UIUC韩家炜:从海量非结构化文本中挖掘结构化知识
【导读】如何从大规模文本中挖掘知识是个重要问题。最近数据挖掘大师韩家炜做了“从海量非结构化文本中挖掘结构化知识”报告,阐述了最新文本挖掘方面的进展,非常值得关注!

韩家炜是美国伊利诺伊大学香槟分校计算机系教授,IEEE和ACM院士,美国信息网络学术研究中心主任。曾担任KDD、SDM和ICDM等国际知名会议的程序委员会主席,创办了ACM TKDD学报并任主编。在数据挖掘、数据库和信息网络领域发表论文600余篇。
韩教授曾获2004 ACM SIGKDD创新奖、2005 IEEE计算机分会技术成就奖、2009 IEEE计算机分会WAllace McDowell Award和2011 Daniel C. Drucker Eminent Faculty Award at UIUC等奖项。
http://hanj.cs.illinois.edu/
从海量非结构化文本中挖掘结构化知识

现实世界的大数据很大程度上是动态的、相互关联的、非结构化的文本。将这种海量的非结构化数据转化为结构化知识是一个迫切需要解决的问题。许多研究人员依靠人工作业的标签和管理从这些数据中提取知识。然而,这种方法是不可扩展的。我们认为,大量文本数据本身可能会揭示大量隐藏的结构和知识。通过预训练的语言模型和文本嵌入方法,可以将非结构化数据转化为结构化知识。