腾讯:首个在一场完整星际Ⅱ比赛中击败作弊级Bot的AI
编者按:19日,来自腾讯AI Lab、罗切斯特大学和西北大学的研究人员发表了一个预印本《TStarBots: Defeating the Cheating Level Builtin AI in StarCraft II in the Full Game》,文章介绍了两个AI:TStarBots1和TStarBots2,它们首次在完整的虫族VS虫族比赛中击败了星际争霸Ⅱ的内置AI Bot,是研究史上的又一大壮举。虽然不是严格意义上的“自学”,AI还高度依赖人为归纳的信息,但迄今为止,这是我们在星际Ⅱ项目上见到的最有建树的成果,值得期待。
译者注:星际2的内置AI难度分为“新手”“简单”“普通”“困难”“艰难”“极难”“专家”“作弊一(拥有全视野)”“作弊二(后期全视野+额外资源)”“作弊三(全视野+额外资源)”十个等级,越高越难。论文中会出现等级1~10的AI,请对照分辨。此外,下文涉及的人口单位称呼以玩家习惯为准。
简介
近年来,深度学习和强化学习的结合为学界带来了诸多进展。从头训练、只提供游戏原始特征,这些尝试为我们带来了无数令人称奇的“自学”AI,比如围棋、各种雅达利游戏、Dota2等等。但是,作为RTS游戏难度标杆的星际2还未被AI攻陷。
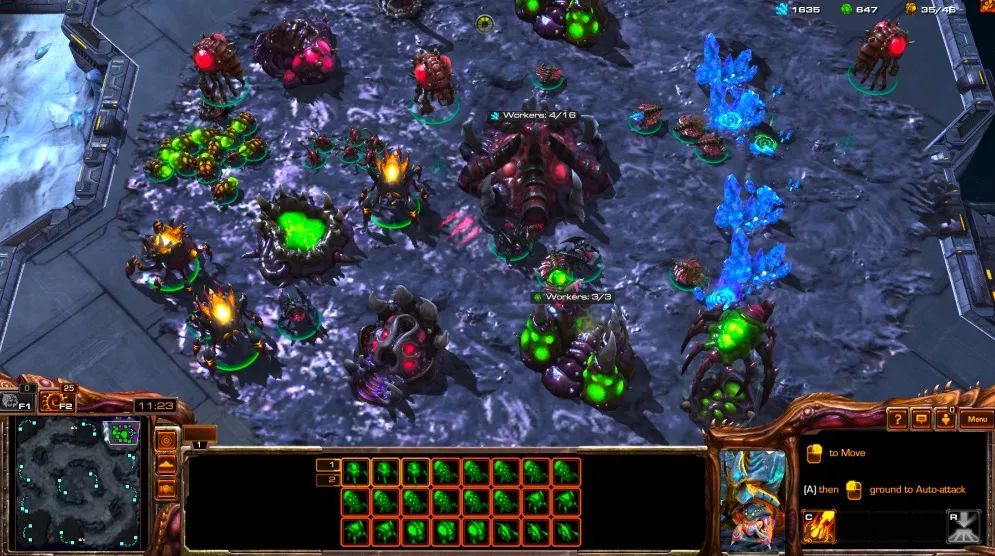
星际2截图
上图是星际2游戏内的截图。就资源来看,星际2有晶体矿(蓝色晶柱)和气矿(晶柱两侧绿色建筑)两种,不同建筑需要的资源数不同;从人口单位上看,图中有工蜂(农民)、王虫(房子)、跳虫(小狗)、毒爆虫、蟑螂、火蟑螂。
这还只是刚开局的情形,比起控制5个英雄的OpenAI Five,这个时间点星际2 AI需要控制的单位已经高达35个,随着局势逐渐展开,它还要开矿、攀科技树、建造更多建筑、孵化更高级的虫子,最终操作上百人口拉扯阵型、和敌方交换战损并最终依靠混合策略获得胜利。
图片左下角是玩家拥有的视野,这时除了基地,地图其他区域都是黑的,这意味着如果想要“刺探敌情”,AI就得派遣农民/房子/狗等单位进行战略性侦查,面对未知环境中的各种可能性,所有决定都必须是实时做出的。
巨大的观察空间、庞大(连续的、无穷的)的动作空间、受限的观察视野、多人同步游戏模型、长期决策……这些因素使星际2成为现在最具挑战性的AI游戏目标,没有之一。
去年,为了推动AI研究迈向新的前沿,DeepMind联合暴雪发布了星际2 AI学习环境SC2LE——一个用于设计复杂决策系统的测试平台。虽然它提供了不少迷你游戏,比如MoveToBeacon、CollectMineralShards和DefeatRoaches(对应“放置信标”“拾取晶体矿”和“消灭蟑螂”等基础游戏操作),部分AI也在游戏中达到了职业级玩家水平,但它们都没法真正打赢一局完整游戏。
