【前沿】从十篇热门学术论文看计算机视觉的未来

【导读】如果你没有赶上CVPR 2019,不用担心。下面是大家都在谈论的top10论文,涵盖DeepFakes,面部识别、重建等等。
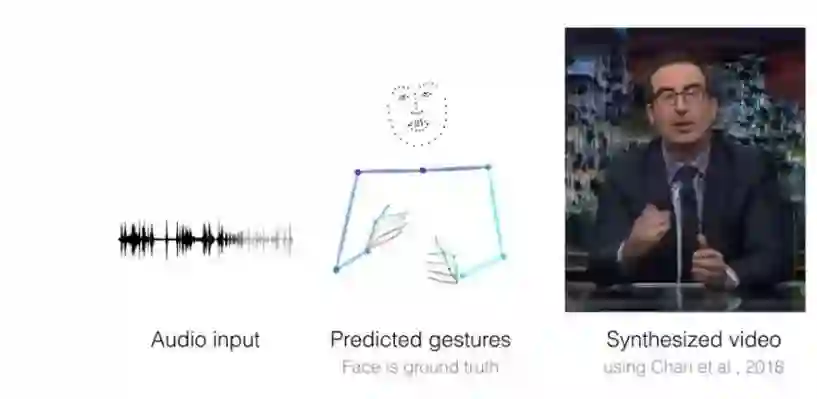
1.学习会话手势的个人风格
完整论文: https://www.profillic.com/paper/arxiv:1906.04160
TLDR:给定音频语音输入,可以生成比较真实的手势来配合声音,并合成对应的说话者的视频。
使用的模型/架构:语音到手势的翻译模型。卷积音频编码器对二维频谱图进行采样并将其转换为一维信号。然后,用翻译模型G预测相应时间的二维手势。这相对于真实手势的L1回归产生了一个训练信号,而一个对抗的判别器D则确保预测的动作既具有时间一致性,又符合说话者的风格 。
模型精度:研究人员定性地将语音和手势翻译结果与基准模型和实际标注的手势序列进行对比(作者给出的表显示,提出模型的损失更低,正确估计的关键点的比率[PCK]更高) 。
使用的数据集:通过搜索youtube,收集的特定说话者的手势数据集。总共有144小时的视频。他们将数据分成80%的训练集、10%的验证集和10%的测试集,这样每个视频只出现在一个数据集的划分中。
2.纹理神经网络阿凡达
完整论文:https://www.profillic.com/paper/arxiv:1905.08776
TLDR:研究人员提出了一种学习全身神经表征的系统,即深层网络,它可以为不同的身体姿势和摄像机位置生成一个人的全身效果图。是一种没有重建几何的神经自由视角渲染的人体表征。
使用的模型/架构:纹理神经表征系统的概述。模型输入的是一组身体关节的位置点,通过一个全卷积网络(图中的Generator)来生成身体部位坐标和身体部位分配的映射堆栈。然后使用这些堆栈在坐标堆栈指定的位置处对身体纹理进行采样映射,并使用身体部位分配的堆栈所指定的权重来生成RGB图像。 此外,最后的身体部位分配的堆栈映射对应于背景概率。在学习过程中,将图像掩膜和RGB图像与真实图像进行比较,并通过采样操作将产生的损失反向传播到全卷积网络及纹理上来更新权重。
模型精度:在结构自相似性(SSIM)方面优于其他两个,在Frechet-Inception距离(FID)方面逊于V2V。
使用的数据集:
来自CMU Panoptic数据集的2个子集。
利用七架摄像机,采用30度进行扫描,拍摄我们自己的三名受试者的多视图序列视频。
来自另一篇论文和Youtube视频的两个单目短序列视频。

3. DSFD:双重人脸检测器
完整论文:https://www.profillic.com/paper/arxiv:1810.10220
TLDR:作者提出了一种新的人脸检测网络,该网络具有三个贡献,分别解决了人脸检测的三个关键方面,包括更好的特征学习、渐进损失设计和基于锚点(anchor)匹配的数据增强。
使用的模型/架构:DSFD框架在一个前馈VGG/ResNet网络后端之上使用了一个特征增强模块,利用原始特征生成增强特征(a),同时使用两个损失层,第一个shot的渐进锚点损失(PAL)用于原始特征,第二个shot的渐进锚点损失(PAL)用于增强特征。
模型精度:在许多基准数据集上的实验:在WIDER FACE和FDDB上的结果证明了DSFD(双重人脸检测器)相对于最先进的人脸检测器(如PyramidBox 和SRN)的优越性。
使用的数据集:WIDER FACE和FDDB