在这次演讲中,我们介绍了我们小组最近开发的一套用于此类探索的方法,包括联合球形文本嵌入、判别性主题挖掘、分类法构建、文本分类和基于分类法的文本分析。我们证明了数据驱动方法在将海量文本数据转化为结构化知识方面是有前途的。
目录内容:
动机 Motivation: Mining Unstructured Text for Structured Knowledge
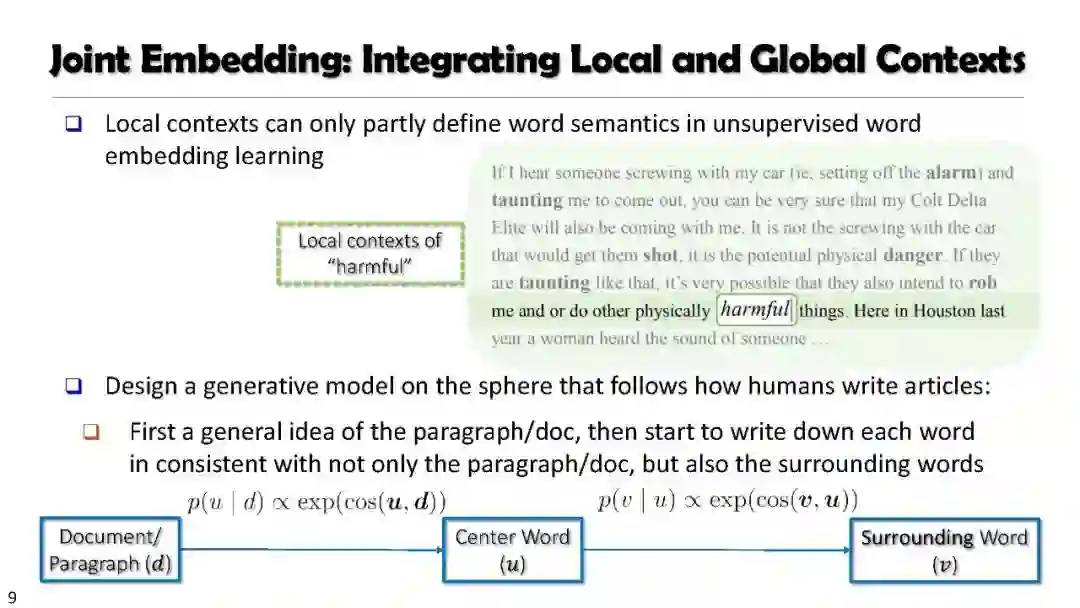
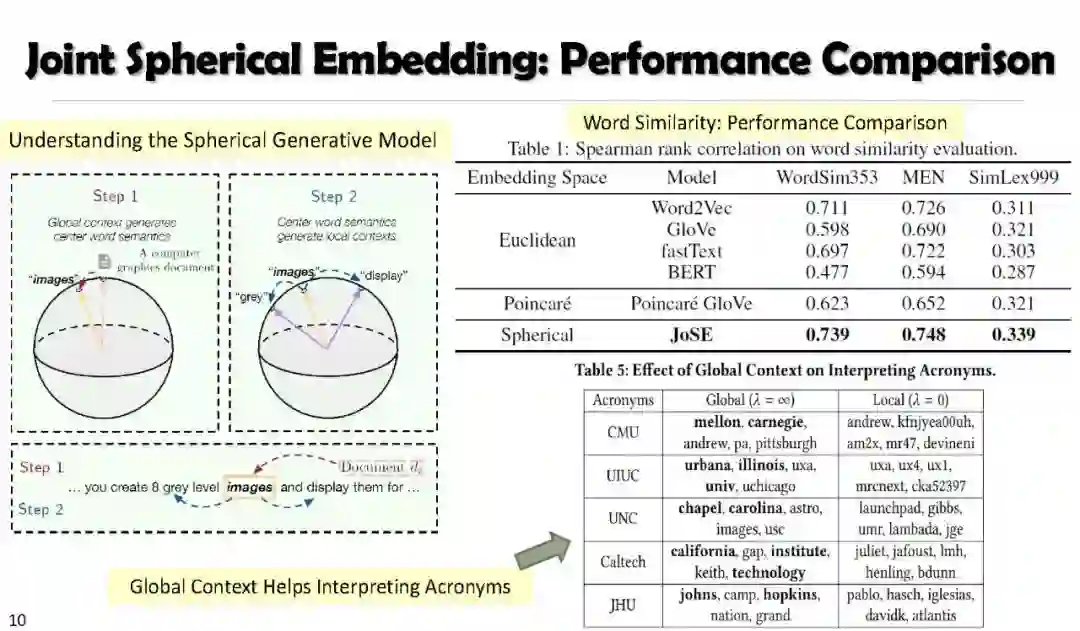
理解语义Understanding Semantics: Text Embedding and Spherical Text Embedding (JoSE)
