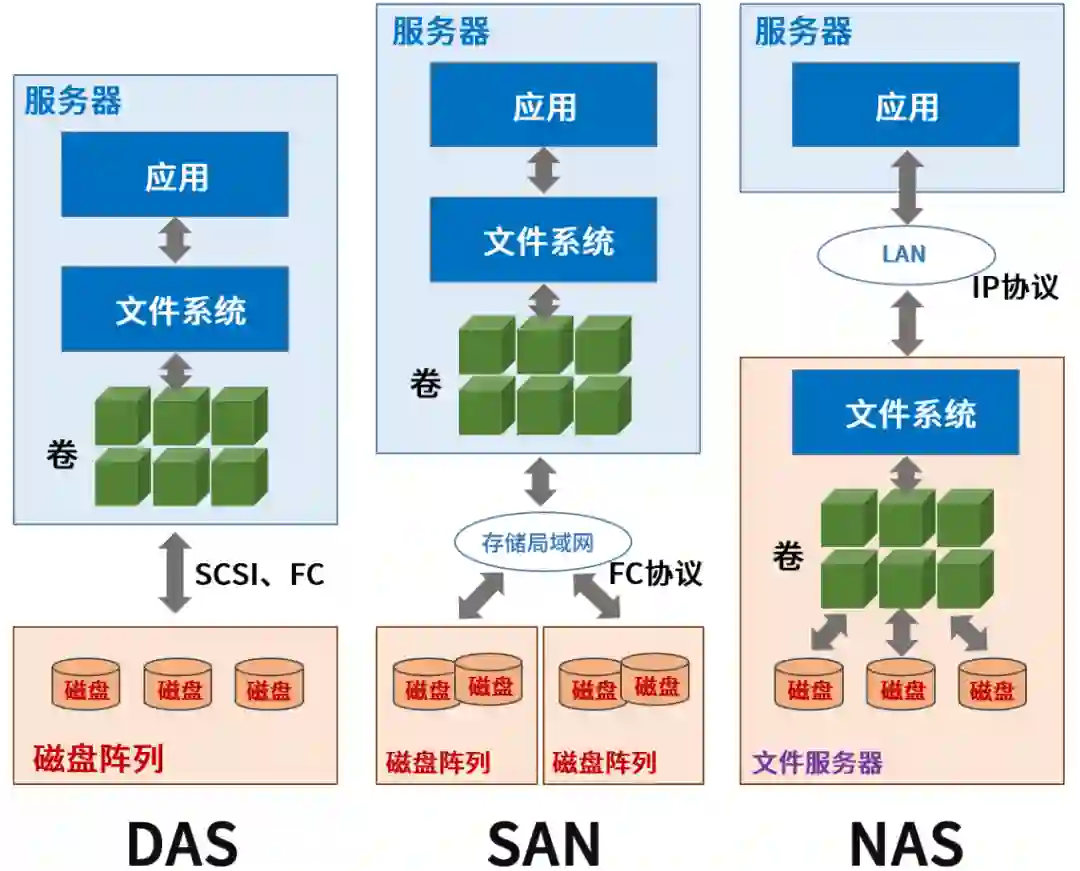
之前小枣君介绍过,DAS和SAN是基于物理块的存储方式,而NAS是基于文件的存储方式。
在DAS和SAN中,存储资源就像一块一块的硬盘,直接挂载在主机上,我们称之为块存储。
而在NAS中,呈现出来的是一个基于文件系统的目录架构,有目录、子目录、孙目录、文件,我们称之为文件存储。
文件存储的最大特点,就是所有存储资源都是多级路径方式进行访问的。例如:
C:\Program Files (x86)\Tencent\WeChat\WeChat.exe
\\NJUST-Server\学习资料\通信原理\第一章作业.doc
20世纪末,随着互联网的爆发,数据存储需求发生了两个重大的变化。
原因我就不用说了吧?大家可以瞅瞅自己的硬盘,都藏了些什么。
![]() Web应用的崛起、社交需求的刺激,极大地推动了多媒体内容的创作和分享。人们开始上传大量的照片、音乐、视频,加剧了数据量的爆发。
此外,信息技术的发展、企业数字化的落地,也产生了大量的数据,不断吞食着存储资源。
举个例子大家就明白了。我们经常做的excel表格,姓名、身高、体重、年龄、性别,这种用二维表结构可以进行逻辑表达的数据,就是结构化数据。
而图像、音频、视频、word文章、演示胶片这样的数据,就是非结构化数据。
根据此前的预测,到2020年(也就是今年),全球数据总量的80%,将是非结构化数据。
面对这两大趋势,因为本身技术和架构的限制,DAS、SAN和NAS无法进行有效应对。
虽然我们说对象存储是新网红,但实际上它诞生的时间并不算短。早在1996年,美国卡内基梅隆大学就将对象存储作为一个研究项目提出来。随后,加州大学伯克利分校也有推出类似的项目。
2002年,Filepool公司推出了基于内容可寻址技术的Centera系统,算是比较早期的对象存储系统。
2006年,美国Amazon公司发布AWS S3(Simple Storage Service)服务,正式将对象存储作为一项云存储服务,引入云计算领域,从此开启了对象存储的黄金时代。
说了半天,对象存储到底是一个什么样的技术?它和块存储、文件存储有什么区别?
首先,第一点,千万不要去看百度百科上面“对象存储”的定义,否则,你可能会怀疑人生。
想要了解对象存储,最简单直接的办法,就是从实际使用体验上进行对比。
