资源 | Facebook开源首个适应大规模产品的强化学习平台Horizon,基于PyTorch 1.0
选自code.fb
作者:JASON GAUCI、EDOARDO CONTI、KITTIPAT VIROCHSIRI
机器之心编译
参与:路、王淑婷
今日,Facebook 开源了适合大规模产品和服务的强化学习平台 Horizon,这是第一个使用强化学习在大规模生产环境中优化系统的开源端到端平台。Horizon 包含的工作流程和算法建立在开放的框架上(PyTorch 1.0、Caffe2、Spark),任何使用 RL 的人都可以访问 Horizon。去年,Facebook 内部已经广泛应用 Horizon,包括帮助个性化 M suggestions、提供更有意义的通知、优化流视频质量。
Horizon GitHub 地址:https://github.com/facebookresearch/Horizon
今天,Facebook 开源了一个强化学习端到端平台 Horizon,该平台利用强化学习(RL)来优化数十亿用户规模的产品及服务。Facebook 开发此平台的目的是弥补 RL 在研究领域日益增强的影响力与其在生产领域的狭窄应用之间的落差。过去一年,Facebook 已在内部广泛部署了 Horizon,提高了该平台将 RL 基于决策的方法应用于大规模应用的能力。尽管其他人也在做 RL 应用方面的研究,但 Horizon 是第一个用于生产的开源 RL 平台。
Horizon 专注于将 RL 应用于大型系统。本次开源包含用于模拟环境的工作流程及用于生产预处理、训练及模型导出的分布式平台。Horizon 平台已经提高了 Facebook 的性能,包括发送相关度更高的通知、优化流视频比特率及提升 Messenger 中 M suggestions 的效果。但 Horizon 的开放性设计和工具集使得它可以惠及该领域其他研究人员,尤其是对利用 RL 从大量信息中学习策略的公司和研究团队而言。Horizon 不仅是 Facebook 继续投资 RL 的证明,也表明这个充满希望的人工智能研究领域现在可以用于实际应用。
大规模决策:Horizon 如何利用 RL 进行生产
机器学习(ML)系统通常产生预测,但之后就需要工程师将这些预测转化为策略(即采取行动的策略)。另一方面,RL 创建的系统能够决策、采取行动,并基于收到的反馈进行改进。这种方法无需手动制造的策略就可以优化一系列决策。例如,RL 系统可以在视频播放时,基于来自其他 ML 系统的评估和视频缓冲器的状态直接选择高/低比特率。
尽管 RL 的策略优化能力在研究中已经展示出不错结果,但人工智能社区很难调整这些模型来处理截然不同的现实生产环境需求。Horizon 专注于缩小两种不同应用类型之间的差距:研究相关模拟器的复杂但有限的环境;基于 ML 的策略优化系统,该系统依赖本质上带噪声、稀疏和任意分布的数据。虽然在一些游戏中,RL 驱动的机器人可以对有限的一组预测和重复性规则作出反应,但在现实世界中不可能实现完美模拟,且反馈也更难融入到部署代码中去,因为与受控的实验环境相比,这种环境中的任何改动都必须更加小心。
与深度学习对神经网络应用的改变类似,Horizon 等项目有望通过使用策略优化产生影响,定义科学家和工程师把 RL 应用于生产环境的方式。具体来说,Horizon 考虑了具体的生产环境问题,包括特征归一化、分布式训练、大规模部署和服务,以及具有数千种不同特征类型和分布与高维离散和连续动作空间的数据集。