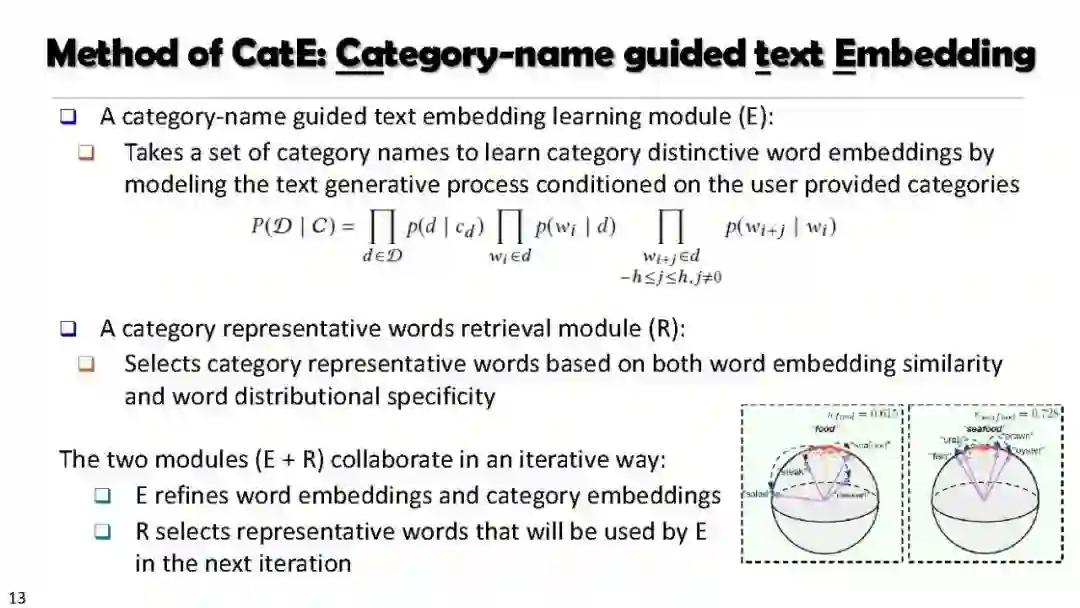
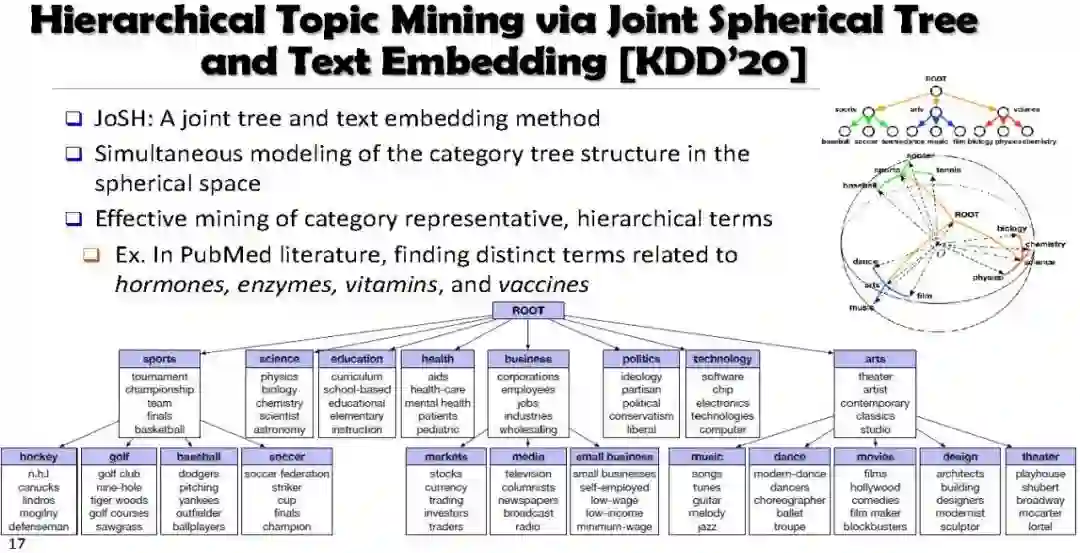
主题挖掘 Weakly Supervised, Discriminative, Hierarchical Topic Mining (CaTE, JoSH)
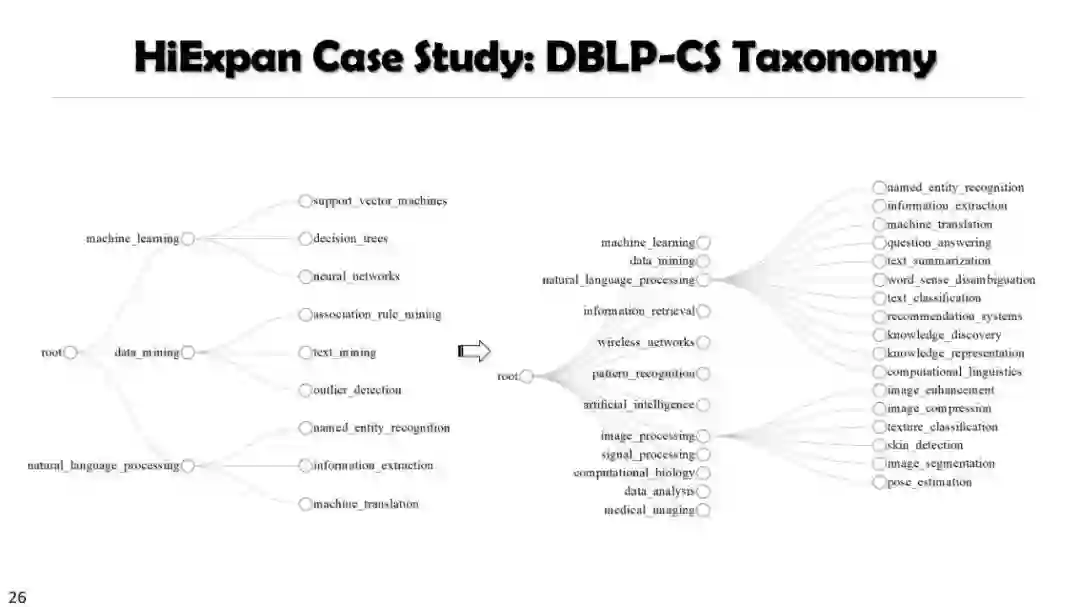
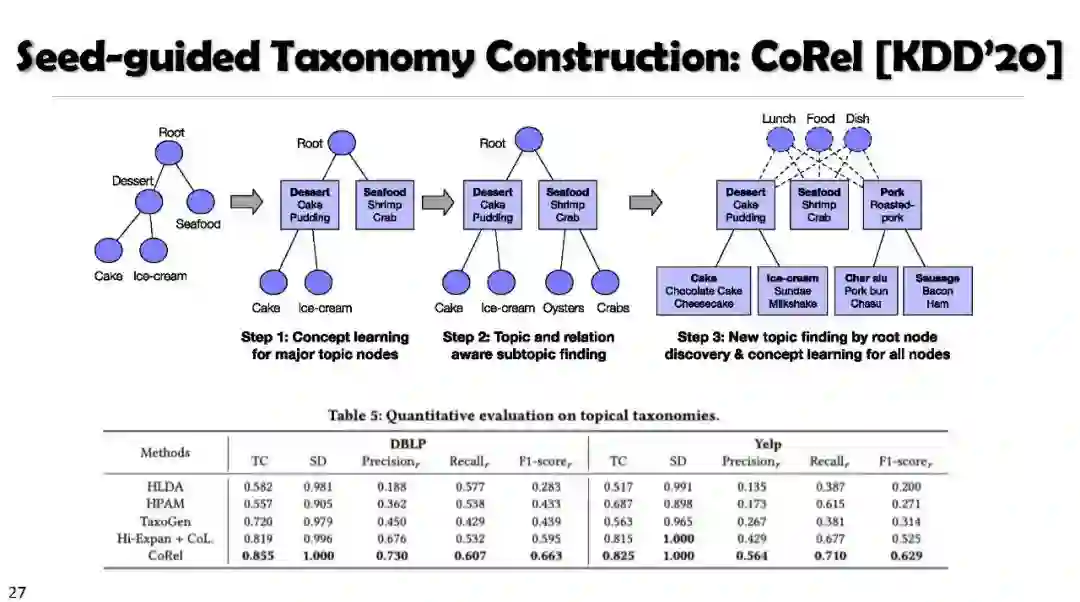
自动分类法构建 Automated Taxonomy Construction and Enrichment