对象存储的底层硬件介质,依然是硬盘,和块存储、文件存储没有区别。
而对象存储架构在底层硬件之上的系统,和两者完全不同。(下文会详细介绍系统架构)
块存储,操作对象是磁盘。存储协议是SCSI、iSCSI、FC。
以 SCSI 为例,主要接口命令有 Read/Write/Read Capacity/Inquiry 等等。
文件存储,操作对象是文件和文件夹。存储协议是NFS、SAMBA(SMB)、POSIX等。
以NFS(大家应该都用过“网上邻居”共享文件吧?就是那个)为例,文件相关的接口命令包括:READ/WRITE/CREATE/REMOVE/RENAME/LOOKUP/ACCESS 等等,文件夹相关的接口命令包括:MKDIR/RMDIR/READDIR 等等。
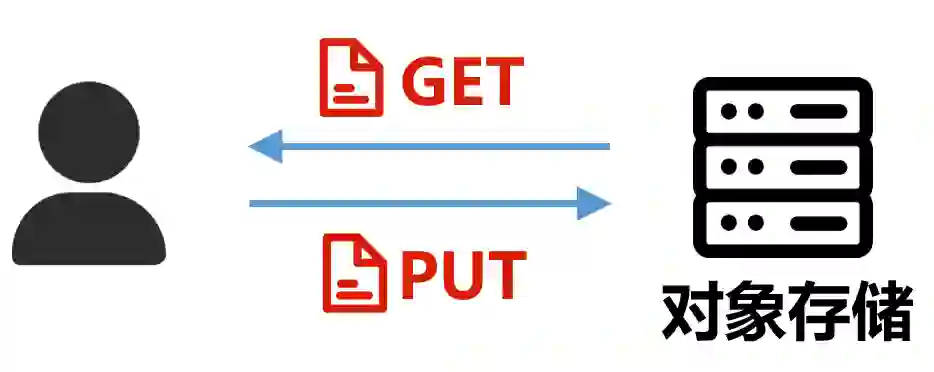
对象存储,主要操作对象是对象(Object)。存储协议是S3、Swift等。
以 S3 为例,主要接口命令有 PUT/GET/DELETE 等。
看出来了吧?接口命令非常简洁,没有那种目录树的概念。
在对象存储系统里,你不能直接打开/修改文件,只能先下载、修改,再上传文件。(如果大家用过百度网盘或ftp服务,一定可以秒懂。)
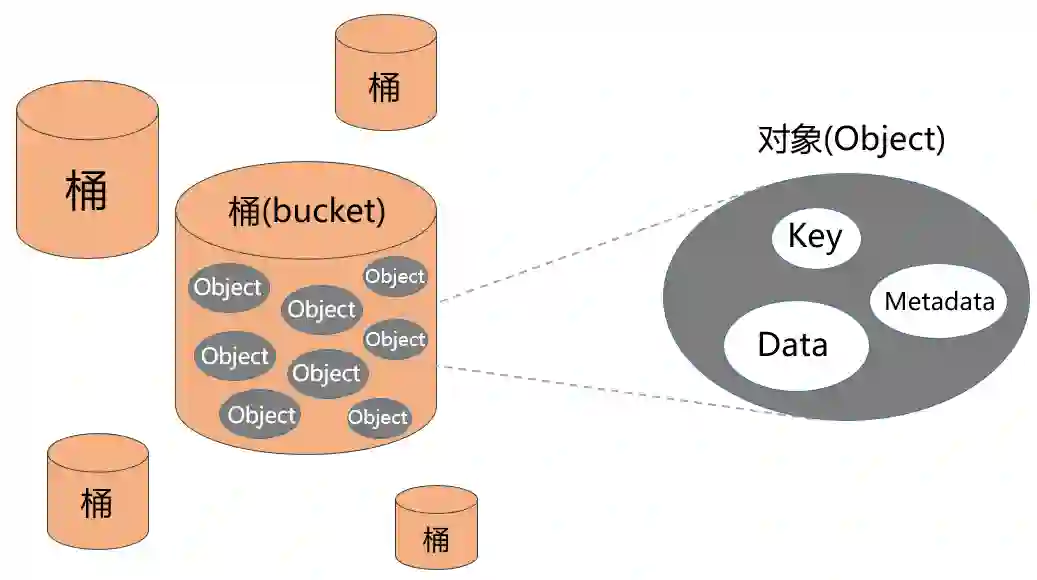
对象存储呈现出来的是一个“桶”(bucket),你可以往“桶”里面放“对象(Object)”。这个对象包括三个部分:Key、Data、Metadata。
可以理解文件名,是该对象的全局唯一标识符(UID)。
Key是用于检索对象,服务器和用户不需要知道数据的物理地址,也能通过它找到对象。这种方法极大地简化了数据存储。
看上去就是一个URL网址。如果该对象被设置为“公开”,所有互联网用户都可以通过这个地址访问它。
Metadata叫做元数据,它是对象存储一个非常独特的概念。
元数据有点类似数据的标签,标签的条目类型和数量是没有限制的,可以是对象的各种描述信息。
举个例子,如果对象是一张人物照片,那么元数据可以是姓名、性别、国籍、年龄、拍摄地点、拍摄时间等。
在传统的文件存储里,这类信息属于文件本身,和文件一起封装存储。而对象存储中,元数据是独立出来的,并不在数据内部封装。
元数据的好处非常明显,可以大大加快对象的排序,还有分类和查找。