为了对完整游戏做一些初步研究和探索,腾讯携美国两所大学的研究人员开发了两个AI:基于扁平化动作结构的深度强化学习智能体TStarBots1和基于分层动作结构规则控制器的智能体TStarBots2。经过多次实验,现在,这两个AI都能在完整对战中击败等级1~10的游戏内置机器人(1v1虫族对抗,地图:深海暗礁🔱),其中等级8、等级9和等级10的机器人都是作弊级AI,它们享有额外的视野和晶体矿、气矿资源。
这是首个能在正式比赛中击败内置机器人的AI系统,堪称研究道路上的一大突破。
具体来说,TStarBots1拥有一系列扁平化的大型操作,在这个基础上,它用强化学习训练智能体采取策略;而TStarBots1的策略控制器是人为编码的,但它有可以自行组合的大型、小型混合层次化操作集。
研究人员希望这个框架能从以下几方面对未来的研究做出贡献:
成为混合系统的基准:越来越多的学习模块,和用规则来表达难以学习的逻辑
为模仿学习提供轨迹
成为“自学”AI的对手
让AI学会“操作”的取巧做法
之前我们提到了,星际2之所以那么难以学习,是因为它存在巨大的观察空间、庞大(连续的、无穷的)的动作空间、受限的观察视野等暂时无法解决的问题。腾讯的这项研究主要针对动作空间过大,他们认为动作空间内部存在复杂结构,而这主要体现在以下几方面:
层次结构的本质
复杂的层次结构似乎总是伴随着RTS游戏中的长期决策问题,当人类玩家玩星际2时,他们进行判断主要依赖以下三个思维层次:宏观战略、局部策略和单位微操。如果AI无法理解这三个层次(也是操作层次),它就不可避免地会在强化学习期间陷入无尽训练和探索。
例如,在SC2LE的迷你游戏中,有一个名为PySC2的AI表现出色。它依靠在界面上建立低级动作空间,坐标涉及上百个热键和上千次鼠标点击。迷你游戏只是最基础的操作,它的动作空间完全没法和完整对战相比,因此这种做法是行不通的。用层次结构缩小动作空间,减小探索范围,这是一种比较可行的方法。
星际2里的硬性规则很难学习
设计基于学习的智能体的另一个挑战是星际2里存在大量硬性规则,它们就像自然界的物理法则,绝对不能违反。如果要爆蟑螂(虫族兵种👯),玩家首先得用工蜂拍下蟑螂温室,然后把虫卵孵化成蟑螂。人类玩家在接触游戏之初就从文字资料里学到了这些内容,但这对AI来说并不容易。
硬性规则出现在星际2里的方方面面,爆兵、拍建筑,而其中最重要、也最困难的是攀科技树,这不仅是个多项选择,还涉及根据局势判断优先级,需要设置额外的输赢奖励。因此,在RTS游戏中,比起寄期望于让AI自己学习,不如设法把这些复杂硬性规则编码到先验知识中。
“杀鸡得用牛刀”
值得注意的是,尽管星际2的决策空间很大,但并非所有决策都很重要。换句话说,有相当多的决定是多余的,因为它们对游戏最终结果的影响几乎可以忽略不计。还是以蟑螂为例,当人类玩家决定孵蟑螂时,他会思考这几个问题:
什么时候拍蟑螂温室?