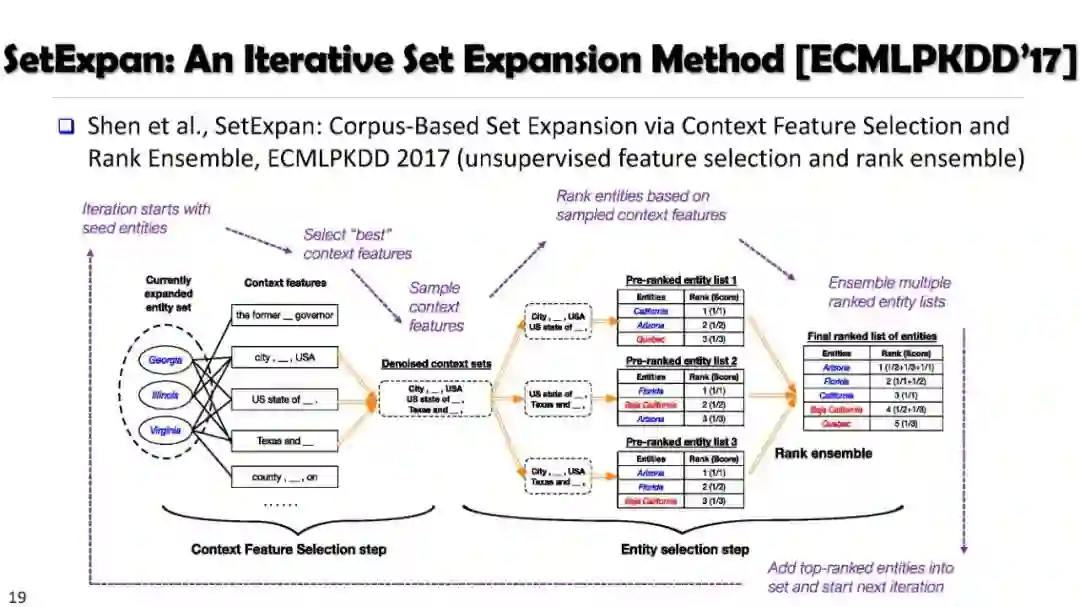
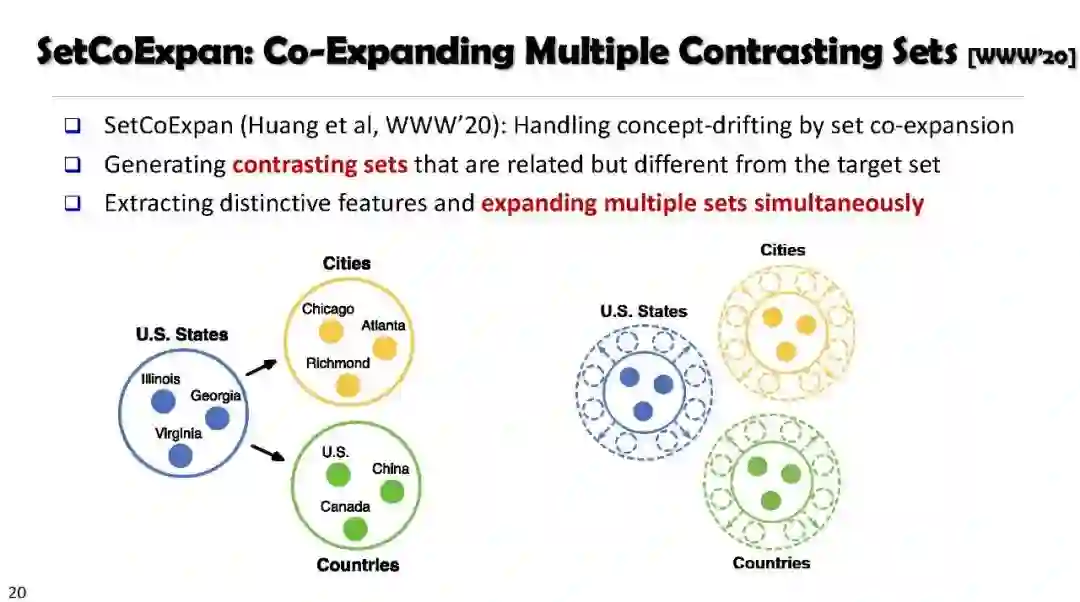
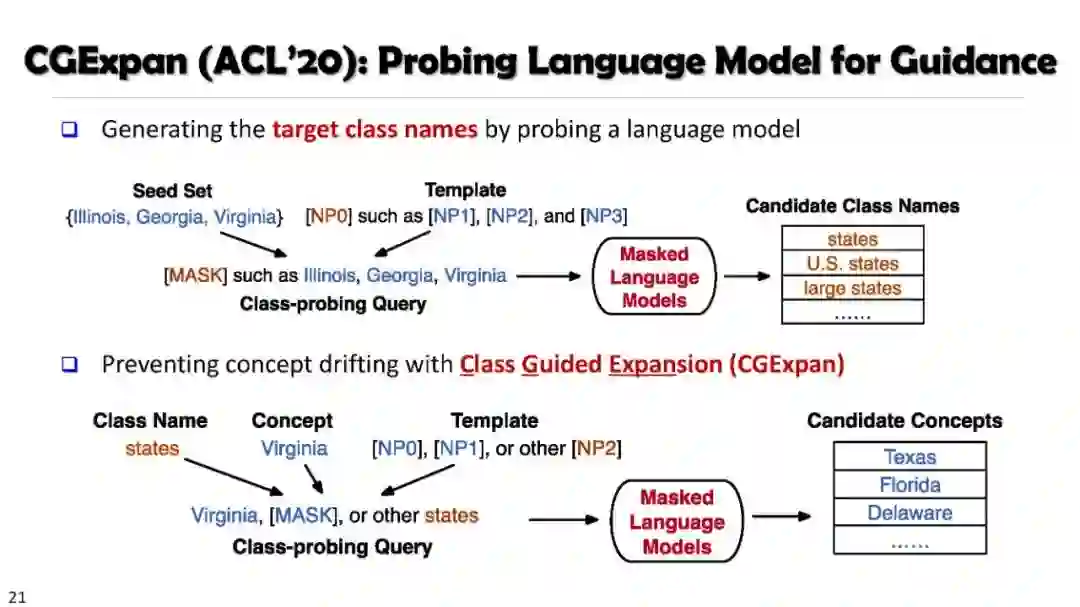
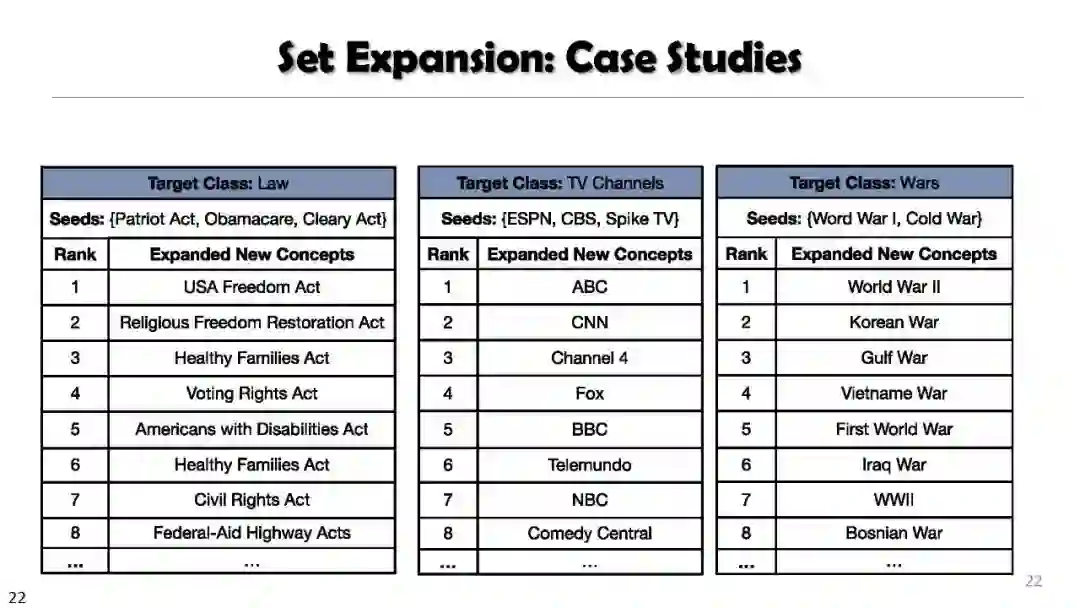
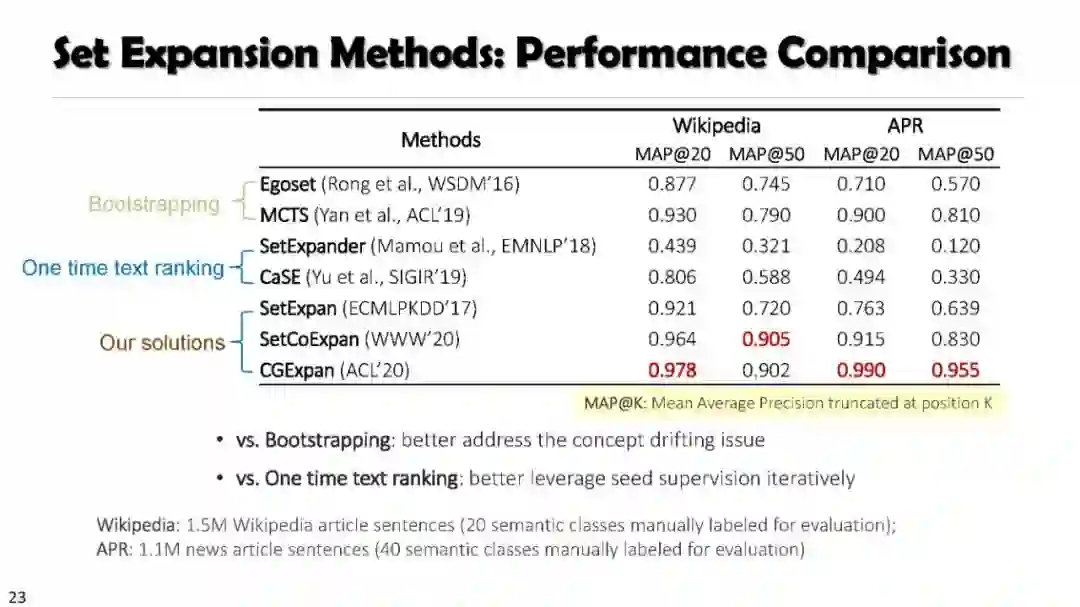
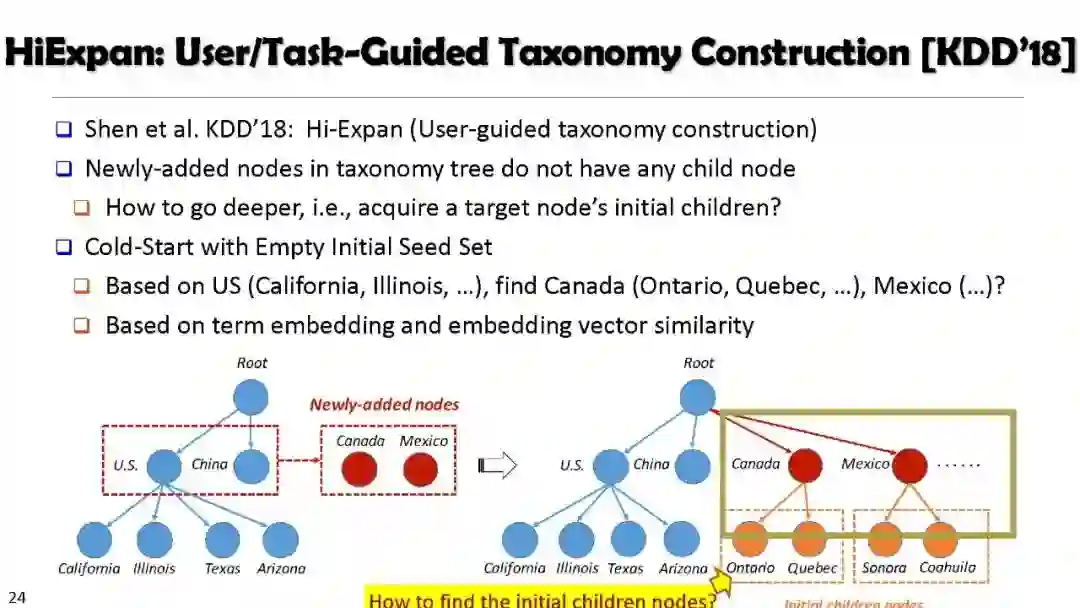
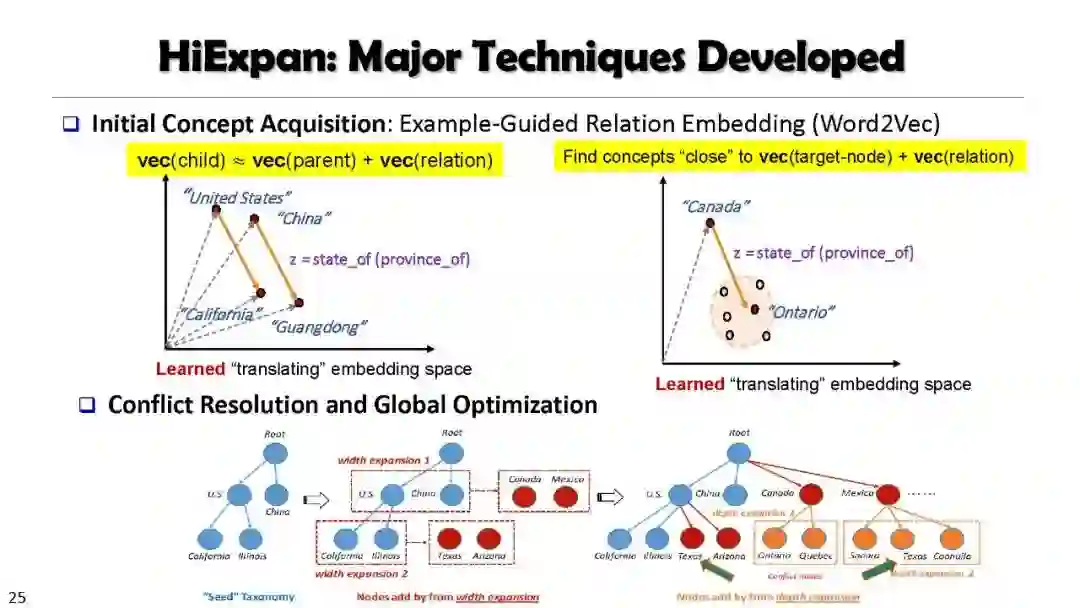