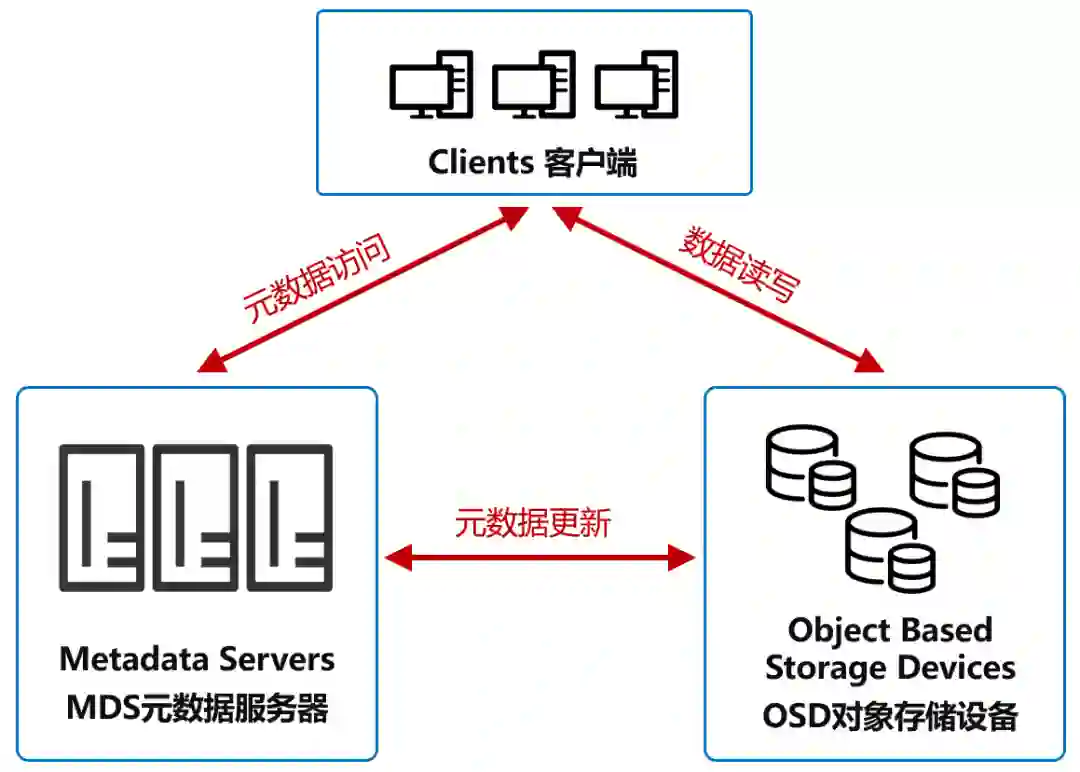
对象存储的架构是怎样的呢?如下图所示,分为3个主要部分:
这是对象存储的核心,具有自己的CPU、内存、网络和磁盘系统。它的主要功能当然是存储数据。同时,它还会利用自己的算力,优化数据分布,并且支持数据预读取,提升磁盘性能。
它控制Client和OSD的交互,还会管理着限额控制、目录和文件的创建与删除,以及访问控制权限。
根据上面的架构可以看出,对象存储系统可以是一个提供海量存储服务的分布式架构。
对象存储的容量是EB级以上。EB有多大?大家的硬盘普遍是TB级别。1EB约等于1TB的一百万倍,请自行脑补...
对象存储的所有业务、存储节点采用分布式集群方式工作,各功能节点、集群都可以独立扩容。从理论上来说,某个对象存储系统或单个桶(bucket),并没有总数据容量和对象数量的限制。
换句话说,只要你有足够的money,服务商就可以不停地往架构里增加资源,这个存储空间就是无限的。
你可以根据自身需求购买相应大小的对象存储空间。如果需要调整大小,也是支持弹性伸缩的,你不要进行数据迁移和人工干预。
对象存储采用了分布式架构,对数据进行多设备冗余存储(至少三个以上节点),实现异地容灾和资源隔离。
根据云服务商的承诺,数据可靠性至少可以达到99.999999999%(不用数了,一共11个9)。这意味着,1000亿个文件里,每月最多只会有1个文件发生数据丢失。这比一个人被陨石击中的概率还要小143000倍。
数据访问方面,所有的桶和对象都有ACL等访问控制策略,所有的连接都支持SSL加密,OBS系统会对访问用户进行身份鉴权。因为数据是分片存储在不同硬盘上的,所以即使有坏人偷了硬盘,也无法还原出完整的对象数据。
很多人把它比喻为“代客泊车”,你只需要把车扔给他,他给你一个凭证,你通过凭证取车就可以了。你不需要知道车库的布局,也不需要自己去费力停放。
数据的存取方法也非常灵活多样。除了前面说的可以使用网页(基于http)直接访问之外,大部分云服务提供商都有自己的图形化界面客户端工具,用户存取数据就像用网盘一样。
事实上,大部分的对象存储需求,并不是个人用户买来当网盘用,而且企业或政府用户用于系统数据存储。例如网站、App的静态图片、音频、视频,还有企业系统的归档数据等。
