SIGGRAPH 2020 | 基于样例的虚拟摄影和相机控制


关键词:摄影相机 电影学


生命在于运“动”,场景在于“动”态,摄影在于相机移“动”。“动”是常态,也是图形生成、理解与呈现的核心研究对象。
人体动作是否有最精简的表达?不同动作风格是否能够独立于动作的内容而描述,由此同一个动作能够被赋予不同的风格?磁流体的千姿百态能否通过物理建模来模拟呈现?移动相机的轨迹规划是一个专业性很强的操作,这一经验能否从已有专业视频中学习得到?李沛卓(图灵班17级)、翁伊嘉(图灵班17级)、倪星宇(图灵班16级)、蒋鸿达(博士19级)四位同学与国内外学者合作,分别针对这些问题进行研究,相关成果将发表在7月份的 SIGGRAPH 会议。
因为疫情,今年的 SIGGRAPH 会议改为在线,第一次“出道”的四位同学遗憾不能现场享受传统的视觉盛宴。基于 SIGGRAPH 的创意基因,这次虚拟会议更值得期待。
——陈宝权
于静园
声明:本文首发于知乎,经作者授权标注“原创”发表于此。转载需标注首发出处。
知乎原文:https://zhuanlan.zhihu.com/p/141861866
项目主页:https://jianghd1996.github.io/publication/sig_2020/
(点击“阅读原文”跳转)

01
背景介绍
真实电影的拍摄往往依赖于导演和摄影师的丰富经验,好的镜头能更好地表达电影的内容和情感。在虚拟摄影中,相机不再受场景的限制,可以自由地进行控制,这赋予了虚拟相机更加丰富的表达能力。但从观众的角度来说,对于虚拟影视作品和真实电影作品的要求是一样的,即相机的运动需要遵循一定的规律性,并符合电影拍摄审美的固定要求。
在著名导演、电影剪辑师 Daniel Arijon 的著作[1]中,他对电影摄影在各种场景下的放置、运动进行了归纳总结。然而,要将这些规则全部转换为可真正运行的虚拟相机控制器,并不是一件容易的事情。一方面,需要对场景进行理解,对被拍摄人物的相对位置、朝向进行分析,然后找到对应需要运用的规则;另一方面,当场景中的人物发生变换、运用的规则发生改变时,需要控制相机进行平滑的切换。此外,对于同一场景,基于不同的剧情,相机可能有多种不同的拍摄方案,导演在拍摄时更多地是通过临场发挥,而不是对规则死记硬背。因此,通过这种参数化的预定义方法来实现虚拟摄影中的相机控制是很难行得通的。

图1. 我们从给定的样例视频(右)中提取出相机行为与演员行为之间的关系,将该关系用于新场景(左)的拍摄,使得新场景拍摄的效果与样例视频相似。
由于镜头语言具有很强的语义性,且很难进行归纳总结,因此,我们提出通过样例视频来对期望的拍摄方法进行控制。如图1所示,对于一个新场景,用户指定期望的拍摄效果对应的样例视频,我们的算法从该样例视频中分析出相机行为与场景中演员行为之间的关系,并将该关系用于新场景的相机控制中,最终实现新场景的拍摄效果与样例视频相同。
02
本文算法
为了实现这个目标,本文算法框架分为三个部分,具体如图2所示:
样例视频演员与相机信息估计(Estimation);
样例视频相机行为分析(Gating);
新场景相机轨迹预测(Prediction)。

图2. 算法框架分为三个部分,(左)样例视频演员与相机信息估计,(中)样例视频相机行为分析,(右)新场景相机轨迹预测
样例视频演员与相机信息估计(Estimation)
演员的信息和相机坐标都在三维空间下,而三维相机位姿估计和演员的三维骨架估计目前已有方法的精度在我们的场景下都不够。因此,我们采用的是复曲面空间(Toric Space)上的相机坐标估计。Toric Space 是基于两个目标构建的局部坐标系,SIGGRAPH 2015年的文章[2]论证了 Toric Space 在相机轨迹规划、设计、插值上的优越性。Toric space 将相机的 6DOF 坐标转换为了更直观的 toric 坐标 (p1, p2, θ, φ),其中 p1, p2 表示人物在屏幕上的位置,θ,φ 分别表示偏航角和俯仰角。通过 toric 坐标,可以更容易地表示拍摄得到的视觉效果。对于演员信息,我们只估计人物之间朝向的夹角和距离,太多的演员细节会导致模型泛化能力不够。
首先,通过 LCR-Net[3]的方法先将屏幕中人物的 2D 骨架提取出来,经过人物匹配,只保留两位“主角”的信息(因为 toric space 有且仅有两个目标),然后将人物骨架的 2D 屏幕坐标输入网络,估计相机坐标和演员信息。

