ACL2019 | 中文到底需不需要分词?

AI 科技评论按,本文转载自微信号“香侬科技”,AI 科技评论获授权转载。
近日,香侬科技发表论文Is Word Segmentation Necessary for Deep Learning of Chinese Representations? 探讨中文自然语言处理的最基本问题:中文NLP是否需要分词,得出结论为在深度学习的框架下,“字”的表现几乎总是优于“词”的表现。该论文入选自然语言处理顶级会议ACL19。Yuxian Meng,Xiaoya Li并列为第一作者。
论文链接:
https://arxiv.org/pdf/1905.05526.pdf

概述
长期以来,中文分词(Chinese Word Segmentation, CWS)在NLP的研究中一直受到广泛关注,无论在深度学习兴起之前,还是深度学习兴起以来,对CWS的研究都从未间断。
尽管从形式上看中文的“字”是最小的音义结合体,但是在现代汉语中,“词”才具有表达完整语义的功能,而大部分的“词”都是又多个“字”组合而成。因此,中文分词成为了许多中文NLP任务的第一步。
然而,随着深度学习的发展和计算机算力的提高,对许多中文NLP任务而言,中文分词的必要性似乎在逐渐下降。
那么我们就会问,在基于深度学习神经网络框架下的NLP任务中,到底是“字”好还是“词”好?分词是否还有存在的必要?我们是只需要“字”,还是将“字”与“词”结合使用?其中的道理又是什么呢?在当下,这些问题都缺乏系统性的研究。
本文通过在四个中文NLP任务上的实验和分析,对以上问题得出了初步的结论:
在神经网络框架下进行中文NLP任务,“字”级别的表现几乎总是优于“词”级别的表现。
对大部分中文NLP任务而言,我们不需要进行额外分词(一些必须进行分词的任务除外)。
对部分任务而言,单用“字”可以达到最佳表现,加入“词”反而可能有负作用。
原因可以部分归结为“词”级别的数据稀疏问题、OOV(out-of-vocabulary)问题和过拟合问题。
我们希望可以通过我们的研究抛砖引玉,对未来有关中文分词及其必要性、最佳中文表示单元的研究提供借鉴和启发。
“词”级别单元的不足
尽管“词”级别的模型在很多任务上得到广泛应用,但是“词”级别单元有着以下显著不足:
