天天淘宝,你却不知道个性化推荐技术...
在这个时代背景下,信息爆炸与长尾问题普遍发生,而解决方案之一是个性化推荐技术,那具体什么是个性化推荐,怎么去实现这一过程呢?

这篇读者朋友需要做到的是读完以后,对个性化推荐技术有一个全局宏观的认识,对于细节不用过多地苛求。
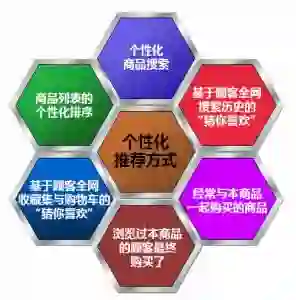
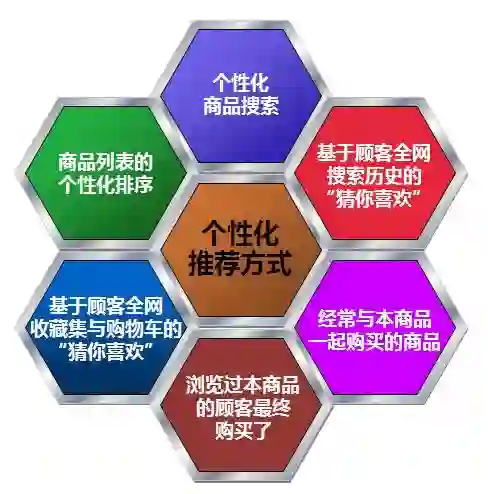
个性化的具象表现:以购物 App(淘宝)为例
在日常生活中,你在打开淘宝购物时,可能会遇到以下若干情形:
和好友同时打开 App 后发现,为什么两个人首页各个频道入口的图片以及文字不一致?
为什么同样搜索可爱小背心,你和好友竟然出现不一样的商品列表?
为什么我刚刚浏览了裤子以后,首页各个频道的展现变了?
为什么在对比好友的以上界面后,我更喜欢我自己的界面?
注:这里频道的概念是指淘抢购/有好货/必买清单等电商频道,不理解的读者可以打开 App,以上情形背后的答案就是个性化推荐技术,当然也包含了相关的搜索技术。
那淘宝是如何做到的呢,其实这背后就是涉及了数据的收集,挖掘计算,以及个性化呈现。
所以基于上面的问题,我们又会问:
淘宝是如何知道我喜欢什么并且可能想要买什么的?
为什么它能做到每个人都不一样?
为什么它要这么做?
淘宝是如何知道的?
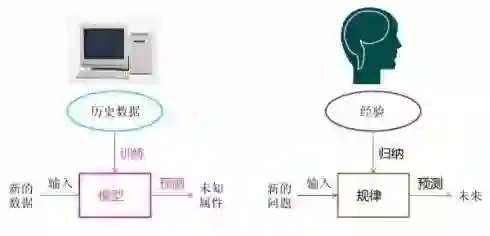
回答这个问题,其实背后是一套机器学习的方法在支撑,所以我们先要弄清楚什么是机器学习。
机器学习概述
我们先看看什么是人的学习,这里主题是人。学习,是指通过阅读、听讲、思考、研究、实践等途径获得知识或技能的过程。
学习分为狭义与广义两种:
狭义:通过阅读、听讲、研究、观察、理解、探索、实验、实践等手段获得知识或技能的过程,是一种使个体可以得到持续变化(知识和技能,方法与过程,情感与价值的改善和升华)的行为方式。
广义:是人在生活过程中,通过获得经验而产生的行为或行为潜能的相对持久的行为方式。学习后的主体在未来的生活中可以将过去学习到的知识,技能应用于生产生活,来开展工作。
那从字面上来理解,机器学习就是将主体换为机器,并且它通过某种途径来获取知识或者技能的过程,并应用于未来的生活工作。
人获取知识的外化载体是书本,音频,视频等,传输通道是人的感官,处理中心是大脑,而对应于机器,外化载体也同样可以有以上各类信息源,并且使用各类外放设备收集信息,处理中心是 CPU 与存储共同维护。
人的学习有两个基本方法,一个是演绎法,一个是归纳法,这两种方法分别对应人工智能中的两种系统:专家系统和机器学习系统。
