详细记录u版YOLOv5目标检测ncnn实现

极市导读
本文作者用 yolov5 作为例子,介绍了如何用 ncnn 实现出完整形态的 yolov5。完整阐述了如何用自定义层以及动态输入的注意事项,给大家作为一个参考。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
0x0 u版YOLOv5
众所周知,原版YOLO系列是 darknet 框架训练的,而广泛使用的是 YOLOv4 作者 AlexeyAB 的版本
AlexeyAB 首字母是a,于是也被叫做 a版,darknet模型可以用 ncnn 自带的 darknet2ncnn 无痛转换,步骤比较简单,因此本文不提
https://github.com/AlexeyAB/darknet
Ultralytics LLC 再次改进出更快更好的 YOLOv5,并且之前也有独立实现的 pytorch yolov3
Ultralytics 首字母是u,于是也被叫做 u版。pytorch 大法好!(曾经我以为u版的意思是能放在u盘里跑的yolo(((
https://github.com/ultralytics/yolov5
0x1 缘由
pytorch yolov5 转 ncnn 推理,搜索下 github 便能找到好几个,zhihu 也有文章
ncnn example 里没有 yolov5.cpp,本打算借鉴下社区成果,结果仔细看了代码发现这些实现都缺少了 yolov5 Focus 模块和动态尺寸输入,前者导致检测精度差一截,后者导致推理速度差一截,这样子放进官方repo当成参考代码是不行的
这里就用 yolov5 作为例子,介绍下如何用 ncnn 实现出完整形态的 yolov5
0x2 pytorch测试和导出onnx
按照 yolov5 README 指引,下载 yolov5s.pt,调用 detect.py 看看检测效果
$ python detect.py --source inference/images --weights yolov5s.pt --conf 0.25
效果没有问题,继续按照 README 指引,导出 onnx,并用 onnx-simplifer 简化模型,到此都很顺利
https://github.com/ultralytics/yolov5/issues/251github.com
$ python models/export.py --weights yolov5s.pt --img 640 --batch 1
$ python -m onnxsim yolov5s.onnx yolov5s-sim.onnx0x3 转换和实现focus模块
$ onnx2ncnn yolov5s-sim.onnx yolov5s.param yolov5s.bin转换为 ncnn 模型,会输出很多 Unsupported slice step,这是focus模块转换的报错
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !好多人遇到这种情况,便不知所措,这些警告表明focus模块这里要手工修复下
打开 yolov5/models/common.py 看看focus在做些什么
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))这其实是一次 col-major space2depth 操作,pytorch 似乎并没有对应上层api实现(反向的 depth2space 可以用 nn.PixelShuffle),yolov5 用 stride slice 再 concat 方式实现,实乃不得已而为之的骚操作
用netron工具打开param,找到对应focus的部分
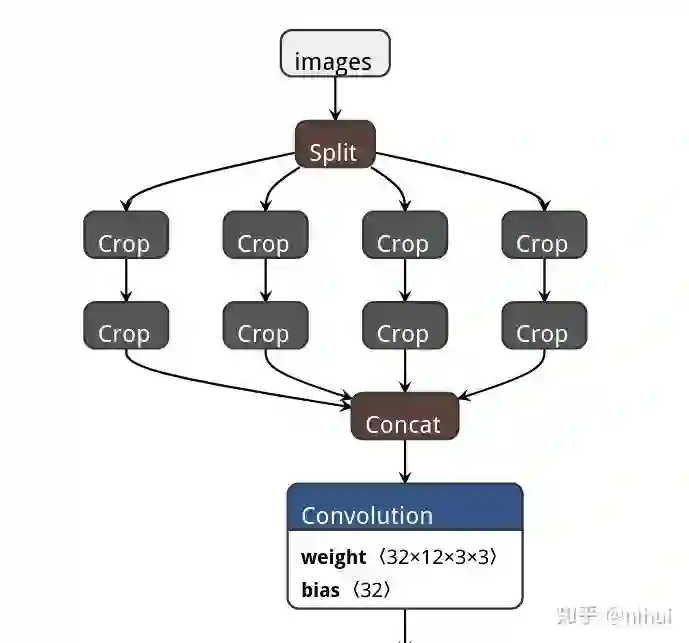
把这堆骚操作用个自定义op YoloV5Focus代替掉,修改param
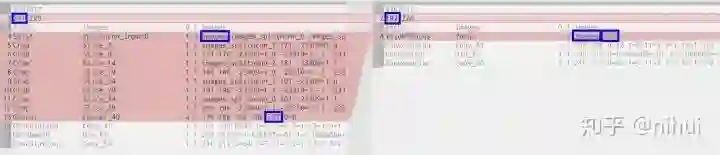
-
找准输入输出 blob 名字,用一个自定义层 YoloV5Focus 连接 -
param 开头第二行,layer_count 要对应修改,但 blob_count 只需确保大于等于实际数量即可 -
修改后使用 ncnnoptimize 工具,自动修正为实际 blob_count
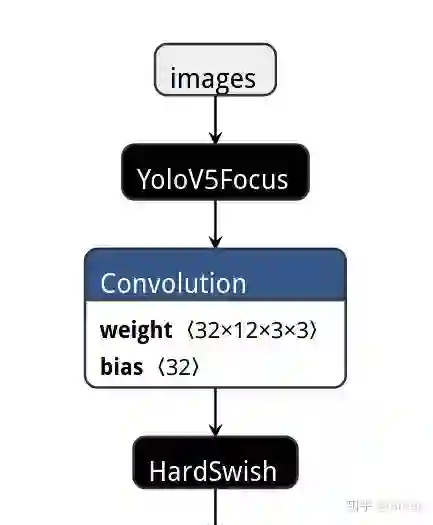
替换后用 ncnnoptimize 过一遍模型,顺便转为 fp16 存储减小模型体积
$ ncnnoptimize yolov5s.param yolov5s.bin yolov5s-opt.param yolov5s-opt.bin 65536接下来要实现这个自定义op YoloV5Focus,wiki上的步骤比较繁多
https://github.com/Tencent/ncnn/wiki/how-to-implement-custom-layer-step-by-stepgithub.com
针对 focus 这样,没有权重,也无所谓参数加载的 op,继承 ncnn::Layer 实现 forward 就可以用,注意要用 DEFINE_LAYER_CREATOR 宏定义 YoloV5Focus_layer_creator
#include "layer.h"
class YoloV5Focus : public ncnn::Layer
{
public:
YoloV5Focus()
{
one_blob_only = true;
}
