哈工大SCIR在CoNLL-2019国际跨框架语义分析评测中取得第一名
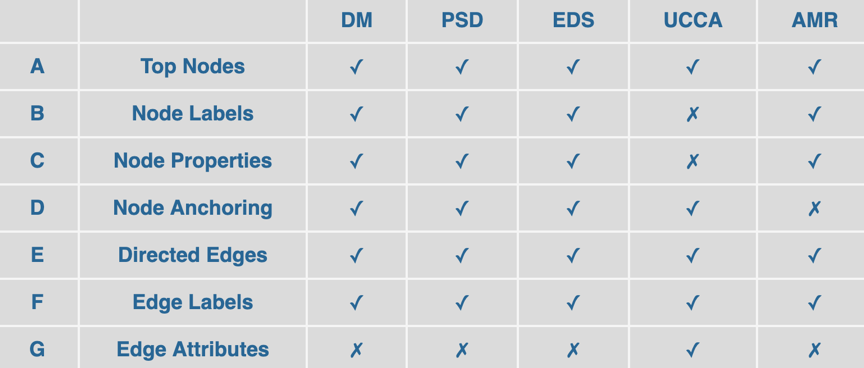
图中的结点与句子中的词一一对应(DM、PSD)
图中存在虚结点,其与句子的词构成一对多(UCCA)、或者多对多的对应关系(EDS)
-
图中存在虚结点,但是和句子的词之间没有显式的对齐关系(AMR)
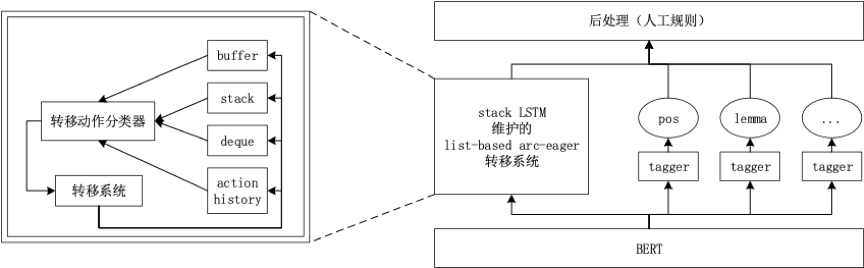
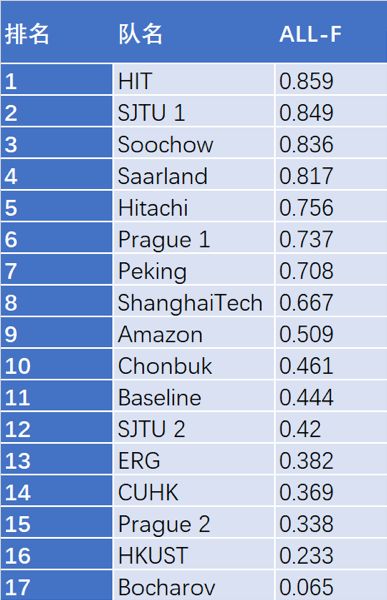
排名下载链接:http://svn.nlpl.eu/mrp/2019/public/results.ods
本期责任编辑:崔一鸣
本期编辑:赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编:张伟男,丁效
执行编辑:李家琦
责任编辑:张伟男,丁效,崔一鸣,李忠阳
编辑:赖勇魁,王若珂,李照鹏,冯梓娴,顾宇轩
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公众号:”哈工大SCIR” 。

登录查看更多
相关内容

CoNLL(Conference on Computational Natural Language Learning)是一个顶级会议,每年由SIGNLL(ACL的自然语言学习特别兴趣小组)组织。官网链接:https://www.conll.org/
Arxiv
3+阅读 · 2019年6月6日
Arxiv
5+阅读 · 2018年9月6日





相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年6月6日
Arxiv
5+阅读 · 2018年9月6日