SetExpan, SetCoExpan, CGExpan, HiExpan, CoRel
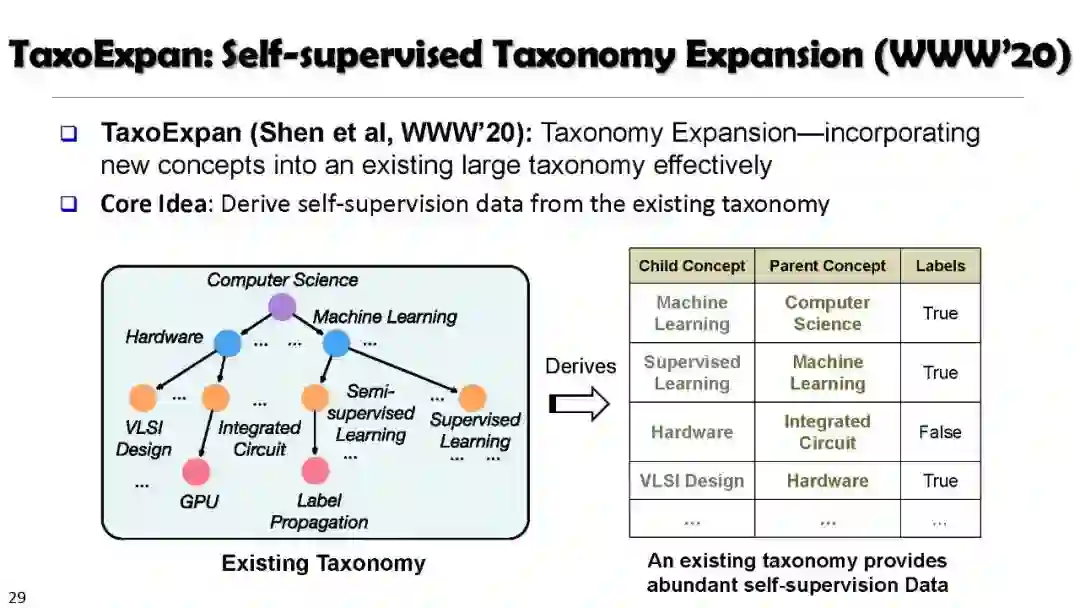
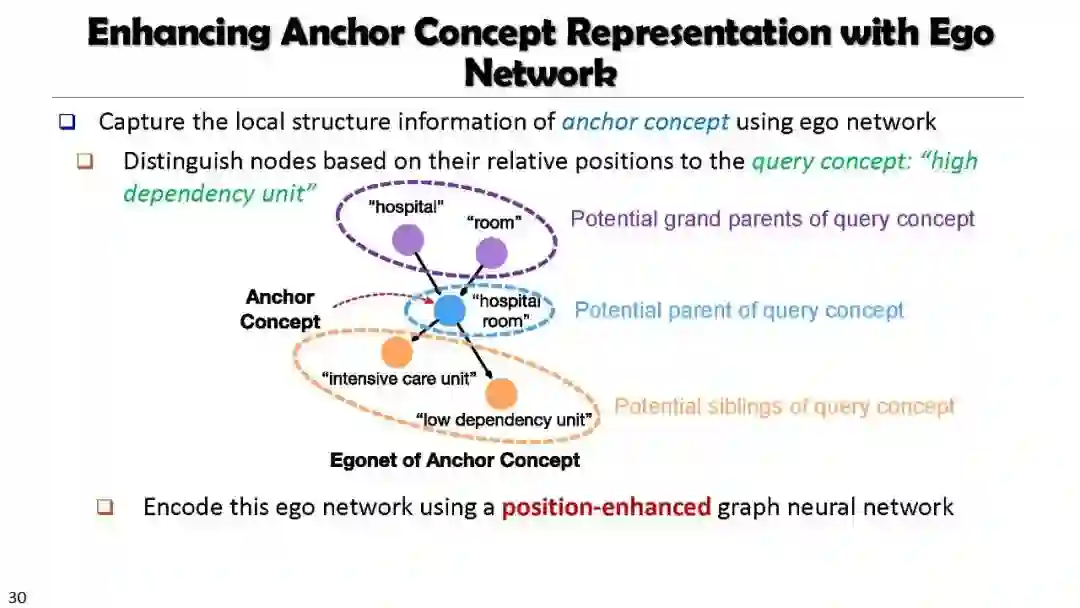
Automated Taxonomy Enrichment (TaxoExpan)
文档分类 Document Classification by Weak Supervision
Weakly supervised: Using Category-Names Only (LOTClass)
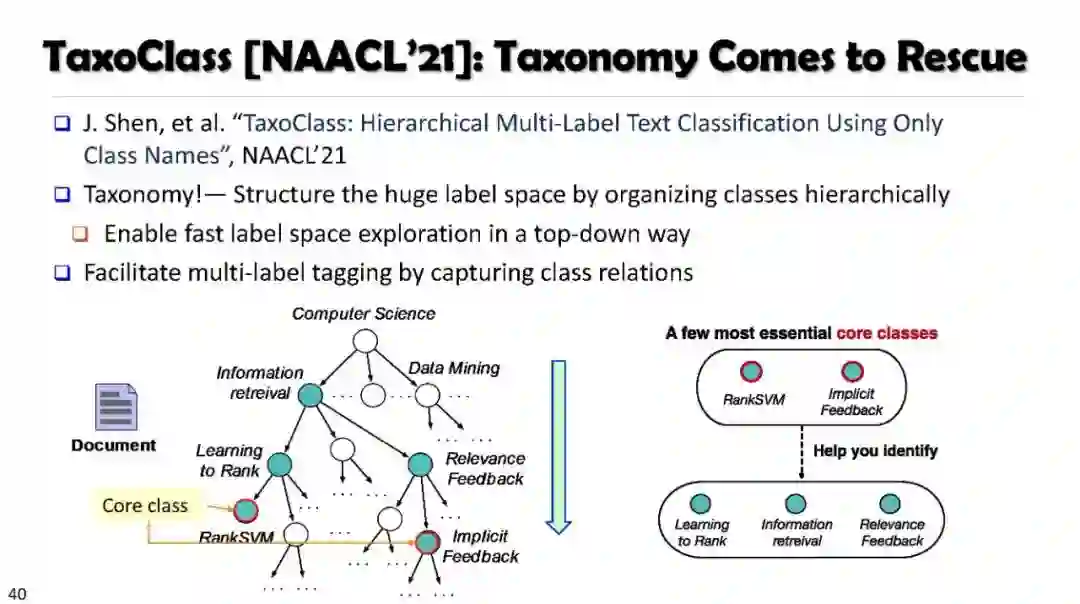
