从28303篇论文看机器学习领域的发展变化

授权转载自 | 数据派THU(DatapiTHU)
作者 | Andrej Karpathy
翻译 | 贾琳 校对 | 闵黎
OpenAI是由诸多硅谷大亨联合建立的人工智能非盈利组织,目的是预防人工智能的灾难性影响,促使人工智能发挥积极作用。本文由OpenAI的研究人员Andrej Karpathy撰写,主要陈述了他通过分析机器学习论文数据库arxiv-sanity里面的28303篇论文里面的高频关键词所发现的有趣的结论。
你是否用过谷歌趋势(Google Trends)(https://trends.google.com/trends/?cat=)呢?它的功能很酷:只需要输入关键词,就可以看到该词的搜索量随时间变化的情况。这个产品在一定程度上启发了我,恰巧我有在过去五年中发表在(arxiv)机器学习论文数据库(http://arxiv-sanity.com/)上的28303篇论文,所以我想,为什么不研究一下该领域发展变化的情况呢?研究结果相当有趣,所以我决定跟大家分享一下。
(注:机器学习是一个包罗万象的领域,本文中相当长的篇幅是对深度学习领域的研究,这也是我最为熟悉的领域)
arxiv的奇点
让我们先来看看提交到arxiv-sanity的所有分类(cs.AI, cs.LG, cs.CV, cs.CL, cs.NE, stat.ML)下的论文总数随时间变化的趋势,如下图所示:
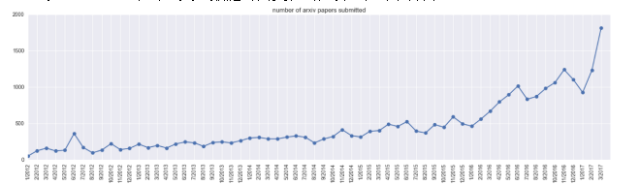
没错,峰值位于2017年3月,这个月这些领域有近2000篇论文提交。这一峰值很可能是某些会议的截稿日期(例如NIPS/ICML)造成的。由于并不是所有人都会将他们的论文上传至arxiv,而且上传比例也在随时间变化而变化,所提交的论文数量并不能完全体现机器学习这一领域的研究规模。不过可以看到,有大量的论文为人所注意、浏览或者阅读。
接下来,我们用这一数字作为分母,看看多少文章包含我们感兴趣的关键词。
深度学习框架
首先,我们关心的是深度学习框架的使用情况。如果在文中任何地方有提到深度学习框架,包括参考书目,都会被记录在案。下图是在2017年3月提交的论文中提到深度学习框架的情况:
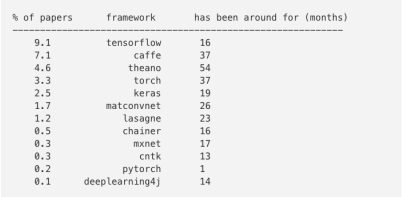
可见2017年3月提交的论文中有约10%提到了TensorFlow。当然不是每篇文章都会写出他们所用的框架,不过如果我们假定提及与否和框架类型无关(即说明框架的文章有相对确定的使用比例)的话,可以推断出该社区大约有40%的用户正在使用TensorFlow(如果算上带TensorFlow后端的Keras框架,数量会更多)。下图是一些常用框架随时间变化的趋势图:
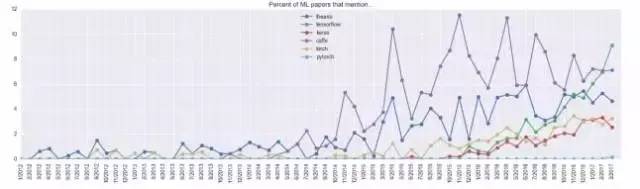
我们可以看到,Theano在很长时间占据主流,后来不再流行;2014年Caffe的发展势头强劲,不过在最近几个月内被TensorFlow取代;Torch(和最近的PyTorch)同样在缓慢稳步发展。它们未来发展的状况会是怎样呢?这是一个有趣的话题,个人认为Caffe和Theano会继续下降,TensorFlow的发展速度则会因为PyTorch的竞争而放缓。
ConvNet模型
常用的ConvNet模型的使用情况又是怎样呢?我们可以在下图看到,ResNets模型异军突起,该模型出现在去年3月发表的9%的论文中。
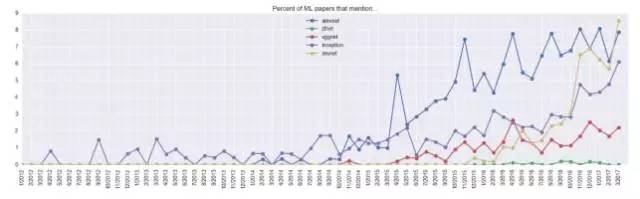
另外,我很好奇在InceptionNet出现之前有谁在讨论inception呢?