4. GANFIT:基于生成对抗性网络拟合的高保真三维人脸重建
完整论文:https://www.profillic.com/paper/arxiv:1902.05978
TLDR:论文提出的深度拟合方法可以从一张图像中重建出高质量的纹理和几何结构,具有精确的身份恢复能力。论文中重建的插图均由一个长度为700个浮点数向量表示,并且没有经过任何特殊效果渲染。(描述纹理由模型重建,而且没有直接从图像中获取任何特征)
使用的模型/架构:3D人脸重建由可微分渲染器渲染。代价函数主要是通过预先训练的人脸识别网络上的特定特征来构造的,并通过梯度下降优化将误差传回隐藏参数进行优化。端到端可微分体系结构使我们能够使用计算廉价并且可靠的一阶导数来进行优化,从而使得将深度网络作为生成器(如:统计模型)或代价函数成为可能。
模型精度:在MICC数据集上网格的精度表征为点到面的距离。该表记录了平均误差(Mean)和标准差(Std.)为所提议模型的最低值。
使用的数据集:MoFA-Test, MICC,LFW数据集,BAM数据集

5. DeepFashion2:一个可以用于服装图像检测,姿态估计,分割以及重识别的基准数据集
完整论文: https://www.profillic.com/paper/arxiv:1901.07973
TLDR:Deepfashion2为服装图像的检测、姿态估计、分割和重识别提供了一个新的基准数据集。
使用的模型/架构:Match R-CNN包含三个主要组件,包括特征提取网络(FN)、感知网络(PN)和匹配网络(MN)。
模型精度:Match R-CNN,在提供实际标注的边界框的情况下,获得小于0.7的top20精确度,说明该基准数据集具有挑战性。
使用的数据集:DeepFashion2数据集,包含来自商业购物商店和消费者的13种流行服装类别,491K张不同的图像

6.Inverse Cooking:从食物图像生成食谱
完整论文: https://www.profillic.com/paper/arxiv:1812.06164
TLDR:Facebook的研究人员使用人工智能从食物图片中生成食谱
使用的模型/架构:食谱生成模型——该模型用图像编码器提取图像特征。配料由配料解码器进行预测,利用配料编码器将配料编码为配料词嵌入向量。烹饪指令解码器通过处理图像嵌入、配料嵌入和词库来生成菜谱标题和烹饪步骤序列。
模型精度:用户研究结果表明,他们的系统相对于最先进的图像到食谱检索方法的优势。(优于人类基准和基于检索的系统,F1为49.08%) (较好F1得分表示模型的误报率和漏报率都很低)
使用的数据集:采用在大型Recipe1M数据集来评估整个系统。
Pita:AI研习社也对该项目进行了介绍,欢迎扫码查看~

https://ai.yanxishe.com/page/blogDetail/13524
7. ArcFace:用于深度人脸识别的附加角边界损失
完整论文: https://arxiv.org/pdf/1801.07698.pdf
TLDR:ArcFace可以获得更有辨别力的深层特征,并可以重现在MegaFace挑战中显示出最先进的性能。
使用的模型/架构:为了增强类内紧密性以及类间差异,研究人员提出了附加角边缘损失(ArcFace)——在样本和中心之间插入测地距离边界。这是为了提高人脸识别模型的识别能力。
模型精度:综合实验报告显示,ArcFace始终优于最先进的模型!
使用的数据集:采用CASIA、VGGFace2、MS1MV2和DeepGlint-Face(包括MS1M-DeepGlint和Asian-DeepGlint)作为训练数据,与其他方法进行公平比较。使用的其他数据集有, LFW, CFP-FP, AgeDB-30, CPLFW, CALFW, YTF, MegaFace, IJB-B, IJB-C,Trillion-Pairs,iQIYI-VID

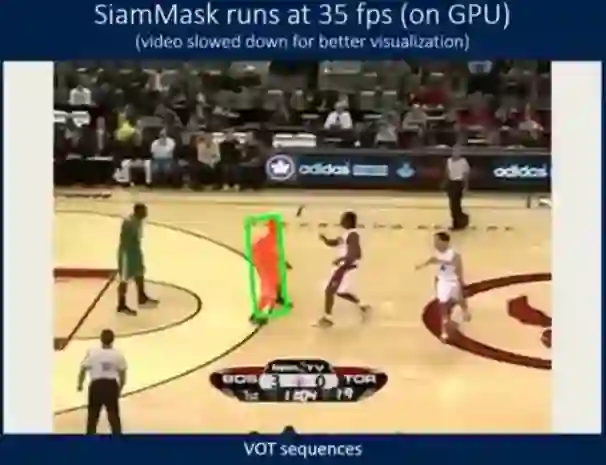
8.快速在线目标跟踪和分割:一个统一的方法
完整论文: https://www.profillic.com/paper/arxiv:1812.05050
TLDR:该方法被称为SiamMask,通过增加目标二值分割的损失项,改进了常用的全卷积Siamese目标跟踪方法的离线训练过程。
使用的模型/架构:SiamMask针对视觉跟踪任务与视频目标分割任务的交集,实现了很高的实用便用性。与传统的目标跟踪器一样,它依赖于一个简单的边界框初始化并在线运行。与ECO等最先进的跟踪器不同,SiamMask能够生成二元分割掩模,从而更准确地描述目标对象。SiamMask有两种变体:三分支体系结构和两分支体系结构(更多细节见论文)
模型精度:本文给出了SiamMask对VOT(视觉目标跟踪)和DAVIS(密集注释视频分割)序列的定性结果。不仅速度很快,SiamMask即使在干扰物存在的情况下也能产生精确的分割掩模。
使用的数据集:VOT2016、VOT-2018、DAVIS-2016、DAVIS-2017和YouTube-VOS
9. 通过运动重建的反向结构再现实际场景图
完整论文: https://www.profillic.com/paper/arxiv:1904.03303
TLDR:微软的一组科学家和学术伙伴从点云重建了一个场景的彩色图像。
使用的模型/架构: 我们的方法基于级联U型网络,该网络以从特定视点的点渲染的2D多通道图像为输入,其中包含点深和可选颜色和SIFT描述子,并从该视点输出场景的彩色图像。
该网络有3个子网络 –VISIBNET、COARSENET和REFINENET。他们网络的输入是一个多维nD数组。论文研究了网络的变体,其中输入是深度、颜色和SIFT描述子的不同子集。这3个子网络具有相似的体系结构。它们都是带有对称跳连接的编码器和解码器层的U型网络。解码器层末尾的额外层用于协助处理高维输入。
模型精度:论文证明了利用稀疏三维点云模型存储的有限信息可以重建出高质量的图像 。
使用的数据集:利用来自NYU2和MegaDepth数据集的500k+多视图图像生成的700+张室内、室外Sfm重建图来进行训练。