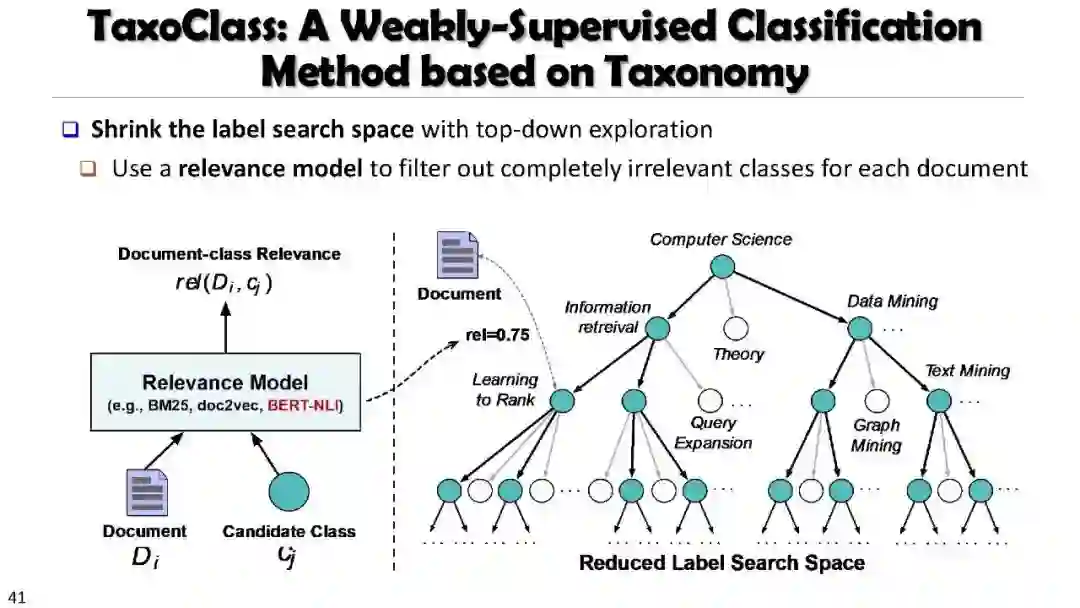
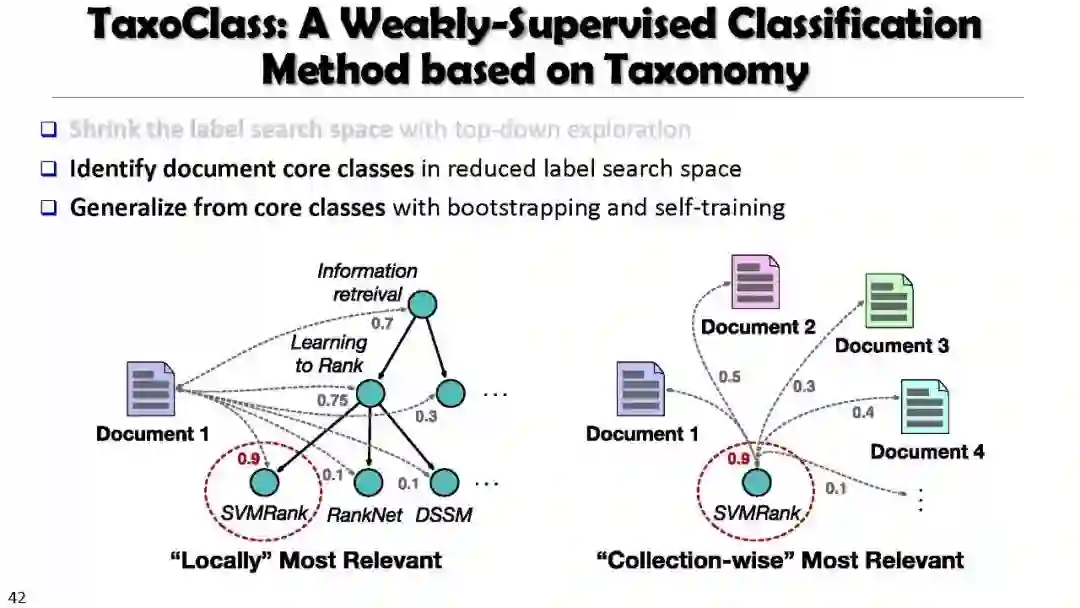
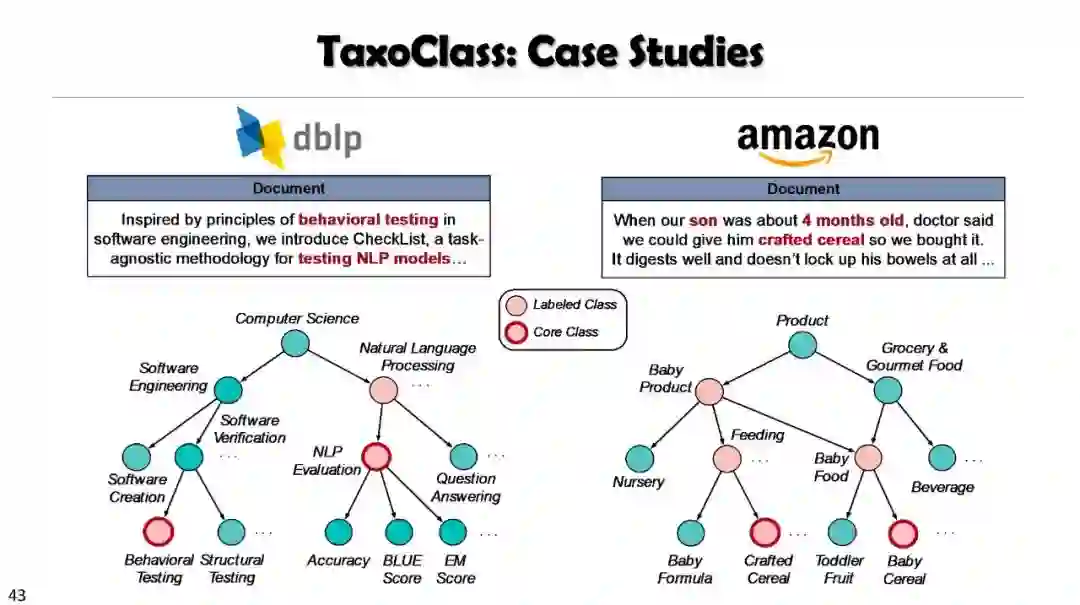
Weakly Supervised Multiclass Classification Using Taxonomy (TaxoClass)
Looking Forward


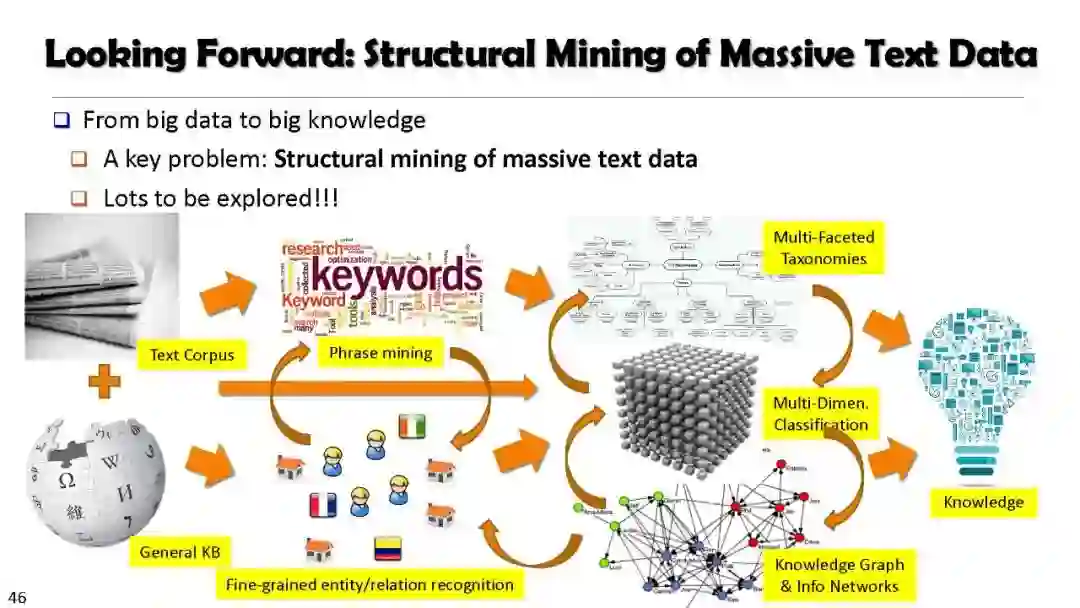
现实世界中80%大数据都是个结构化文本,在很大程度上是非结构化的、互联的和动态的,且以自然语言文本的形式出现,将此类庞大的非结构化数据转换为有用的知识是在大数据时代的一条必由之路。