像这种数据,是通过程序内部的接口调用的。对象存储提供开放的REST API接口。程序员在开发应用时,直接把存储参数写进代码,就可以通过API接口调用对象存储里的数据。相比文件存储那一串串的路径,对象存储要方便很多。
目前国内有大量的云服务提供商,他们把对象存储当作云存储在卖。
他们通常会把存储业务分为3个等级,即标准型、低频型、归档型。对应的应用场景如下:
Web应用的崛起、社交需求的刺激,极大地推动了多媒体内容的创作和分享。人们开始上传大量的照片、音乐、视频,加剧了数据量的爆发。
此外,信息技术的发展、企业数字化的落地,也产生了大量的数据,不断吞食着存储资源。
举个例子大家就明白了。我们经常做的excel表格,姓名、身高、体重、年龄、性别,这种用二维表结构可以进行逻辑表达的数据,就是结构化数据。
而图像、音频、视频、word文章、演示胶片这样的数据,就是非结构化数据。
根据此前的预测,到2020年(也就是今年),全球数据总量的80%,将是非结构化数据。
面对这两大趋势,因为本身技术和架构的限制,DAS、SAN和NAS无法进行有效应对。
虽然我们说对象存储是新网红,但实际上它诞生的时间并不算短。早在1996年,美国卡内基梅隆大学就将对象存储作为一个研究项目提出来。随后,加州大学伯克利分校也有推出类似的项目。
2002年,Filepool公司推出了基于内容可寻址技术的Centera系统,算是比较早期的对象存储系统。
2006年,美国Amazon公司发布AWS S3(Simple Storage Service)服务,正式将对象存储作为一项云存储服务,引入云计算领域,从此开启了对象存储的黄金时代。
说了半天,对象存储到底是一个什么样的技术?它和块存储、文件存储有什么区别?
首先,第一点,千万不要去看百度百科上面“对象存储”的定义,否则,你可能会怀疑人生。
想要了解对象存储,最简单直接的办法,就是从实际使用体验上进行对比。
对象存储的底层硬件介质,依然是硬盘,和块存储、文件存储没有区别。
而对象存储架构在底层硬件之上的系统,和两者完全不同。(下文会详细介绍系统架构)
块存储,操作对象是磁盘。存储协议是SCSI、iSCSI、FC。
以 SCSI 为例,主要接口命令有 Read/Write/Read Capacity/Inquiry 等等。