10. 空间自适应归一化的语义图像合成
完整论文: https://www.profillic.com/paper/arxiv:1903.07291
TLDR: 把涂鸦变成惊人的,逼真的照片景观!英伟达的研究利用生成对抗网络来创建高度现实的场景。艺术家们可以使用画笔和油漆桶工具来设计他们自己的景观,比如河流、岩石和云。
使用的模型/架构:
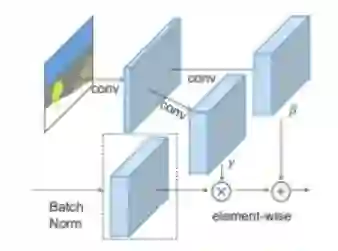
在SPADE网络中,掩模首先投影到一个嵌入空间,然后生成卷积调制参数γ和β。与之前的条件归一化方法不同,γ和β不是向量,而是表示空间维度的张量。γ和归一化激活值相乘,然后与β相加(经查看原论文,感觉原博文这个地方表述有误,如有问题,请校对、审阅者更改),并输入到归一化激活函数element-wise中。
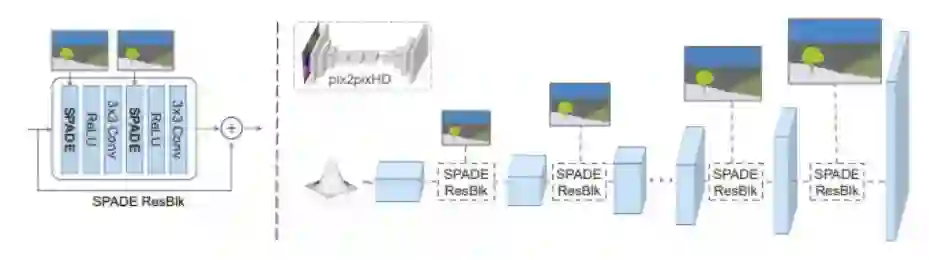
在SPADE生成器中,每个归一化层都使用分割掩模来调节该网络层的激活状态。(左)一个SPADE残差结构。(右)该生成器包含一系列SPADE残差块和上采样层。
模型精度:我们的网络结构通过去除常用的图像到图像转换网络的下采样层,以更少的参数获得更好的性能。我们的方法成功地在从动物到体育活动的各种场景中生成逼真的图像。
使用的数据集:COCO-Stuff, ADE20K, Cityscapes, Flickr Landscape

via https://hackernoon.com/top-10-papers-you-shouldnt-miss-from-cvpr-2019-deepfake-facial-recognition-reconstruction-and-more-d5ly3q1w
来源:AI科技评论

【重要通知】关于开展2019年度中国自动化学会会士候选人提名工作的通知
【重要通知】关于2019年度CAA科学技术奖励推荐工作的通知
【重要通知】关于开展2019年度中国自动化与人工智能创新团队奖推荐工作的通知
【CAA】中国自动化学会选举产生第十一届理事会领导机构(内附名单)
热烈祝贺中国自动化学会常务理事、火箭军工程大学教授胡昌华荣获中共中央军委通令记功
地址:北京市海淀区中关村东路95号
邮编:100190
电话:010-82544542(综合)
010-62522472(会员)
010-62522248(学术活动)
010-62624980(财务)
传真:010-62522248
邮箱:caa@ia.ac.cn
官方微信公众号(英文)
名称:CAA OFFICIAL
微信号:caaofficial

会员微信公众号
名称:CAA会员服务
微信号:caa-member







