从CVPR2020可以看出哪些人工智能的研究热点和未来趋势?
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
知乎高质量回答
一、作者:ICOZ
Chi Zhang, PhD in ML & CV, NTU
https://www.zhihu.com/question/394503940/answer/1284207939
据我观察,Parametrized optimization 会是一个有意思的方向,推荐Brandon Amos 的CVPR 2020 workshop talk On differentiable optimization for control and vision.
简单来说,就是优化问题里嵌入一个优化问题,后层的layer的input是这个嵌入的optimization问题的solution,然后还能实现梯度传播。
这种模型的好处在于我们可以更好的通过一个sub optimization problem来表达我们的优化需求,植入到网络学习中。这个嵌入的问题可以是个convex problem, 也可以是一个non-convex problem,核心问题就是gradient怎么流过这个embedded optimization problem。
列举几个应用场景和技术的例子。
1.一个bi-level optimization task,像MAML。目的是学习一个好初始化网络,让他可以很快的被finetune从而适应新的task。内部的optimization problem就是通过finetune layer来适应新的task,外部的优化问题是学习网络的初始化weight,早期解决梯度传播的技术是二阶导数,后来也有用implicit gradient来改进。
2. 一个graph matching问题,假如我们没有node correspondence的信息,但是又想基于matching的结果来进一步学习(比如学习node feature),怎么实现?我们首先要求解一个matching的optimization problem,这样就有个correspondence的信息,然后再基于matching的结果做运算。
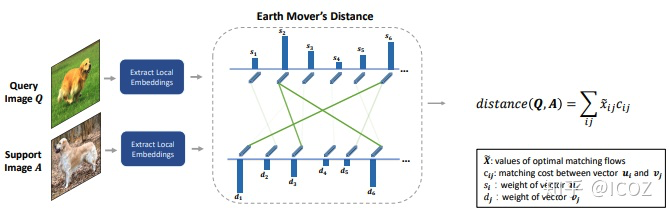
比如在我最近的一篇工作DeepEMD: Differentiable Earth Mover's Distance for Few-Shot Learning,用EMD作为distance metric来求解structured representations之间的相似度做分类,内部的优化问题就是求解optimal matching flow (一个convex problem),外部的optimization problem是学习CNN里的feature。
也可以用组合优化的技术实现类似的目的,比如 Deep Graph Matching via Blackbox Differentiation of Combinatorial Solvers
3. Brandon的talk里也给了一个例子,假如我们做multi label的分类问题,有K正确的class。sigmod 和softmax都不是特别适用,那怎么办?用optimization& constraint 的形式表达我们想要的(如图),从而用这么一个非closed-form的表达来计算loss,encourage K个class同时响应。

目前有几个开源的工作我觉得很好,不用自己写复杂的梯度传播过程就可以实现上述的功能。
-
比如QPTH:A fast and differentiable QP solver for PyTorch,一个differentiable的QP solver。 -
Differentiable Convex Optimization Layers,QPTH的作者Brandon Amos在facebook参与的工作,把QP问题拓展到更广泛的convex场景,傻瓜式表达就可以定义问题。 -
Differentiation of Blackbox Combinatorial Solvers,一个differentiable的组合优化solver,很适合用来做graph matching,也已经有工作这么做了。
二、作者:丶favor
厦门大学 计算机技术硕士在读
https://www.zhihu.com/question/394503940/answer/1267123344
-
self-attention全面替代卷积将成为研究热点。
-
Nas在其他非主流领域即将开始灌水。
-
Nas自身仍存在一些问题,依旧会是热点。
-
相比之下,无监督和自监督学习也会被持续关注。
-
self-attention的剪枝和压缩可能会被做cv的关注。
-
一类dynamic的文章(动态选择推理路径或者卷积核/激活函数)似乎听起来比较实用和划算。
-
多模态pretrained bert遍地开花,但实际上大同小异,尤其是在自监督任务上。未来可能会往end-to-end上面靠,参考pixel-bert。包括video bert估计也要遍地开花一波。
-
目标检测,语义分割有种凉凉的感觉,靠着SOTA度日,AP即使刷到55还是觉得凉凉。。因此Fair的transformer模型会引起关注。
-
多模态领域不限于vqa,image captioning,基本被transformer支配了,未来没有新的insight的话将继续被支配。
-
机器人视觉导航虽然我不太清楚这是个啥,但好像大多数不是best paper就是oral。
-
由于内卷得厉害,很多领域再不出新的数据集就要gg了。
三、作者:Cogito2012
计算机博士生
https://www.zhihu.com/question/394503940/answer/1268566148
谈下我了解的几个方面:
-
3D任务的热度将持续上升。以3D object detection为例,目前rgb+point cloud方案连KITTI这种小数据集的榜单都还没刷饱和,预期单目3D检测以及在nuScenes、BDD等大型自动驾驶数据集上的算法文章会越来越多。
-
不同模态数据和任务的组合越来越多样。比如视频、文本、音频将在captioning,segmentation, prediction,generation,grounding等各种任务上开花。
-
成熟的视觉任务上将出现更多不同于监督学习的文章。比如自监督学习、元学习、强化学习、贝叶斯深度学习、终身学习等machine learning算法在cv任务上的应用。目前来看,自监督学习(self-supervised learning)大有可为。
-
Bert/Transformer等NLP领域的模型,将在更多的CV任务上屠榜,最近fair的DETR就是个很好的风向标。
-
行为/动作识别与分析方面,每年文章无数,但未来将出现更多细粒度动作分析文章,比如mmlab的FineGym数据集满分论文也是个很好的风向标。
推荐阅读:


△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~