文件存储,操作对象是文件和文件夹。存储协议是NFS、SAMBA(SMB)、POSIX等。
以NFS(大家应该都用过“网上邻居”共享文件吧?就是那个)为例,文件相关的接口命令包括:READ/WRITE/CREATE/REMOVE/RENAME/LOOKUP/ACCESS 等等,文件夹相关的接口命令包括:MKDIR/RMDIR/READDIR 等等。
对象存储,主要操作对象是对象(Object)。存储协议是S3、Swift等。
以 S3 为例,主要接口命令有 PUT/GET/DELETE 等。
看出来了吧?接口命令非常简洁,没有那种目录树的概念。
在对象存储系统里,你不能直接打开/修改文件,只能先下载、修改,再上传文件。(如果大家用过百度网盘或ftp服务,一定可以秒懂。)
对象存储呈现出来的是一个“桶”(bucket),你可以往“桶”里面放“对象(Object)”。这个对象包括三个部分:Key、Data、Metadata。
可以理解文件名,是该对象的全局唯一标识符(UID)。
Key是用于检索对象,服务器和用户不需要知道数据的物理地址,也能通过它找到对象。这种方法极大地简化了数据存储。
看上去就是一个URL网址。如果该对象被设置为“公开”,所有互联网用户都可以通过这个地址访问它。
Metadata叫做元数据,它是对象存储一个非常独特的概念。
元数据有点类似数据的标签,标签的条目类型和数量是没有限制的,可以是对象的各种描述信息。
举个例子,如果对象是一张人物照片,那么元数据可以是姓名、性别、国籍、年龄、拍摄地点、拍摄时间等。
在传统的文件存储里,这类信息属于文件本身,和文件一起封装存储。而对象存储中,元数据是独立出来的,并不在数据内部封装。
元数据的好处非常明显,可以大大加快对象的排序,还有分类和查找。
对象存储的架构是怎样的呢?如下图所示,分为3个主要部分:
这是对象存储的核心,具有自己的CPU、内存、网络和磁盘系统。它的主要功能当然是存储数据。同时,它还会利用自己的算力,优化数据分布,并且支持数据预读取,提升磁盘性能。
它控制Client和OSD的交互,还会管理着限额控制、目录和文件的创建与删除,以及访问控制权限。
根据上面的架构可以看出,对象存储系统可以是一个提供海量存储服务的分布式架构。
对象存储的容量是EB级以上。EB有多大?大家的硬盘普遍是TB级别。1EB约等于1TB的一百万倍,请自行脑补...