1.首先,词数据稀疏问题不可避免地导致过拟合,而且大量的OOV限制了模型的学习能力。根据Zipf定律,大多数中文词的出现频率都非常小,在数据集中的占比非常有限,这使得模型不能充分习得数据中的语法、语义知识。
比如,在CTB数据集中,在经过Jieba分词后,不同的词有50266个,其中24458个词仅出现一次,但它们仅占整个数据集的4.0%;有38889个词出现不多于四次,但是它们仅占数据集的10.1%。
这说明,词级别的数据是非常稀疏的,而这容易导致过拟合。另一方面,过多的词会增加大量的OOV,这又限制了模型的学习能力。
2.分词方法不统一与分词效果欠佳。实际上,中文分词在语言学上也是一件困难的事情,存在着不同的分词标准。对于NLP上的中文分词而言,不同的数据集也有不同的分词标准。
比如,对同一句话“姚明进入总决赛”,CTB数据集将其分为“姚明进入总决赛”,而PKU数据集将其分为“姚明进入总决赛”,而根据我们的知识,“姚明”显然是不能分开的。
于是,这种错误的分词可能会对下游的任务产生错误的引导,从而影响模型的效果。
3.分词所带来的收益尚未明确。尽管从直觉上看,“词”所携带的语义信息是比“字”更丰富的,但是这只是站在人的角度,那么对于神经网络而言又如何呢。
我们目前还不清楚对计算机而言,词是否就一定有利于提高表现。
基于以上几点,我们将在四个中文NLP任务上探究“词”级别和“字”级别的表现。
实验
本节在四个中文NLP任务(语言建模、机器翻译、文本分类和句子匹配)上分别对“词”级别和“字”级别的模型进行实验。
语言建模(Language Modeling)
我们首先在语言建模上进行实验。我们使用CTB6数据集,按照标准的8-1-1进行数据集划分。
对于词,我们使用Jieba进行分词。模型是基础的LSTM模型,对同一个模型,我们对学习率、dropout和batch size进行了grid search,使得ppl达到最优。
实验结果如下表:
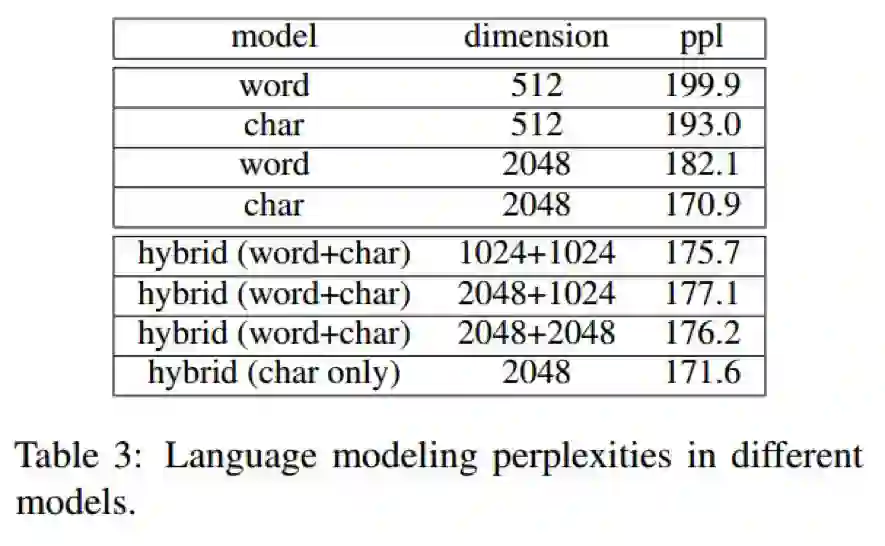
语言建模结果:字级别的模型显著优于词级别的模型
从表中可以看到,在同维度下(512d与2048d),字级别的模型显著优于词级别的模型。而且在维度为2048的时候,ppl呈现巨大差距。
