Python 分析 10 万条弹幕告诉你:《古董局中局2》到底好不好看?


今天我们聊一聊《古董局中局2》
点击下方视频,先睹为快:
上周日,有一部鉴宝题材的剧静悄悄上线了,那就是夏雨、魏晨等主演的古董局中局系列第二部《古董局中局2鉴墨寻宝》(下文简称为《古2》)。

这部剧制作团队是《怒晴湘西》《龙岭迷窟》等网剧的经典配置——管虎监制+费振翔导演。按理说有了《龙岭迷窟》的成功,费振翔导演应该更加得心应手,但是《古2》的就完全没有《龙岭迷窟》给人带来的惊艳感了,有些地方还有点不尽人意。

经典鉴宝题材IP,从小说到桌游
首先要给不知道《古董局中局》的小伙伴们科普下,《古董局中局》一共4部,是马伯庸执笔的,小说连载后就引起了热潮,备受追捧。
因为题材和剧情设置,被知名桌游公司改编成了桌游,更在当时风靡一时,各大桌游店都在玩古董局中局,最后腾讯出手,买下版权,改编成了电视剧。
关于《古董局中局》桌游的玩法,简单介绍下就是分为红黑两个阵营,红方以许愿为代表,家族遭到黑方陷害,想为家族平冤昭雪,以打败黑方为己任。黑方以老朝奉为代表,想统治古玩市场,势力通天,双方谁都不知道对方的真实身份,在各种古玩案件里面斗智斗勇。

豆瓣7.1分,《古2》拍的怎么样?
其实这并不是《古董局中局》第一次影视化,在2018年时就由夏雨、乔振宇、蔡文静主演了第一部,剧情较原著改编幅度较大,而且后期剧情较为冗杂拖沓,无关紧要、可有可无的场面和对话太多,导致剧情崩坏,最终豆瓣评分只有6.7分。

本次第二部依旧夏雨饰演主角许愿,而其他配角都大换血,药不然和黄烟烟分别换成了阿丽亚。
故事主要根据原著第二部和第四部的内容,讲的是夏雨饰演的许愿是北京潘家园小古董店"四悔斋"的老板,古董鉴宝界最具权威的"五脉梅花"家族之一许家,唯一的传人。为了楸出隐藏在五脉之中的"老朝奉"造假势力,许愿孤身一人入局破局,与庞大的古董造假集团展开层层较量,却被设局指引牵扯出两幅《清明上河图》真赝难辨的惊天秘密。
夏雨的痞劲真是高度还原原著书中许愿,一看就是胡同串子,但是第二部女主换人,看看网上的评价,吐槽不少。

剧情方面虽然也存在各种槽点,但是这部剧后面还是高度还原小说的,现在豆瓣评分也稳定在7.1分,成绩还是不错的。
我们分析整理了《古2》在豆瓣的评分数据:
总体评分情况
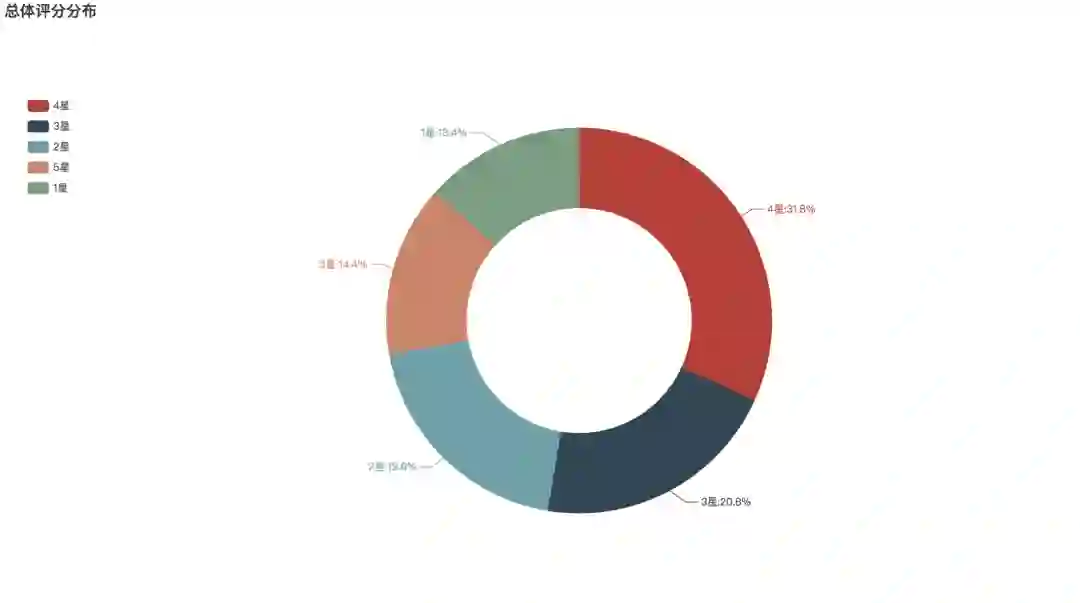
首先看到总体评分情况,其中给四星的最多,共占31.8%,其次20.8%的人给出了3星,19.6%的人给出了2星。
短评词云