图3. 通过LCR-Net提取骨架,经过处理后输入神经网络进行估计
相机行为提取和相机轨迹预测(Gating+Prediction)
由于相机的行为是无 label 的,且需要网络有能力自动识别当前的相机行为,我们借鉴了 MANN[4]中学习四足动物的运动的方法,通过一个 Gating 网络,输入参考相机行为,输出若干个 expert 值,然后以 expert 值为系数,线性组合 Prediction 网络的权重,这样每组 expert 就对应一种相机行为。
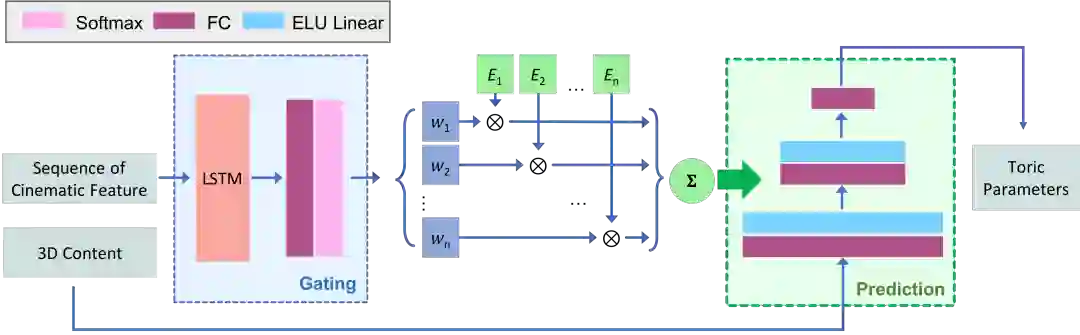
图4. Gating+Prediction网络,Gating输入一长段拍摄序列,输出一组expert值,prediction采用自回归的方式,从过去1s的拍摄和expert推断出下一帧的相机toric坐标
如图4所示,在实践中,我们 Gating 采用 LSTM,输入较长的序列(>400帧,因为太短的网络很难辨别出其中包含的相机行为),Prediction 则采用多层全连接,采用自回归的方式,输入过去 1s 的相机坐标和前后 1s 演员的行为特征,预测下一帧相机的坐标。
03
实验结果
我们采用生成数据来训练 estimation 网络,同时采用生成数据和真实数据来训练 gating+prediction 网络,然后在两个虚拟场景中测试了我们的算法。
我们在分别在“对话场景”和“打斗场景”中测试了我们的算法。“对话场景”中,人物运动较慢,“打斗场景”中,人物运动较快,而且有很多障碍物。通过选取不同的参考视频,并运用到视频的不同时间段,我们最终得到了不同的拍摄结果(在打斗场景中,我们在全局中可视化了两条相机轨迹)。
对话场景拍摄结果
打斗场景拍摄结果
完整的结果和细节请观看以下视频:
欢迎访问项目主页,数据和代码都将开源,敬请期待。
参考
[1] Grammar of film language
[2] Intuitive and Efficient Camera Control with the Toric Space
https://dl.acm.org/doi/abs/10.1145/2766965
[3] LCR-Net: Real-time multi-person 2D and 3D human pose estimation
http://lear.inrialpes.fr/src/LCR-Net/
[4] Mode-Adaptive Neural Networks for Quadruped Motion Control
https://dl.acm.org/doi/10.1145/3197517.3201366
SIGGRAPH (Special Interest Group on Computer GRAPHics and Interactive Techniques) 是计算机领域规模最大的顶级会议、CCF A类会议,参加人数达2万余人,每年收录百余篇图形学相关的优秀论文,是计算机图形领域集技术、艺术与展览于一体的盛会。因新冠疫情影响,SIGGRAPH 2020将首次以在线方式举行。

图文 | 蒋鸿达
Visual Computing and Learning (VCL)
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GRL59” 可以获取《Mila唐建博士最新《图表示学习:算法与应用》研究进展,附59页ppt》专知下载链接索引