此外,我们还对“字”+“词”的混合模型(hybrid)进行了实验。对于混合模型,我们不仅使用了“词”表示,还对每个词内部的“字”表示,通过CNN得到一个综合的“字”表示,然后把这两者组合起来。表中的“char only”表示我们只使用后者。
可以看到,“char only”的模型优于其他带有“词”表示的模型,而“word+char”的模型都优于单个“词”模型。
这表明了“字”级别的模型已经编码了语言建模任务所需要的语言信息,额外增加“词”表示反而会损害表现。
机器翻译(Machine Translation)
对于MT,我们使用标准的中英互译的设置。我们在LDC语料库中选取了1.25M个句子,在NIST2002上进行验证,在NIST2003/2004/2005/2006/2008上进行测评。
模型使用标准的seq2seq+attention,同时,我们也列出了Mixed RNN、Bi-Tree-LSTM和PKI模型的结果作为比较。
此外,我们还使用了(Ma et al. 2018)中的BOW方法。词和字的表示维度都设置为512。具体的参数及其他设置详见论文。
实验结果如下:
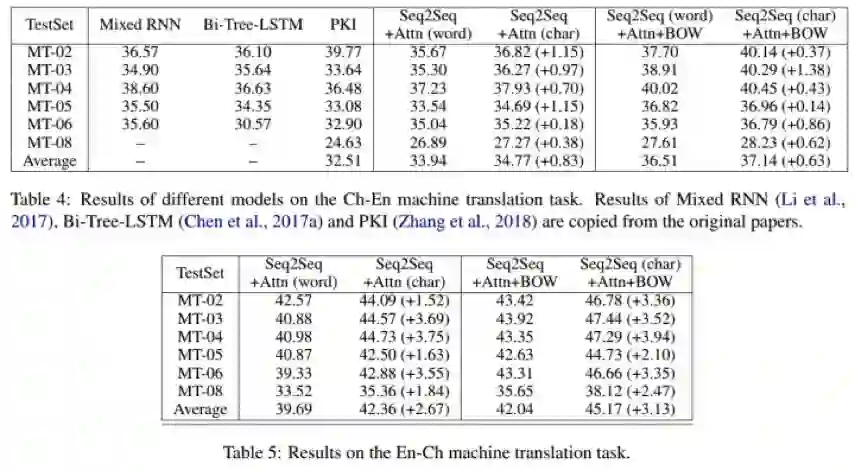
可以看到,在中->英翻译中,简单的seq2seq+attention模型,“字”级别已经显著超过“词”级别,平均有0.83的BLEU值的提升。
再加上(Ma et al. 2018)的BOW方法,“字”级别的模型也比“词”级别的模型平均高0.63,而且也是其中的最好结果。
在英->翻译中,“字”模型比“词”模型有更大的提升,平均达到3.13。我们认为这是因为:
在中->英翻译中,“字”和“词”的区别仅体现在编码端;而在英->中翻译中,在编码端和解码端都有表现。
在英->中翻译中,解码端的UNK对于词影响更大。
为此,我们在英->中翻译的解码端使用了BPE方法,在seq2seq+att中得到了41.44,在seq2seq+att+bow中得到了44.35的得分,显著超过“词”级别模型,但依旧比“字”级别模型较低。
句子匹配(Sentence Matching)
对句子匹配任务,我们使用BQ和LCQMC两个数据集。这两个数据集都是给定一对句子,需要我们去判断它们在某些方面的相似性(两分类,相同或不相同)。