在豆瓣大家对这部剧的评价如何呢?
通过分析豆瓣的短评可以看到,讨论最多的就是夏雨的演技,夏雨的演技还是有保障的。同时女主黄烟烟也是讨论的焦点之一,在许多书迷看来,黄烟烟本是个冰山美人,现在怎么变成一这么活泼的北京妞儿?实在是有点不符合人设。
除此之外,词云针对“剧情”“原著”方面的讨论很多,除了吐槽,评论中表示“喜欢”“不错”等肯定的声音也不少。

看《古2》时,弹幕中大家都在讨论些什么
接着我们来分析下这部剧在腾讯视频的弹幕数据,这次我们还是用的Python,我们总共收集整理了107570 条弹幕。
弹幕字数分布
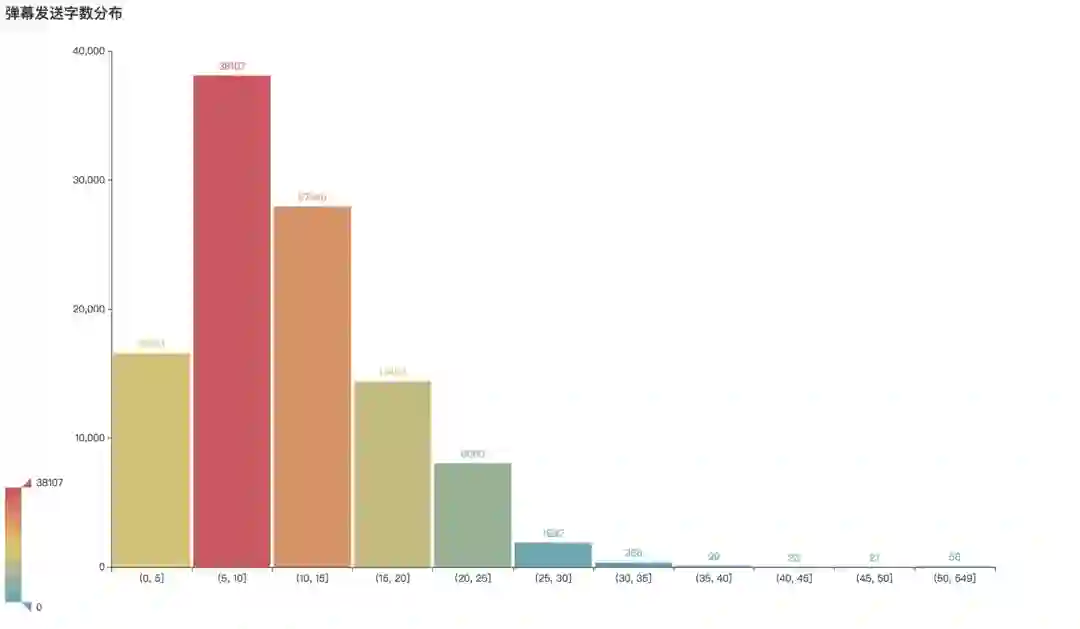