优化算法
优化算法方面,Adam一枝独秀,在所有论文中的出现率高达23%!其真正的使用率很难统计,估计会比23%更高,因为很多论文并没有写出他们所使用的优化算法,况且很多关于神经网络的研究并不使用任何此类算法。然而也有可能要下调5%,因为这个词也非常可能是指代作者的名字,而Adam优化算法在2014年12月才被提出。
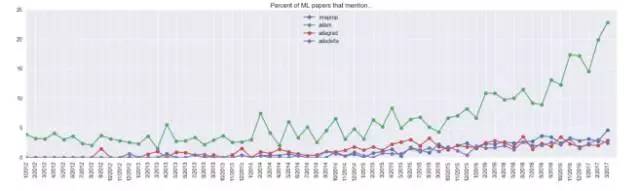
研究者
我关注的另一指标是论文中提及深度学习领域的研究专家的次数(这与引用次数有些类似,但是前者能更好的用0/1指标表达,且能根据文章总数进行标准化):
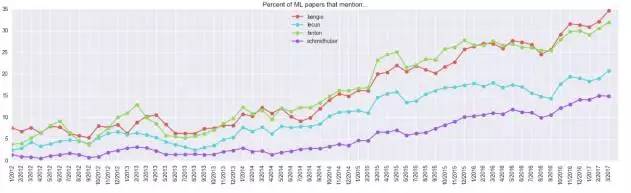
需要注意的是:35%的文章提到了“bengio”,但是学界有两个叫Bengio的专家,分别是Samy Bengio和Yoshua Bengio,图中显示的是两者总和。特别地,Geoff Hinton在30%的最新论文中也被提到,这是一个很高的比例。
关键词研究
最后,本文没有针对关键词进行手动分类,而是关注了论文中最热门和最不热门的关键词 。
最热门关键词
定义最热关键词的方法有很多,本文使用的方法如下:对于在所有论文中出现的一元分词和二元分词,分别计算出去年和去年以前该词的使用次数,并用二者相除得到的比例做排名。排名靠前的关键词是那些一年前影响有限、但是最近一年出现频率极高的词汇,如下表所示(该表是删除重复词以后的结果):
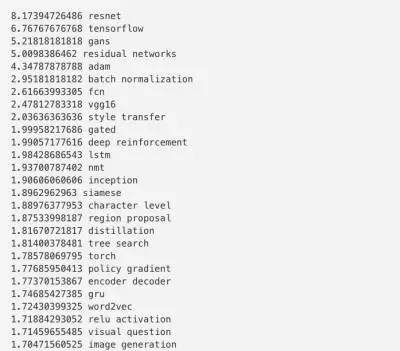
举例来说,ResNet的比例是8.17,该词在一年之前(2016年3月)只在1.044%的论文中出现,但上个月8.53%的论文中都有这个关键词,所以我们有8.53 / 1.044 ~= 8.17的比例。
所以可以看到,在过去一年流行起来的核心技术有:1) ResNets, 2) GANs, 3) Adam, 4) 批规范化(BatchNorm)。
关于研究方向,最火的关键词分别是1)风格转换(Style Transfer), 2) 深度强化学习, 3) 神经网络机器翻译(“nmt”),或许还有 4)图像生成。
整体构架方面,最流行的是1) 全卷积网络(FCN), 2) LSTMs/GRUs, 3) Siamese网络, 和4) 编码-解码器网络。
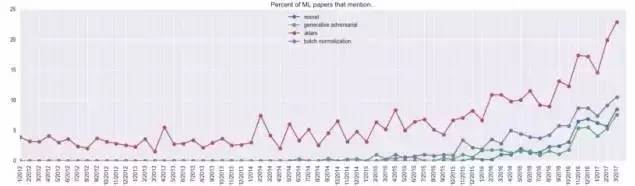
最“过时”关键词
相反的,过去一年不再流行的关键词有哪些呢?如下表所示:

我并不确定“fractal”的含义,不过大体上看,贝叶斯非参数统计似乎不那么流行了。
结论
所以,是时候提交应用全卷积网络、编码-解码器、批规范化、ResNet、Gan来做风格转换,用Adam来优化你的论文了。嘿,这听起来也不是很离谱嘛:)

戳阅读原文了解更多!
原文链接:https://medium.com/@karpathy/a-peek-at-trends-in-machine-learning-ab8a1085a106

关于转载
如需转载,请在开篇显著位置注明作者和出处(转自:大数据文摘 | bigdatadigest),并在文章结尾放置大数据文摘醒目二维码。无原创标识文章请按照转载要求编辑,可直接转载,转载后请将转载链接发送给我们;有原创标识文章,请发送【文章名称-待授权公众号名称及ID】给我们申请白名单授权。未经许可的转载以及改编者,我们将依法追究其法律责任。联系邮箱:zz@bigdatadigest.cn。
点击图片阅读
播报 | 腾讯早已不是你认识的企鹅,这些年如何深入硅谷成为顶级投资公司