virtual int forward(const ncnn::Mat& bottom_blob, ncnn::Mat& top_blob, const ncnn::Option& opt) const
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int channels = bottom_blob.c;
int outw = w / 2;
int outh = h / 2;
int outc = channels * 4;
top_blob.create(outw, outh, outc, 4u, 1, opt.blob_allocator);
if (top_blob.empty())
return -100;
#pragma omp parallel for num_threads(opt.num_threads)
for (int p = 0; p < outc; p++)
{
const float* ptr = bottom_blob.channel(p % channels).row((p / channels) % 2) + ((p / channels) / 2);
float* outptr = top_blob.channel(p);
for (int i = 0; i < outh; i++)
{
for (int j = 0; j < outw; j++)
{
*outptr = *ptr;
outptr += 1;
ptr += 2;
}
ptr += w;
}
}
return 0;
}
};
DEFINE_LAYER_CREATOR(YoloV5Focus)加载模型前先注册 YoloV5Focus,否则会报错找不到 YoloV5Focus
ncnn::Net yolov5;
yolov5.opt.use_vulkan_compute = true;
// yolov5.opt.use_bf16_storage = true;
yolov5.register_custom_layer("YoloV5Focus", YoloV5Focus_layer_creator);
yolov5.load_param("yolov5s-opt.param");
yolov5.load_model("yolov5s-opt.bin");0x4 u版YOLOv5后处理
其实工程量最大的倒是后处理的实现,u版的后处理和a版本是不一样的,ncnn内置的YoloV3DetectionOuptut是对着a版实现的,不能直接拿来接住,需要自己实现
anchor信息是在 yolov5/models/yolov5s.yaml
pytorch的后处理在 yolov5/models/yolo.py Detect类 forward函数,对着改写成 cpp
netron里找到模型的3个输出blob,分别对应于 stride 8/16/32 的输出
输出shape可知
-
w=85,对应于bbox的dx,dy,dw,dh,bbox置信度,80种分类的置信度 -
h=6400,对应于整个图片里全部anchor的xy,这个1600是stride=8的情况,输入640的图片,宽高划分为640/8=80块,80x80即6400 -
c=3,对应于三种anchor
sort nms 可以借鉴 YoloV3DetectionOuptut
0x5 动态尺寸推理
u版yolov5 是支持动态尺寸推理的
-
静态尺寸:按长边缩放到 640xH 或 Wx640,padding 到 640x640 再检测,如果 H/W 比较小,会在 padding 上浪费大量运算 -
动态尺寸:按长边缩放到 640xH 或 Wx640,padding 到 640xH2 或 W2x640 再检测,其中 H2/W2 是 H/W 向上取32倍数,计算量少,速度更快
ncnn天然支持动态尺寸输入,无需reshape或重新初始化,给多少就算多少
如果直接跑小图,会发现检测框密密麻麻布满整个画面,或者根本检测不到东西,就像这样

问题出在最后 Reshape 层把输出grid数写死了,根据 ncnn Reshape 参数含义,把写死的数量改为 -1 便可以自适应

后处理部分也不可写死 sqrt(num_grid),要根据图片宽高和 stride 自适应
const int num_grid = feat_blob.h;
int num_grid_x;
int num_grid_y;
if (in_pad.w > in_pad.h)
{
num_grid_x = in_pad.w / stride;
num_grid_y = num_grid / num_grid_x;
}
else
{
num_grid_y = in_pad.h / stride;
num_grid_x = num_grid / num_grid_y;
}ncnn实现代码和转好的模型已上传到github
0x6 android例子
https://github.com/nihui/ncnn-android-yolov5github.com

根据 README 步骤就能编译,yolov5 小目标检测挺厉害的
0x7 总结
没啥好总结的,写个文章,实践下如何用自定义层,讲讲动态输入的注意事项,将来有需要可以参考着来
虽然没有这教程,也能把 example 的 yolov5 跑起来,但里头的过程和细节就看不到了,授人鱼不如授人渔
ncnn就要1w star啦(小声
https://github.com/Tencent/ncnngithub.com
推荐阅读