下面看到分析结果,首先在弹幕发送的数据上很有意思,发送弹幕字数最多的不是5字以下,而是5-10字,这部分弹幕共有38107条,其次10-15字的弹幕也不少,为27948条。
单人弹幕发送量
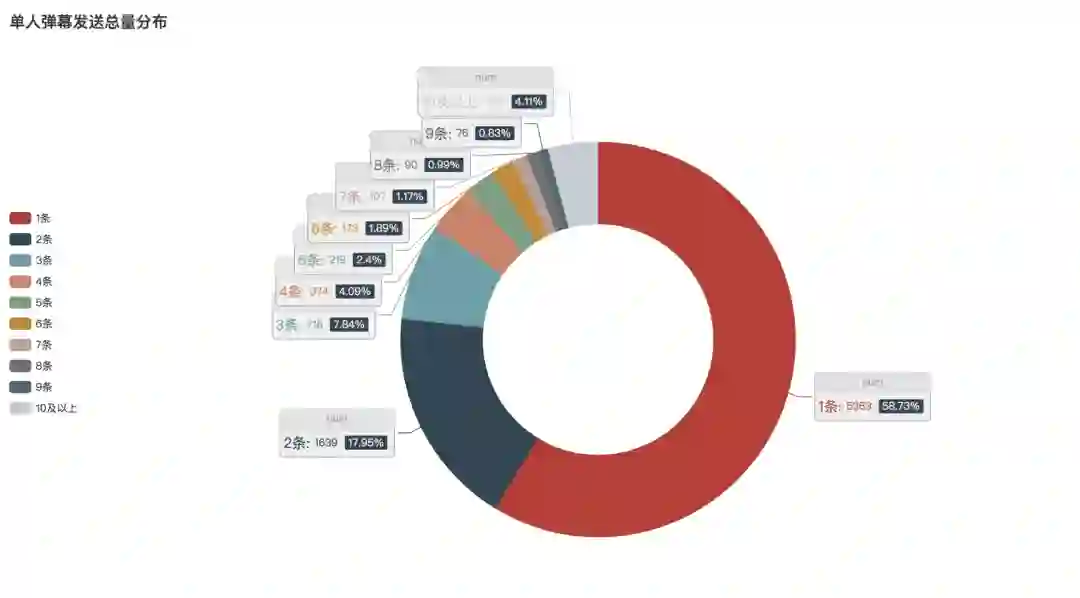
看剧时大家发弹幕的习惯又如何呢?通过分析可以发现,高达58.73%的人都只发了一条弹幕。17.95%的人发了两条弹幕。
弹幕关注人物分布
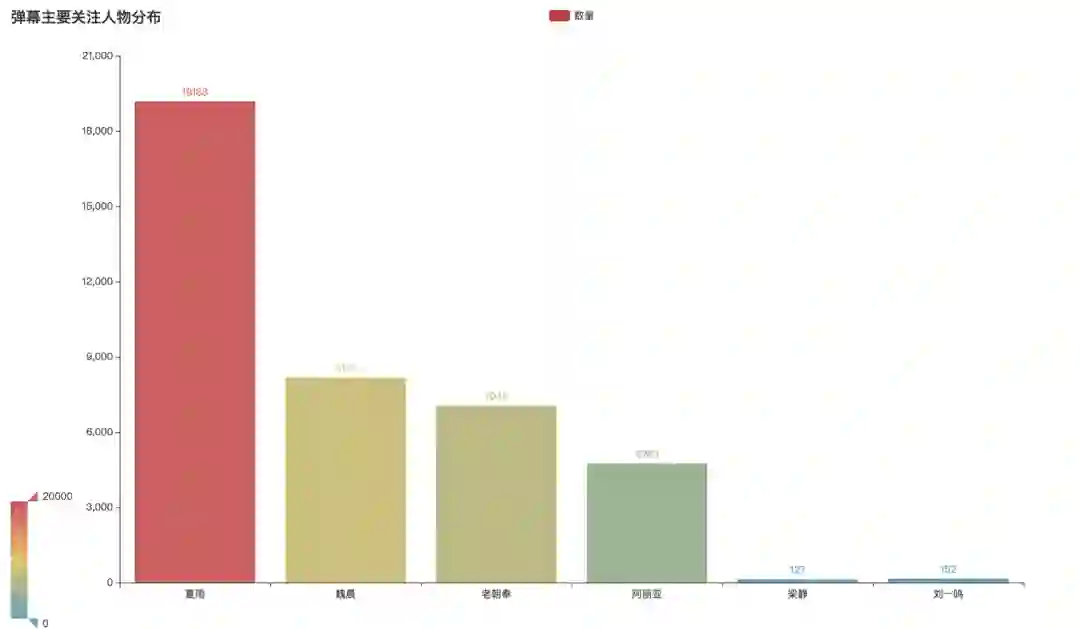
发弹幕时,大家讨论的主要人物都有哪些呢?经过数据分析整理可以发现,讨论最多的当然是我们的男主夏雨。其次分别是魏晨、老朝奉、阿丽亚等演员。
人物弹幕画像
夏雨饰演--许愿


