【五分钟学AI】模型融合model ensemble

简单讲是通过对一组独立的单模型(基模型)以某种方式进行组合,以提升整体性能(如稳定性,准确度等指标)的方法。不必过分迷信模型融合,因为在影响结果的因素中,数据≥特征≥模型≥模型(优化,tricks,融合等)。
如果使用一组同质的模型,(如tree base model),称为base learner模型融合;如果使用一组异质的模型,则称为component learner模型融合
01
模型融合有什么用?
通常在数据科学竞争中(如某智慧交通大赛),能取得好名次的小伙伴们,他们通常不仅仅采用一个模型,而是使用模型融合帮助其成绩逼近上限,模型融合还能提升结果的整体稳定性(避免过拟合,提升泛化能力,趋向于通用模型,)。
02
为什么模型整合比单个模型效果好?
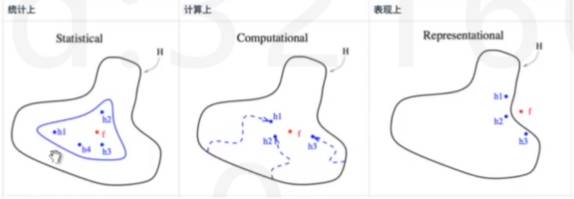
统计上看:不同模型的h的均值更接近真实假设f
计算上看:从多个局部最优解的均值更接近全局最优解
表现上看:真实假设f可能不在已知的假设空间中,更可能多个h外的均值附近
03
常用的模型融合:
Xgboost:
DMLC提供的大杀器,性能优越,表现稳定,几乎垄断了Kaggle比赛的Top榜单。
lightGBM:
微软开源提供,性能略快于Xgboost,可以直接处理字符型的类别变量列,不需要额外变换。
04
模型整合的三种方式:
bagging:(集体智慧)
将训练集自动抽样,产生出构建子模型所需要的子训练集,再进行综合打分得到的结果。典型应用是随机森林。
stacking:(站在巨人的肩膀上,层叠式递进)
有点类似于公司信息汇报,底层提交报告给中层,中层再提交报告,Stacking先用第一层生成决策结果,以多层模型对模式进行识别,在下一层做汇总再提交给下一层进行处理,并最终得出结果。典型应用:神经网络(多层对图像进行挖掘和汇总)。
boosting:(一万小时定律)
一个弱的分类器,通过不断去学习,直到能够通过一系列的基模型去优成一个强大的模型。典型应用为XGBOOST。
免费领课程
即日起至10.29日,打开【python数据分析集训营】链接: http://www.julyedu.com/weekend/python (点击文末“阅读原文”),点击右上角,分享到朋友圈(屏蔽分组无效)并集齐7个赞,即可找微信客服:julyedukefu01,免费领取【python数据分析 升级版】课程!
转发形式如下(需要出现课程名):


课程咨询|微信:julyedukefu01
七月热线:010-82712840

