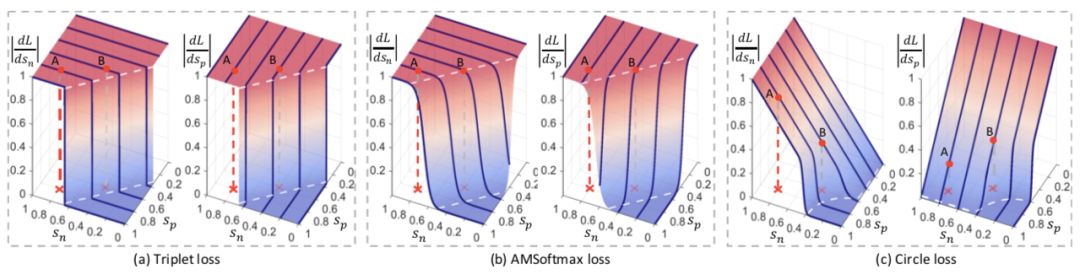
CVPR 2020 Oral | 旷视研究院提出Circle Loss,统一优化视角,革新深度特征学习范式
机器之心编辑部
计算机视觉与模式识别会议 CVPR 2020 将于 6 月 14-19 日在美国西雅图举行。近日,大会官方论文结果公布,旷视研究院 16 篇论文被收录,研究领域涵盖人脸识别、实时视频感知与推理、小样本学习、迁移学习,3D 感知、细粒度图像等众多领域。本文是其中一篇 Oral 论文的解读。

优化缺乏灵活性
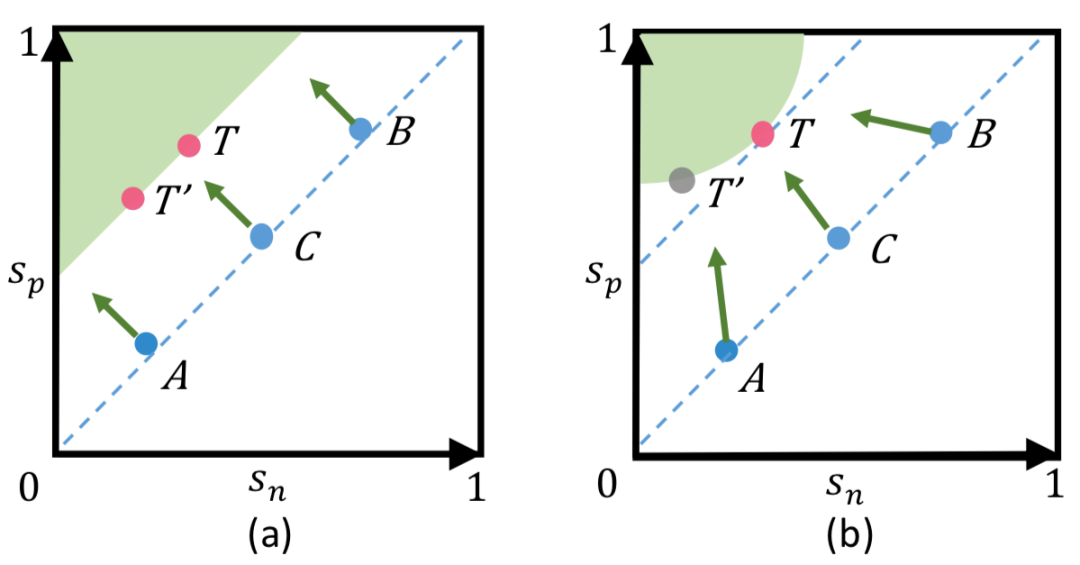
s_n 和 s_p 上的惩罚力度是严格相等的。换而言之,给定指定的损失函数,在 s_n 和 s_p 上的梯度的幅度总是一样的。例如图 1(a)中所示的 A 点,它的 s_n 已经很小了,可是,s_n 会不断受到较大梯度。这样现象低效且不合理。
收敛状态不明确
优化 (s_n - s_p) 得到的决策边界为 s_p - s_n = m(m 是余量)。这个决策边界平行于 s_n = s_p, 维持边界上任意两个点(比如 T=(0.4, 0.7) 和 T'=(0.2, 0.5))的对应难度相等,这种决策边界允许模棱两可的收敛状态。比如,T 和 T' 都满足了 s_p - s_n = 0.3 的目标,可是比较二者时,会发现二者之间的分离量只有 0.1,从而降低了特征空间的可分性。
统一的(广义)损失函数。从统一的相似度配对优化角度出发,它为两种基本学习范式(即使用类别标签和使用样本对标签的学习)提出了一种统一的损失函数;