先看到夏雨饰演的许愿这一角色弹幕画像,弹幕中观众们都对夏雨的演技表示了肯定,“厉害”“好看”“喜欢”等都是高频词。夏雨不必多说,影帝就是影帝,演技一如既往得稳。总之,夏雨把许愿这个有点吊儿郎当但是内心又充满着正义感和使命感的北京小青年演绎得淋漓尽致。
魏晨饰演--药不然


关于魏晨饰演的药不然,观众们认为,虽然比起第一部少了点贵公子的感觉,但魏晨版药不然也还不错,药不然的玩世不恭、混不吝都变现的很有分寸。评论中感叹魏晨演技还不错,演出了“痞帅”的感觉,还挺令人眼前一亮。同时也有跟第一部乔振宇版进行对比的。
阿丽亚饰演--黄烟烟


最后看到阿丽亚饰演的黄烟烟角色词云,这个角色的争议就很大了。比起第一部冷若冰霜的冰山美人,这一部版的黄烟烟转眼变成了活泼的北京大妞。这方面还是让观众们挺难接受的。在词云中感叹“一言难尽”“出戏”“失望”的词频出。

教你用Python分析《古2》腾讯视频弹幕
关于数分析部分,我们获取了腾讯弹幕的数据并进行了以下的分析,以下为部分分析代码。
弹幕发送字数分布
单人弹幕发送总量分布
弹幕情感评分分布
弹幕主要关注人物分布
弹幕人物画像(代码暂略)
首先导入数据处理和相关的绘图库。
# 导入库
import numpy
as np
import pandas
as pd
import matplotlib.pyplot
as plt
import jieba
import jieba.analyse
from snownlp
import SnowNLP
from pyecharts.charts
import Bar, Pie, Line, WordCloud, Page
from pyecharts
import options
as opts
01 弹幕基本概况
爬取到的弹幕是这样子的,一共包含了以下信息:集数、评论ID、用户名、vip等级、评论内容、评论时间点和评论点赞。
# 读入数据
df_1 = pd.read_csv(
'./data/古董局中局2腾讯弹幕.csv', encoding=
'utf-8', engine=
'python')
df_1.head()
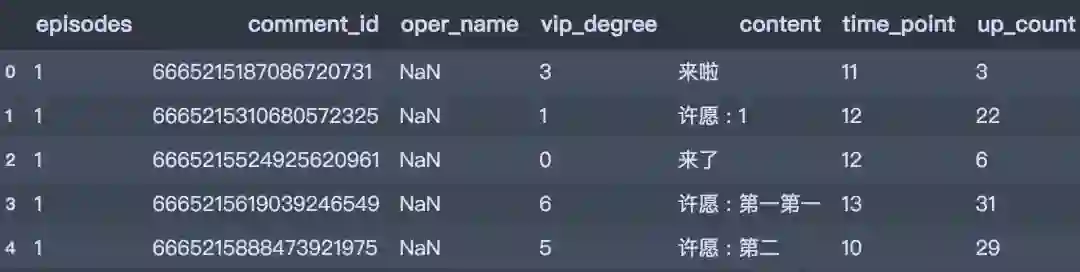
一共有107570条弹幕数据。
df_1.info()
<
class 'pandas.core.frame.DataFrame'>
RangeIndex:
107570 entries,
0 to
107569
Data columns (total
7 columns):
episodes
107570 non-
null int64
comment_id
107570 non-
null int64
oper_name
25539 non-
null
object
vip_degree
107570 non-
null int64
content
107570 non-
null
object
time_point
107570 non-
null int64
up_count
107570 non-
null int64
dtypes: int64(
5),
object(
2)
memory usage:
5.7+ MB
02 弹幕字数分布
# 计算字数
word_num = df_1['content'].apply(lambda x:len(x))
# 分箱
bins = [0,5,10,15,20,25,30,35,40,45,50,549]
word_num_cut = pd.cut(word_num, bins).value_counts().sort_index()
# 柱形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(word_num_cut.index.astype('str').tolist())
bar1.add_yaxis(
"", word_num_cut.values.tolist(), category_gap='4%')
bar1.set_global_opts(title_opts=opts.TitleOpts(title=
"弹幕发送字数分布"),
visualmap_opts=opts.VisualMapOpts(max_=38107)
)
bar1.render()
03 弹幕情感分析