对象存储的所有业务、存储节点采用分布式集群方式工作,各功能节点、集群都可以独立扩容。从理论上来说,某个对象存储系统或单个桶(bucket),并没有总数据容量和对象数量的限制。
换句话说,只要你有足够的money,服务商就可以不停地往架构里增加资源,这个存储空间就是无限的。
你可以根据自身需求购买相应大小的对象存储空间。如果需要调整大小,也是支持弹性伸缩的,你不要进行数据迁移和人工干预。
对象存储采用了分布式架构,对数据进行多设备冗余存储(至少三个以上节点),实现异地容灾和资源隔离。
根据云服务商的承诺,数据可靠性至少可以达到99.999999999%(不用数了,一共11个9)。这意味着,1000亿个文件里,每月最多只会有1个文件发生数据丢失。这比一个人被陨石击中的概率还要小143000倍。
数据访问方面,所有的桶和对象都有ACL等访问控制策略,所有的连接都支持SSL加密,OBS系统会对访问用户进行身份鉴权。因为数据是分片存储在不同硬盘上的,所以即使有坏人偷了硬盘,也无法还原出完整的对象数据。
很多人把它比喻为“代客泊车”,你只需要把车扔给他,他给你一个凭证,你通过凭证取车就可以了。你不需要知道车库的布局,也不需要自己去费力停放。
数据的存取方法也非常灵活多样。除了前面说的可以使用网页(基于http)直接访问之外,大部分云服务提供商都有自己的图形化界面客户端工具,用户存取数据就像用网盘一样。
事实上,大部分的对象存储需求,并不是个人用户买来当网盘用,而且企业或政府用户用于系统数据存储。例如网站、App的静态图片、音频、视频,还有企业系统的归档数据等。
像这种数据,是通过程序内部的接口调用的。对象存储提供开放的REST API接口。程序员在开发应用时,直接把存储参数写进代码,就可以通过API接口调用对象存储里的数据。相比文件存储那一串串的路径,对象存储要方便很多。
目前国内有大量的云服务提供商,他们把对象存储当作云存储在卖。
他们通常会把存储业务分为3个等级,即标准型、低频型、归档型。对应的应用场景如下:
标准类型:移动应用 | 大型网站 | 图片分享 | 热点音视频
低频访问类型:移动设备 | 应用与企业数据备份 | 监控数据 | 网盘应用
归档类型:各种长期保存的档案数据 | 医疗影像 | 影视素材
根据估算,目前全球互联网70%以上的热点数据是保存在对象存储系统中的。
对象存储虽然看上去很好很强大,但也不是没有缺点。它最大的缺点,和它的工作模式有关。
它是那种把整个数据取出来,修改,再放回去的模式,不支持直接在存储上修改,哪怕只是加一行数据,都不行。所以,它不适合存储需要频繁擦写的数据(例如关系型数据库的数据)。
在数据的一致性保证上,对象存储也存在先天的不足。不过,据说目前技术上已经有了很大改进。
好啦,以上就是关于对象存储的全部内容。感谢大家的耐心观看,如果觉得有所收获,请记得帮小枣君点赞、转发!我们下期再见!