用哪只工蜂拍温室?
拍在哪儿?
其中第一个问题最关键,它直接决定整体运营进度,这对比赛输赢至关重要;第二个问题最不重要,任何工蜂都能造建筑,选哪只根本无所谓;第三个问题有一定影响,造得近肯定比造得远好,但这涉及建筑的相对位置,也就是AI得在数千个二维坐标中进行选择,它耗费的计算资源和效果完全不成正比。
针对上述问题,研究人员最终决定还是为智能体提供手动调整的规则,对动作结构进行建模,这可以大大简化游戏的动作空间,更易于设计决策系统。
第一个AI:TStarBot1
下图是TStarBot1的工作原理示意图。它的顶部有一个单独的全局控制器,负责把强化学习算法应用于各个大型操作,训练智能体学习致胜策略。每一个大型操作都由一系列实现它的小型操作构成,如建造蟑螂温室=移动视野窗口+随机挑选工蜂+选取界面坐标位置+建造。
研究人员一共总结了165个大型操作,其中建造13个、爆兵/补农民22个、科技树27个、采矿/采气3个、对抗100个。图片底部是人为编码的游戏规则先验知识(如科技树)和如何进行操作(巢穴造哪儿),也就是说,它帮控制器省去了不少决策过程和操作细节。
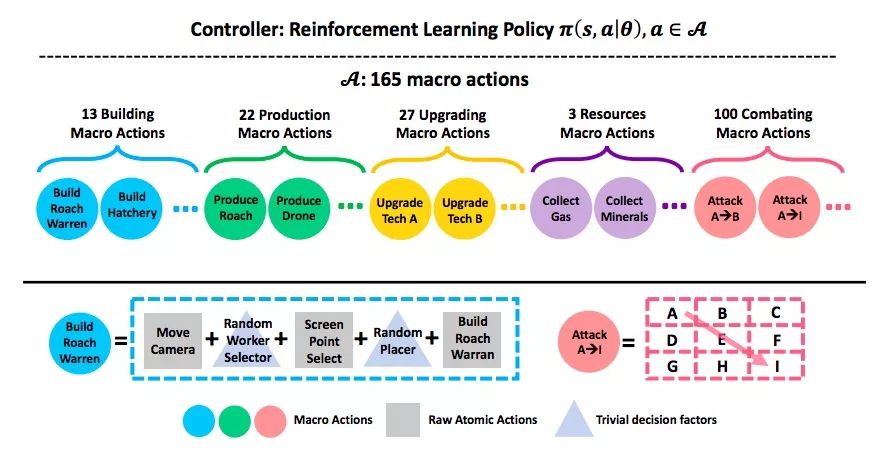
通过使用这个架构,TStarBot1在1个GPU上训练了1~2天,就击败了最高难度的游戏内置机器人。
虽然大大缩小了动作空间,但这种做法也存在不少问题。由于智能体是基于大型操作集学习的,一旦做出决策,它就要完整执行完大型操作里的所有动作,但有时其中的一些动作在每个决策步骤中是互斥的。此外,由于会不可避免地大范围引入不必要的操作,这会带来许多不必要的观察值,冗余信息会干扰模型训练。另一方面,这个AI注定无法在小操作上学到东西。
第二个AI:TStarBot2
为了解决上面的问题,研究人员又设计了第二个AI。这次,他们结合大型操作和小型操作,用双层结构组织它们。如下图所示,上层是代表高级战略/战术的大型操作,例:在主基地附近造蟑螂巢穴;让这个编队去攻击敌方基地。下层是代表每个单元低级控制的小型操作,例:在具体某位置造蟑螂巢穴;让某只虫在某个位置进行攻击。
整个动作集被分为水平子集和垂直子集。对于每个动作子集,研究人员又为其分配一个单独的控制器。它只能看到本地动作集,以及与其中的动作相关的本地观察信息。在每个时间步,同一层的控制器可以同时采取行动,而下游控制器必须以其上游控制器为条件