def nlp_score(x):
"""
功能:获取情感评分
"""
sn = SnowNLP(x)
return sn.sentiments
# 计算情感得分
df_1[
'nlp_score'] = df_1[
'content'].map(
lambda x: nlp_score(x))
# 分箱
score_bins = [
0,
0.1,
0.2,
0.3,
0.4,
0.5,
0.6,
0.7,
0.8,
0.9,
1]
score_cut = pd.cut(df_1[
'nlp_score'], bins=score_bins)
score_cut = score_cut.value_counts().sort_index()
# 绘制折线图
line1 = Line(init_opts=opts.InitOpts(width=
'1350px', height=
'750px'))
line1.add_xaxis(score_cut.index.astype(
'str').tolist())
line1.add_yaxis(
'', score_cut.values.tolist(),
areastyle_opts=opts.AreaStyleOpts(opacity=
0.5),
label_opts=opts.LabelOpts(is_show=
False))
line1.set_global_opts(title_opts=opts.TitleOpts(title=
'弹幕情感评分分布[0~1]'),
# toolbox_opts=opts.ToolboxOpts(),
visualmap_opts=opts.VisualMapOpts(max_=
22288))
line1.set_series_opts(linestyle_opts=opts.LineStyleOpts(width=
4))
line1.render()
04 弹幕关注人数数量占比
def calculate_nums(words_list):
"""
功能:给定关键词列表,计算弹幕出现次数
"""
pattern =
'|'.join(words_list)
num = int(df_1[
'content'].str.contains(pattern).sum())
return num
# 关键词
xiayu = [
'许愿',
'夏雨',
'下雨']
weichen = [
'药不然',
'魏晨',
'药二爷',
'晨晨',
'老魏',
'晨哥',
'晨']
laochaofeng = [
'老朝奉',
'老朝凤',
'老朝',
'老嘲讽',
'老巢']
Aliya = [
'黄烟烟',
'阿丽亚',
'烟烟']
liangjing = [
'梁静',
'素姐']
liuyiming = [
'一鸣',
'毕彦君']
all_list = [xiayu, weichen, laochaofeng, Aliya, liangjing, liuyiming]
danmu_name = [
'夏雨',
'魏晨',
'老朝奉',
'阿丽亚',
'梁静',
'刘一鸣']
danmu_num = [calculate_nums(i)
for i
in all_list]
# 柱形图
bar2 = Bar(init_opts=opts.InitOpts(width=
'1350px', height=
'750px'))
bar2.add_xaxis(danmu_name)
bar2.add_yaxis(
'数量', danmu_num)
bar2.set_global_opts(title_opts=opts.TitleOpts(
'弹幕主要关注人物分布'),
visualmap_opts=opts.VisualMapOpts(max_=
20000))
bar2.render()
《古董局中局2》数据分享:
链接: https://pan.baidu.com/s/1bqpPDCcoBUNKPK4m15iE1g 提取码: 9ywa


更多精彩推荐
☞登 GitHub 趋势榜首德国疫情追踪 App 号称可保疫情隐私数据无忧,你信吗?
☞百度否认退市;微信官方回应「个人影响度报告」;微软公布 C# 9.0 计划 | 极客头条
![]()
你点的每个“在看”,我都认真当成了喜欢






