Nature重磅:深度强化学习“落地”高空,全自动环境监测或成现实

在电影《飞屋环游记》中,男主人公用一大堆气球将自己的小木屋带上天空,并通过增减气球、手动施力来改变气球的飞行方向,去实现他未曾实现的梦想......
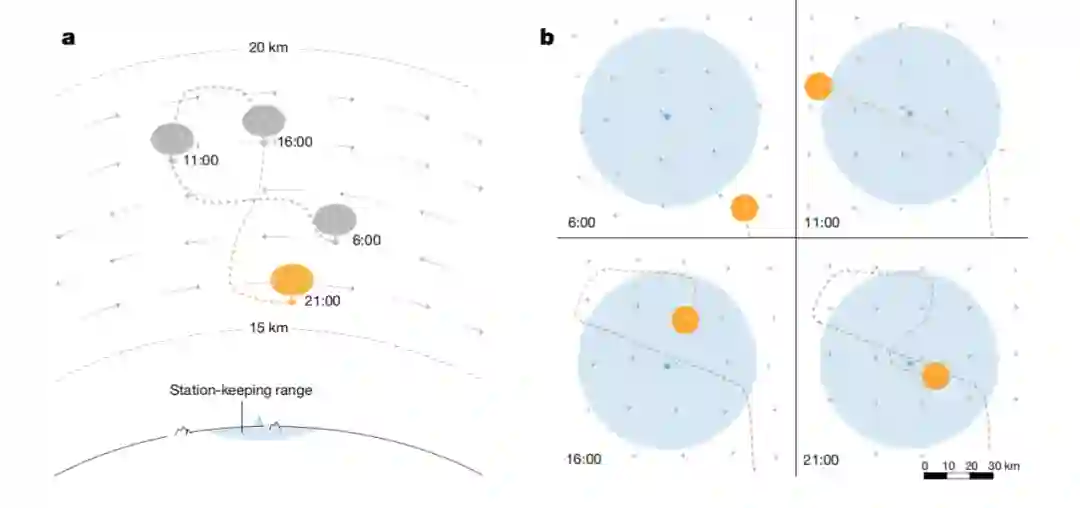
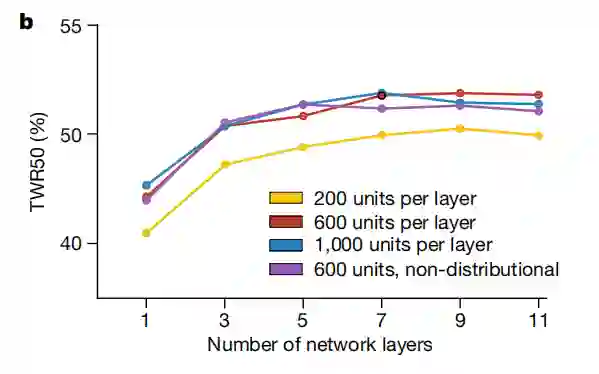
当然,电影世界具有一定的幻想色彩。但是,如今还真有这样一种巨型气球,它虽然不能带着小木屋飞上天空,却更加智能、用处更大——让全自动环境实时监测成为可能。






登录查看更多
相关内容

Arxiv
12+阅读 · 2020年6月10日





相关VIP内容
相关资讯
相关论文
Arxiv
12+阅读 · 2020年6月10日