最新《深度学习序列标记》综述论文,16页pdf134篇参考文献

序列标记是一个基础性研究问题,涉及词性标记、命名实体识别、文本分块等多种任务。尽管在许多下游应用(如信息检索、问题回答和知识图谱嵌入)中普遍和有效,传统的序列标记方法严重依赖于手工制作或特定语言的特征。最近,深度学习已经被用于序列标记任务,因为它在自动学习实例的复杂特征和有效地产生艺术表现的强大能力。在本文中,我们旨在全面回顾现有的基于深度学习的序列标记模型,这些模型包括三个相关的任务,如词性标记、命名实体识别和文本组块。然后,在科学分类的基础上,结合SL领域中广泛使用的实验数据集和常用的评价指标,系统地介绍了现有的方法。此外,我们还对不同的SL模型进行了深入分析,分析了可能影响SL领域性能和未来发展方向的因素。
https://arxiv.org/abs/2011.06727
序列标记是自然语言处理(NLP)中重要的一种模式识别任务。从语言学的角度来看,语言中最小的意义单位通常被认为是语素,因此每句话都可以看作是语素构成的序列。相应的,NLP领域中的序列标记问题可以将其表述为一种任务,目的是为一类在句子语法结构中通常具有相似角色和相似语法属性的语素分配标签,所分配标签的意义通常取决于特定任务的类型,经典任务的例子有词性标注[71]、命名实体识别(NER)[52]、文本分块[65]等,在自然语言理解中起着至关重要的作用,有利于各种下游应用,如句法解析[81]、关系提取[64]和实体共指解析[78]等,并因此迅速得到广泛关注。
通常,传统的序列标记方法通常基于经典的机器学习技术,如隐马尔科夫模型(HMM)[3]和条件随机字段(CRFs)[51],这些技术通常严重依赖于手工制作的特征(如一个单词是否大写)或特定于语言的资源(如地名词典)。尽管实现了卓越的性能,但对大量领域知识的需求和对特征工程的努力使得它们极难扩展到新的领域。在过去的十年中,深度学习(DL)由于其在自动学习复杂数据特征方面的强大能力而取得了巨大的成功。因此,对于如何利用深度神经网络的表示学习能力来增强序列标记任务的研究已经有了很多,其中很多方法已经陆续取得了[8],[1],[19]的先进性能。这一趋势促使我们对深度学习技术在序列标记领域的现状进行了全面的综述。通过比较不同深度学习架构的选择,我们的目标是识别对模型性能的影响,以便后续研究人员更好地了解这些模型的优缺点。
本综述的目的是全面回顾深度学习在序列标记(SL)领域的最新应用技术,并提供一个全景,以启发和指导SL研究社区的研究人员和从业者快速理解和进入该领域。具体来说,我们对基于深度学习的SL技术进行了全面的调研,并按照嵌入模块、上下文编码器模块和推理模块三个轴进行了科学的分类,系统地总结了目前的研究现状。此外,我们还概述了序列标记领域中常用任务的实验设置(即数据集或评价指标)。此外,我们讨论和比较了最具代表性的模型给出的结果,以分析不同因素和建筑的影响。最后,我们向读者展示了当前基于dll的序列标记方法所面临的挑战和开放问题,并概述了该领域的未来发展方向。
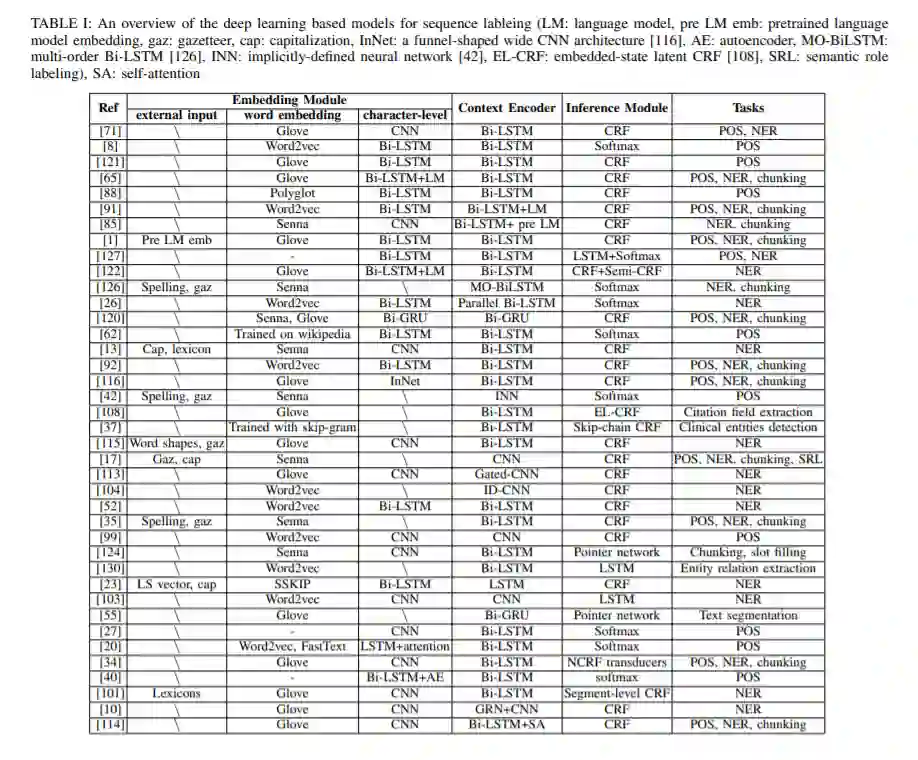
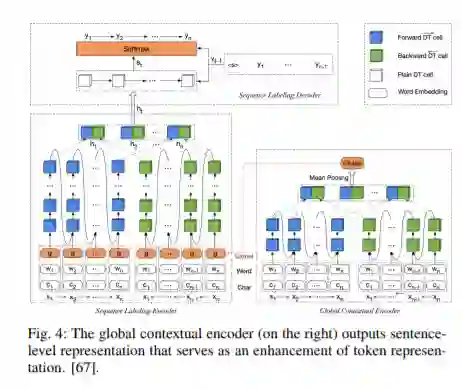
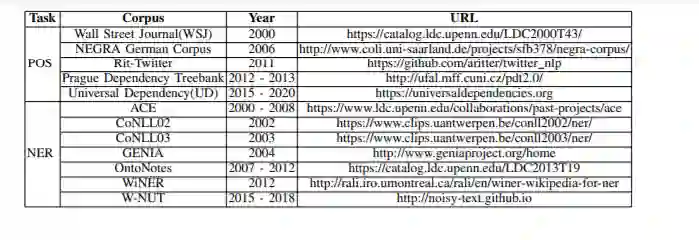
本综述旨在全面回顾深度学习技术在序列标注中的应用,并提供一个全景视图,以便读者对这一领域有一个全面的了解。我们以科学的分类学对文献进行了总结。此外,我们提供了一般研究的序列标记问题的数据集和评价指标的概述。此外,我们还讨论和比较了不同模型的结果,并分析了影响性能的因素和不同架构。最后,我们向读者展示了当前方法面临的挑战和开放问题,并确定了该领域的未来方向。我们希望这项调查能对序列标记感兴趣的研究者、从业者和教育者有所启发和指导。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SLDL” 就可以获取《最新《深度学习序列标记》综述论文,16页pdf134篇参考文献》专知下载链接