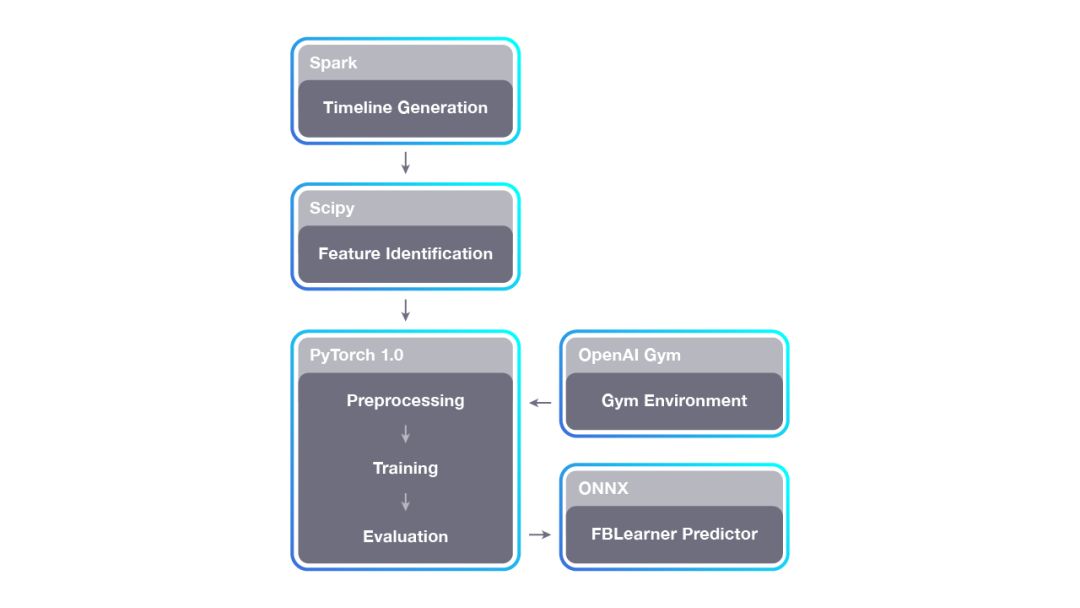
Horizon 的工作流程分为三部分:1)时间线生成,在数千个 CPU 上运行;2)训练,在多个 GPU 上运行;3)服务,也跨越数千台机器。该工作流程允许 Horizon 扩展到 Facebook 数据集。对于在策略学习(如使用 OpenAI Gym),Horizon 可以选择将数据直接传输给闭环训练。
Horizon 还解决了大规模构建和部署 RL 系统带来的独特挑战。RL 通常以在线方式训练,系统首选随机选择动作,然后实时更新。考虑到 Facebook 上系统的规模和影响,这种随机性和实时更新目前尚无法选择。Facebook 的模型首先基于产品工程师设计的策略开始训练。该模型必须离线训练,使用离策略方法和反事实策略评估(counterfactual policy evaluation,CPE)来估计如果 RL 模型做了之前的决策,它会做什么。一旦 CPE 结果被接受,研究人员就在一个小实验中部署 RL 模型,并收集结果。有趣的是,结果显示与保持相对恒定的已有系统不同,RL 系统会随着时间的推移继续学习和改进。
行业数据集通常包含数十亿条记录和数千个具有任意分布和高维离散与连续动作空间的状态特征。根据研究和观察,研究人员发现,与传统的深度网络相比,应用 RL 模型对带噪声和非标准化的数据更敏感。Horizon 利用 Apache Spark 并行预处理这些状态和动作特征(此次开源包括 Spark pipeline)。训练数据经过预处理后,研究人员使用基于 PyTorch 的算法在 GPU 上进行归一化和训练。
尽管 Horizon 可以在单个 GPU 或 CPU 上运行,但该平台使用大型集群。在多个 GPU 上进行分布式训练可使工程师解决涉及数百万示例的问题,且更快迭代模型。Facebook 研究人员在 PyTorch 中使用数据并行和分布式数据并行功能进行分布式训练。此次发布包括深度 Q 网络(DQN)、parametric DQN 和深度确定策略梯度(deep deterministic policy gradient,DDPG)模型。训练过程中,研究人员还运行 CPE,将评估结果记录到 TensorBoard 上。训练完成后,Horizon 将使用 ONNX 导出模型,以便模型实现大规模高效服务。
在很多强化学习领域中,你可以通过尝试衡量模型的性能。Facebook 想在大规模部署模型之前进行全面的模型测试。由于 Horizon 解决了策略优化任务,因此训练工作流可以自动化运行多个当前最优策略评估技术,包括 sequential doubly robust 策略评估和 MAGIC。最终的策略评估报告在工作流中导出,可在 TensorBoard 中观察报告。策略评估可与异常检测结合起来,在大规模部署该策略之前,自动提醒工程师模型的新迭代是否与之前的模型性能迥异。
在工作中学习:Horizon 对 Messenger、360 video 等的影响
过去一年 Facebook 在内部广泛使用 Horizon,期间该平台展示了 RL 通过即时反馈做出提升性能的决策,从而对生产应用产生影响。
例如,Horizon 允许通过实时优化比特率参数来改善 Facebook 360 video 的图像质量。Horizon 使用可用带宽和已缓冲视频量决定是否转化为更高画质的视频。这个过程利用了 RL 使用新的无监督数据瞬间创造刺激(incentive)的能力,这种方法在播放给定视频时即可奏效,而不是事后分析性能和仔细标注的数据。