目前大家普遍采用劳动密集型的方法对数据进行打标签从而提取知识,这种方法短时来看可取,但却无法进行扩展,特别是许多企业的文本数据是高度动态且领域相关。
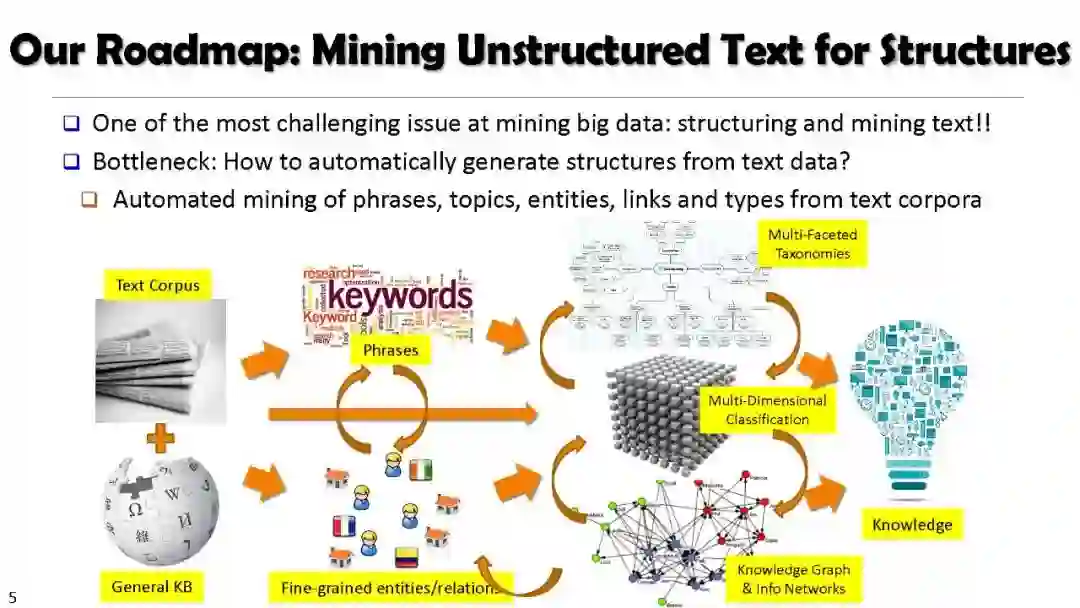
(3)挖掘 Network/Text Cube 生成有用的知识。 最后一步才是挖掘。





















专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MSKU” 就可以获取《UIUC韩家炜:从海量非结构化文本中挖掘结构化知识》专知下载链接