灵活的优化方式。在训练期间,向 s_n 或 s_p 的梯度反向传播会根据权重 α_n 或 α_p 来调整幅度大小。那些优化状态不佳的相似度分数,会被分配更大的权重因子,并因此获得更大的更新梯度。如图 1(b) 所示,在 Circle Loss 中,A、B、C 三个状态对应的优化各有不同。
明确的收敛状态。在这个圆形的决策边界上,Circle Loss 更偏爱特定的收敛状态(图 1 (b) 中的 T)。这种明确的优化目标有利于提高特征鉴别力。
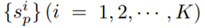 和
和
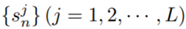 。
。
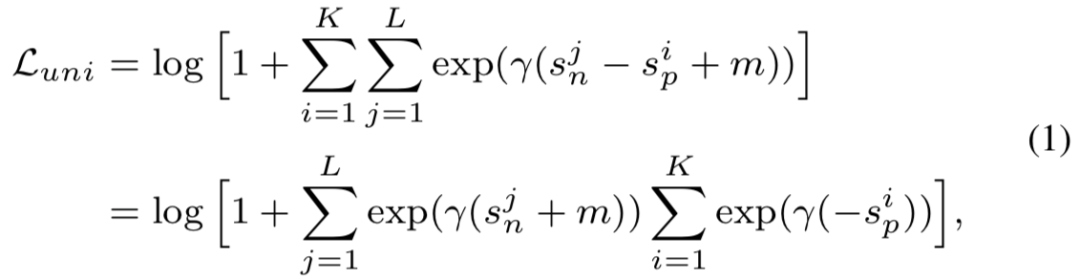
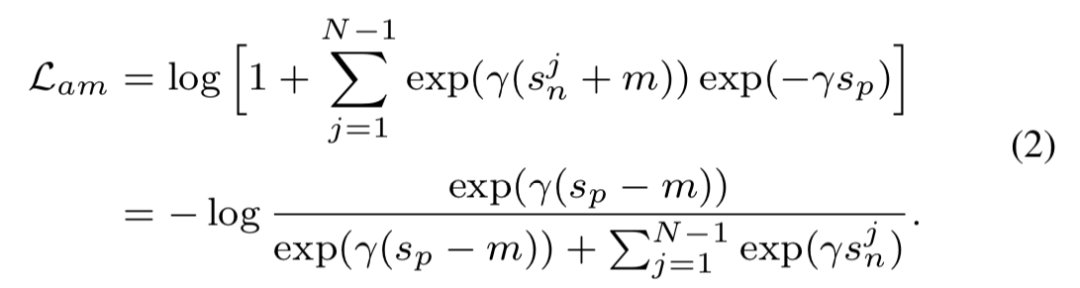
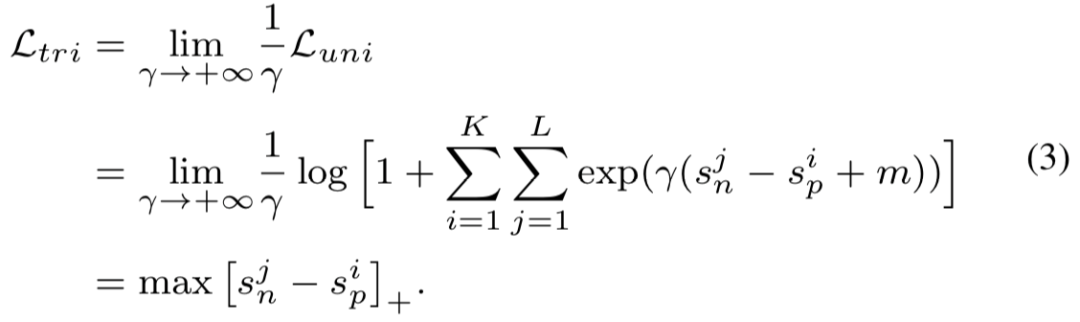
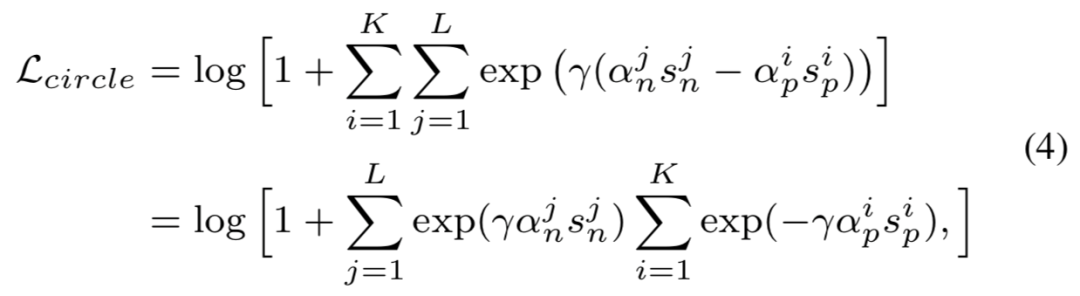
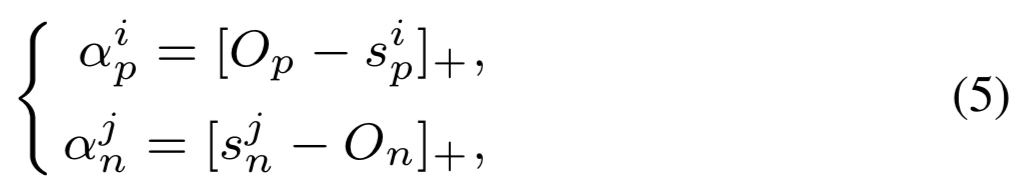
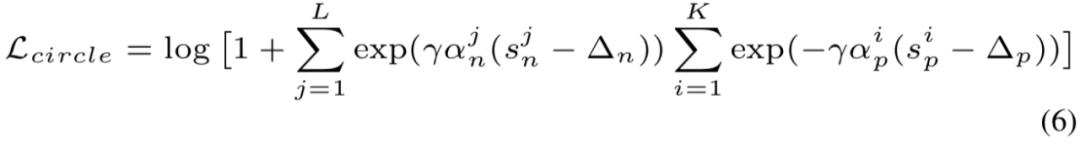
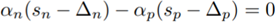 处得到。
根据等式 (5) 和 (6),可得到决策边界:
处得到。
根据等式 (5) 和 (6),可得到决策边界:
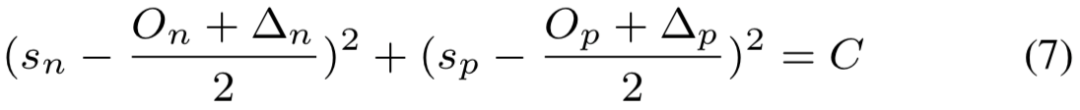
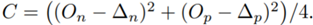
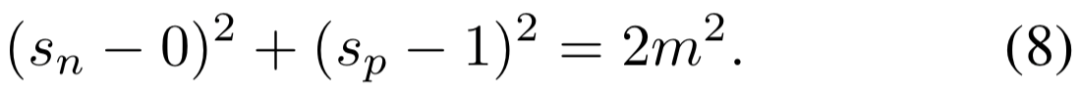
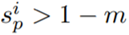 且