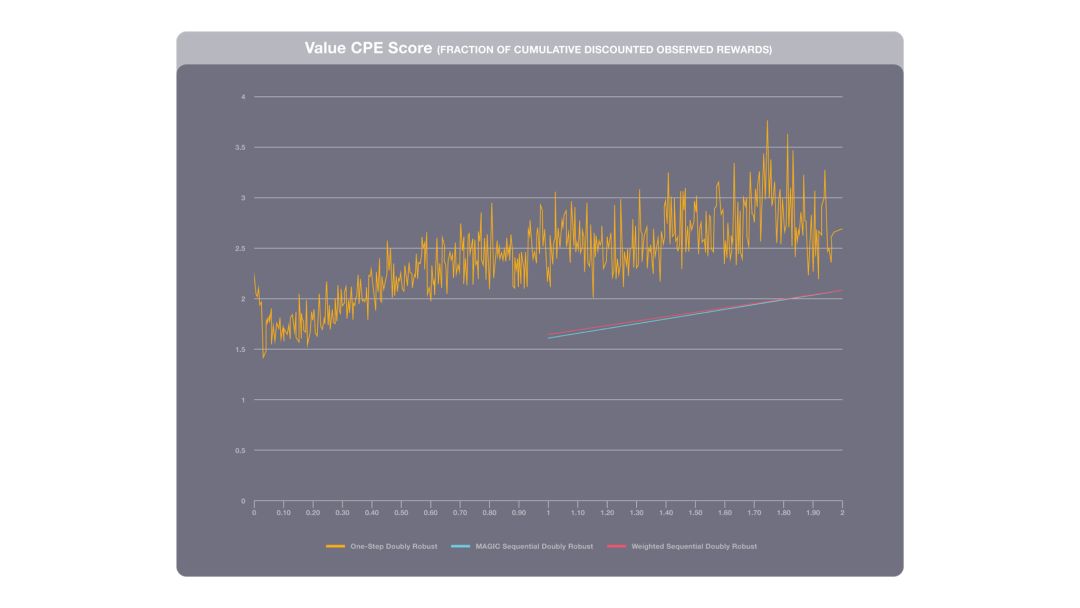
反事实策略评估为工程师在离线环境中部署 RL 模型提供了见解。上图将几种 CPE 方法和记录的策略(最初生成训练数据的系统)进行了比较。1.0 分表示 RL 和记录策略性能相当。这些结果表明 RL 模型的累积奖励大约是记录系统的两倍。

Horizon 还为 Messenger 中的智能助手 M 过滤建议。M 为人们的开放对话提供相关内容的建议或者丰富人们的沟通。Horizon 使用强化学习帮助 M 学习,在学习对话策略方面,强化学习比基于规则的方法更具扩展性、前瞻性,对用户反馈也更具响应性。例如,如果人们更常使用某个建议,M 可能会更多地展示该建议。有了 Horizon,M 变得更加智能、更加个人化,因为它每天要帮助数百万人进行沟通。
Horizon 平台还改进了 Facebook 利用 AI 确定要发送给用户哪些 Facebook 通知及发送频率的方式。过去,Facebook 不会发送每一个可能的通知(包括新 post、评论等),而是利用机器学习模型帮助预测哪个通知最有意义、最相关,过滤掉其它的通知。但是这些模型依赖于监督学习,无法解释发送通知的长期价值。例如,每天访问 Facebook 多次的人可能不需要关于新 post 的通知,因为他们总能看到,而不那么活跃的用户会从 post 通知中受益,确保不漏掉家人朋友有意思的 post。
为了更好地解决这些长期信号,同时确保通知的效果达到预期,Facebook 向整个平台的所有用户提供价值,他们利用 Horizon 训练一个离散动作 DQN 模型用于发送 push 通知。用户通过通知看到了可能漏掉的内容时该模型获得奖励,反之,如果用户本就能看到新内容,而 Facebook 发送了 post 通知,则模型会被惩罚。只有通知对用户的价值比惩罚高时,强化学习模型才会发送通知。该模型还会使用大批量状态转换进行定期更新,实现增量改进,并最终调整通知的数量。由于 Facebook 用 Horizon 强化学习模型取代了之前基于监督学习的系统,目前通知相关度方面已经有了改进,同时通知的总数并未增加。Facebook 不是通过点击通知来判断相关度,而是看得更宽更深,确保通知为用户提供真正的帮助。
允许在生产环境中部署强化学习
这些优势强调了强化学习对工业界的作用,即基于前一个次优策略收集的样本直接学习最优策略的能力。Facebook 已经确定了一些适合强化学习的特定用例和应用,但这仅是一个开始。Facebook 期待人工智能社区能够基于 Horizon 平台产生更多想法、功能和产品。
任何使用机器学习进行决策的人都可以尝试 Horizon。第一步是记录 propensity(执行某个动作的概率)和替代方案(可能的其它动作)。Horizon 利用二者学习何时可获取更好的动作。第二步是定义和记录奖励(执行动作带来的价值)。收集数据后,可以运行 Horizon 的训练循环,并导出可制定新决策并最大化整体奖励的模型。

原文链接:https://code.fb.com/ml-applications/horizon/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