BQ是需要去判断语义等价,LCQMC是需要去判断意图等价。这两个数据集都非常适合去检验模型的语义捕捉能力。
我们使用当前在这两个数据集上的SOTA模型:BiMPM,参数设置保持不变,即200维的字及词表示。
实验结果如下:

可以看到,“字”级别的模型在验证集和测试集上都显著优于“词”级别模型。这表明,“字”级别的模型更能捕捉单元之间的语义联系。
文本分类(Text Classification)
对于文本分类,我们使用下面的数据集(Zhang and LeCun 2017):
ChinaNews:中文新闻文章,七分类。
Ifeng:中文新闻文章的第一段,五分类。
JD_full:京东上的商品点评,五分类。
JD_binary:京东上的商品点评,二分类,是在JD_full中,将1星和2星归为负类,将4星和5星归为正类,忽略3星。
Dianping:大众点评的评价,五分类,作为二分类时,将1星、2星和3星归为负类,将4星和5星归为正类。
我们使用BiLSTM模型,结果如下:
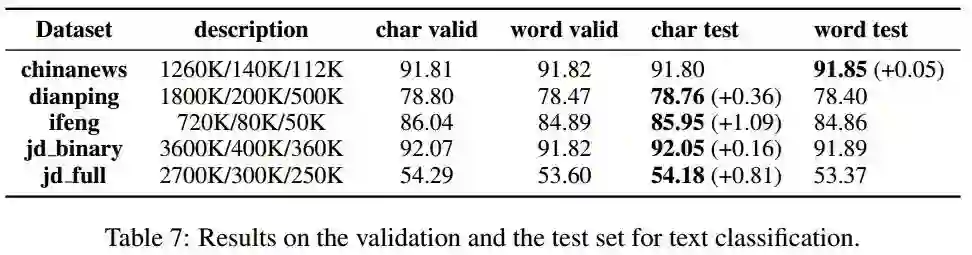
可以看到,只有在Chinanews数据集上,“词”级别模型才略高于“字”级别模型,在其他数据集上都是“字”优于“词”。
额外地,我们还在Dianping和JD两个数据集上进行了数据集迁移(Domain Adaptation)实验。
我们首先在Dianping上训练,然后在JD_binary上测试;然后反过来检验。结果如下:
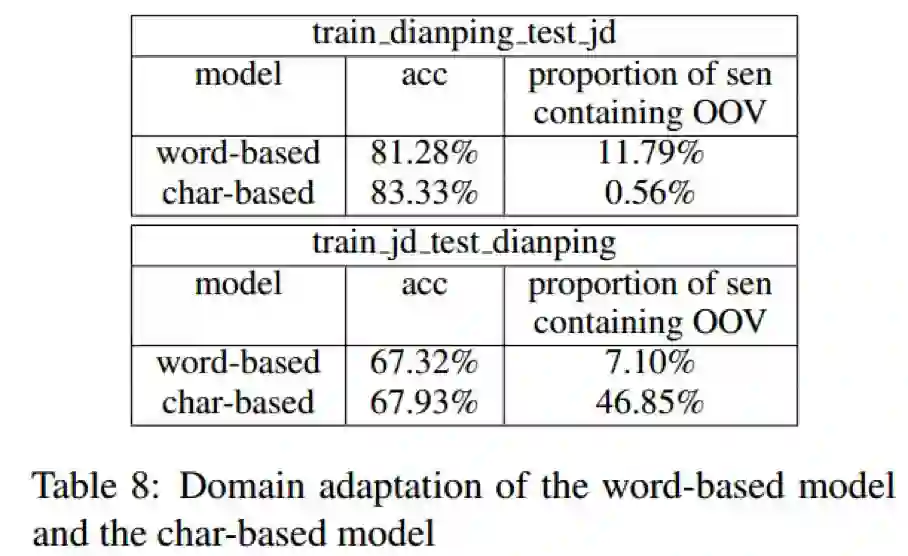
可以看到,在两个方向上都是“字”优于“词”,而且OOV也有显著优势。
分析
在本节中,我们将从数据稀疏、OOV和过拟合三个方面去分析“字”优于“词”的原因。
数据稀疏
由于空间限制,我们不可能把所有出现的字/词都纳入词典,常见的方法是设置一个“频率界限”,低于这个界限的都设置为一个特殊的UNK标记。
下图是不同的频率界限和词典大小、模型表现在“字”级别和“词”级别上的曲线图:
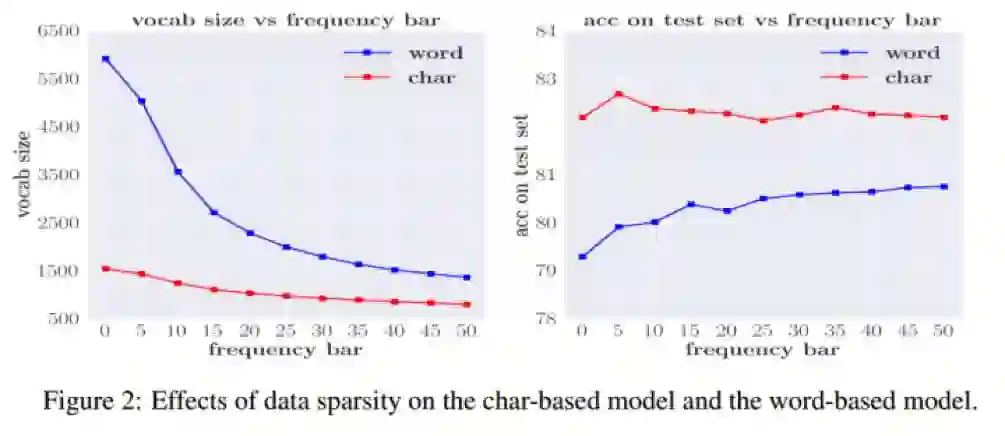
可以看到,当bar=0的时候,两种模型都表现得很差。而对于“字”级别模型,提高bar对表现影响不大,当bar=5时表现最佳;对于“词”级别模型,提高bar可以显著提升表现。