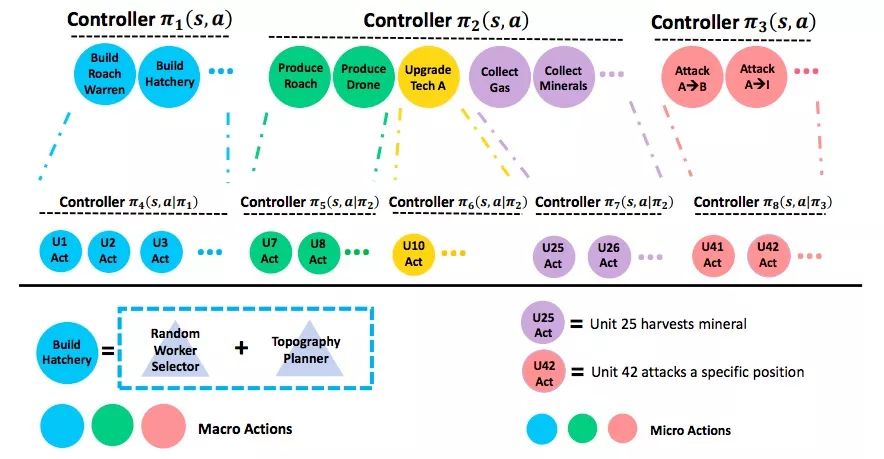
这个设计有两大优点:1.每个控制器都有自己的观察/动作空间,排除了无关信息;2. 层次结构更好地捕获动作结构,尤其是它们的组合效果。这可以被视为是原始动作空间的更精细的建模。理想情况下,两个控制器应该用强化学习算法进行联合训练,但目前研究人员还没有实现这一点。
实验:AI之争&人机大战
TStarBot VS 内置Bot

上表是TStarBot1、TStarBot1和星际2内置机器人的比赛结果统计。其中,TStarBot1和每个等级的机器人各进行了200场对战,胜率取平均值。用单个GPU和3840个CPU进行了约1~2天的训练后,面对等级1~9的机器人,AI的胜率超过90%;面对等级10的机器人,它的胜率也超过70%。
而TStarBot2的表现似乎更好,它和每个等级的机器人各进行了100场比赛,胜率取平均值(平局0.5)。数据结果显示了分层结构的有效性。
注:两个AI在训练/测试时均未作弊,即无全视野,也无额外资源。
TStarBot VS 人类玩家

在非正式内测比赛中,两个AI和天梯等级为白金/钻石的几名人类玩家进行过切磋。比赛结果如上表所示,虽然数据量有点少,但它还是透露了一个信息:AI已经有可能在比赛中击败白金甚至钻石级别的二五仔。
星际2天梯等级(从低到高):青铜<白银<黄金<白金<钻石<大师<宗师
TStarBot1 VS TStarBot2
研究人员还测试了TStarBot1和TStarBot2相互对抗,出人意料的是,获胜者始终是TStarBot1,因为它已经掌握简单、残暴、有效的虫族战术之一:Zergling Rush。即开局就爆小狗(甚至到敌方脸上拍基地),快攻推平敌方基地。TStarBot2没有学会应对方法,所以屡战屡败。
值得注意的是,虽然TStarBot1在AI内战中“百战百胜”,但它在应对人类时战术单一。一旦人类玩家发现它只会用Zergling Rush,TStarBot1就再也无法获胜了。而导致这个问题的原因可能是以下两个:1.缺乏多样性的队友——虽然游戏内置机器人已经很完善,但它们的动作空间还比不上人类。2.缺乏深度探索——更先进的战术藏于科技树中,TStarBot1这样朴素的探索行为注定没法成长。
论文地址:arxiv.org/pdf/1809.07193.pdf