且
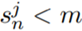 。因此,超参数仅有 2 个,即扩展因子 γ 和松弛因子 m。
。因此,超参数仅有 2 个,即扩展因子 γ 和松弛因子 m。
 和
和
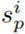 上的梯度分别为:
上的梯度分别为:
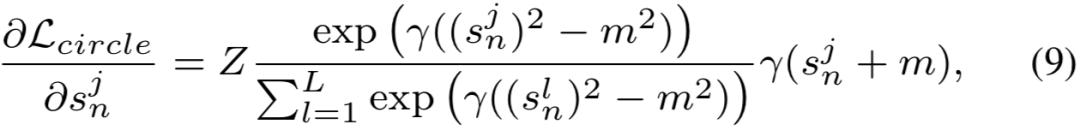
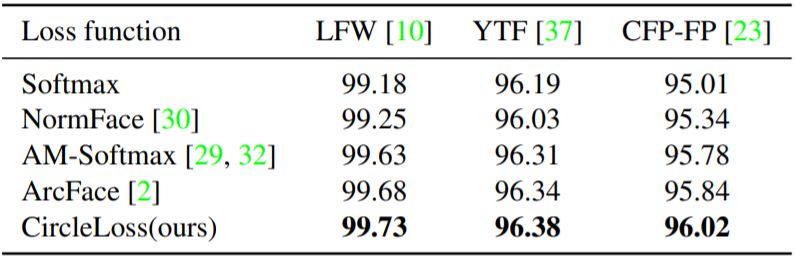
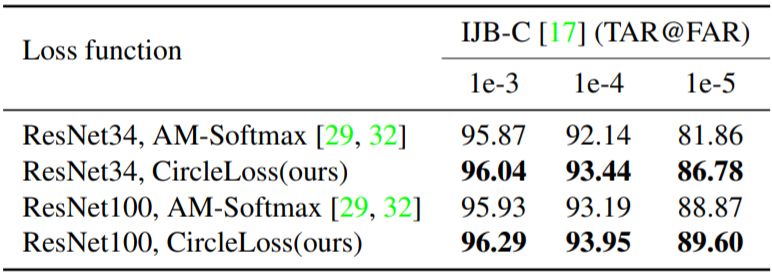
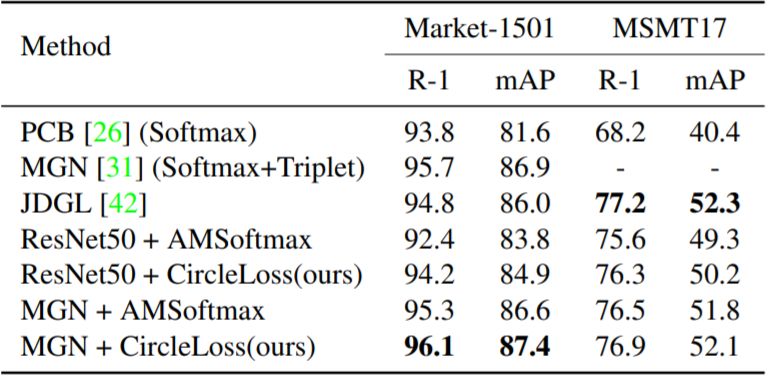
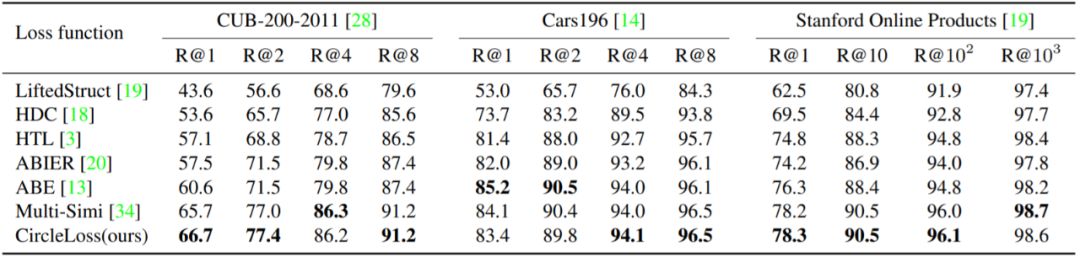
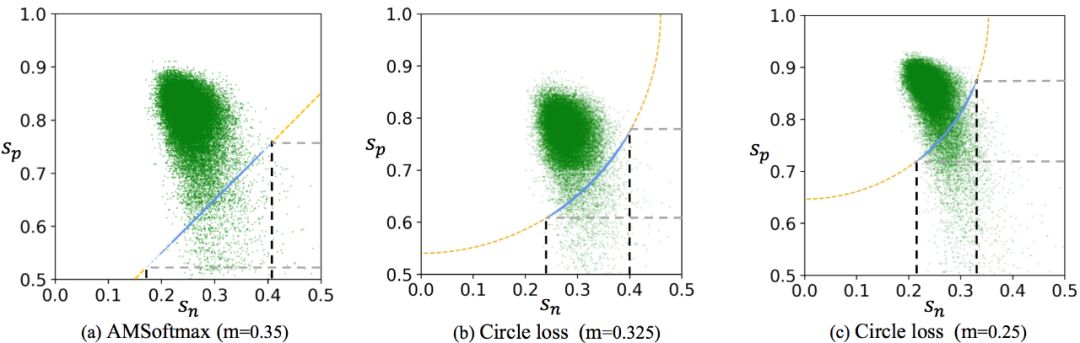
首先,是绿色散布点代表的收敛后状态;
其次,是蓝色累积点反映的通过决策面时瞬间的分布密度。
E. Hoffer and N. Ailon. Deep metric learning using triplet network. In International Workshop on Similarity-Based Pattern Recognition, pages 84–92. Springer, 2015.
W. Liu, Y. Wen, Z. Yu, and M. Yang. Large-margin softmax loss for convolutional neural networks. In ICML, 2016.
F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 815–823, 2015.
Y. Sun, X. Wang, and X. Tang. Deep learning face repre- sentation from predicting 10,000 classes. In Proceedings of the IEEE conference on computer vision and pattern recog- nition, pages 1891–1898, 2014.
F. Wang, J. Cheng, W. Liu, and H. Liu. Additive margin softmax for face verification. IEEE Signal Processing Let- ters, 25(7):926–930, 2018.
H. Wang, Y. Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu. Cosface: Large margin cosine loss for deep face recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
Y. Wen, K. Zhang, Z. Li, and Y. Qiao. A discrimina- tive feature learning approach for deep face recognition. InEuropean conference on computer vision, pages 499–515. Springer, 2016.