这说明,为了充分学习语言信息,模型必须对词典中的单元有充分的“接触”(或者说足够多的数据量),而对于“词”级别模型而言,这点更加难以满足。
OOV问题
另一方面,“词”模型也有更多的OOV。如果是因为OOV问题导致的“词”模型效果欠佳,那么我们期望可以通过减少OOV来缩小与“字”模型的差距。
但是正如上面所讲的,减少OOV就意味着降低频率界限,这样就会加剧数据稀疏问题。因此我们使用另一种方法:对不同的词频率界限,我们在数据集(包括验证机和测试集)中除去那些包含OOV词的句子。如下图所示:
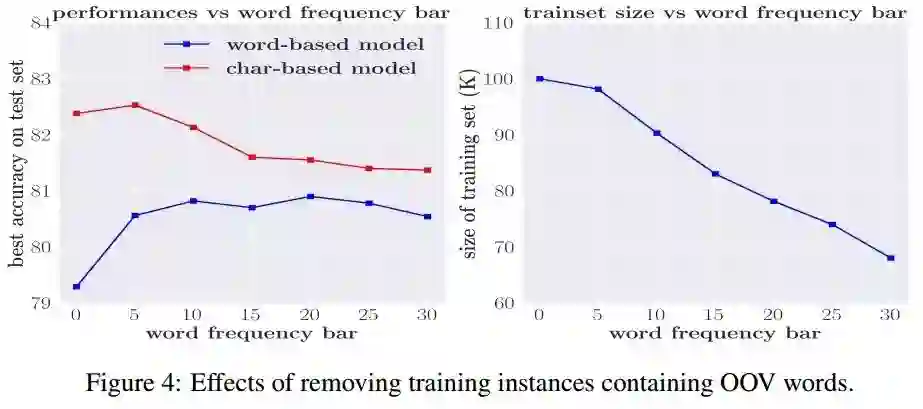
显然,“字”和“词”的差距随着bar的增加在逐渐缩小,“字”模型表现下降,而“词”模型表现上升。
这说明,对于“字”模型而言,OOV不是一个突出的问题,缩小数据集会导致效果下降;对于“词”模型,OOV的确会严重阻碍模型的表现,减少数据集中的OOV有利于效果提升。这启示我们未来的工作可以考虑如何解决OOV上。
过拟合
数据稀疏问题使得模型参数增多,从而更容易过拟合。我们在BQ上进行实验,发现对于“词”模型,dropout为0.5时效果最佳,而对“字”模型而言,dropout为0.3时效果最佳。
这说明过拟合在“词”模型上更容易发生。另一方面,尽管我们设置了更大的dropout,但“词”模型仍然不及“字”模型,这表明单纯的dropout不能解决过拟合问题。
可视化
我们在BQ数据集中选取句对“利息费用是多少”和“下一个月还款要扣多少利息”并画出其heatmap:
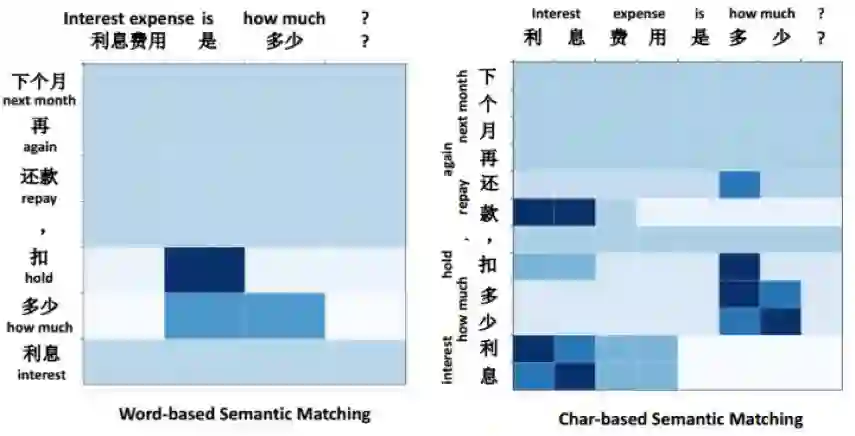
可以看到,对于“词”模型而言,“利息费用”不能和“利息”匹配,而“字”模型可以做到。
小结
在本文中,我们通过四个中文NLP任务实验,验证了在效果上“字”级别模型普遍优于“词”级别模型。通过分析,我们认为“词”级别模型的欠佳表现可以归结为数据稀疏、OOV问题、过拟合与数据集迁移能力缺乏等原因。
我们希望通过本文,可以启发未来更多更细致的关于中文分词、最佳中文表示单元的研究。
2019 全球人工智能与机器人峰会
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

点击阅读原文,加入NLP论文讨论小组吧~