所谓演绎法,是从已知的规则和事实出发,推导新的规则、新的事实,这对应于专家系统。
专家系统也是早期的人工智能系统,它也称为规则系统,找一组某个领域的专家,如医学领域的专家,他们会将自己的知识或经验总结成某一条条规则、事实。
例如某个人体温超过 37 度、流鼻涕、流眼泪,那么他就是感冒,这是一条规则。
当这些专家将自己的知识、经验输入到系统中,这个系统便开始运行,每遇到一些新情况,会将之变为一条条事实。
当将事实输入到专家系统时,专家会根据规则或事实进行推导、梳理,并得到最终结论,这便是专家系统。
而归纳法是从现有样本数据中不断地观察、归纳、总结出规律和事实,对应机器学习系统或统计学习系统,侧重于统计学习,从大量的样本中统计、挖掘、发现潜在的规律和事实。
举个栗子可能更容易让人理解这一过程,并且对于已经对机器学习有一定了解的同学,我们顺便讲讲什么是特征工程里面的交叉特征与线性/非线性模型。
①数据→单特征(low level 特征)+线性模型→预测
假设有一对情侣,你是主人公(女友),2 个月前,朋友给你介绍了一个男友,他是工作狂。
为了互相了解,你们每周末都会一起约会吃饭;已经约会有 8 周了,每周吃饭男友都会比约定时间晚到 10 分钟-30 分钟,所以你每次约会也会比约定时间晚 10-30 分钟。
并且你总结了一个规律:如果约会前打电话他说在公司,那么基本都是晚到 30 分钟左右,如果他说在家里,那么基本会晚到 10 分钟。
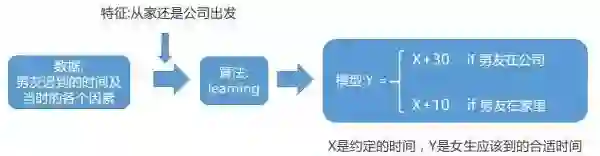
②数据→交叉特征(high level 特征)+线性模型+单特征(low level 特征)+非线性模型→预测
以上情形没有维持多久,男友的迟到时间变多了,有时在公司他会迟到 15 分钟,但是有时在家里却会迟到 20 分钟。
所以有时你到了以后等了很久男友才来,然后经过询问迟到 15 分钟和迟到 20 分钟的具体情况,你又得出了一个结论:如果男友在家并且不开车过来,那一般就要 20 分钟了,如果男友在公司但是他开车过来那就只要 15 分钟。
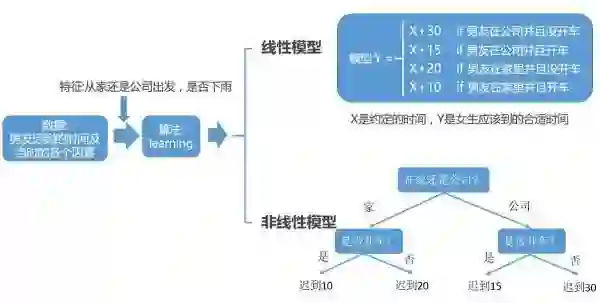
③数据→交叉特征(high level 特征)+单特征(low level 特征)+非线性模型→预测
不过又过了没多久,男友的迟到时间又变了,这次基本上迟到时间在 10-45 分钟之间,并且非常不规律。
然后你总结了经验觉得是不是我要去分析分析本质的原因,然后看看晚到多久合适,于是得到了以下可能对男友迟到时间有用的因素(特征):出发地在哪,是否开车,是否下雨,出发的时间等等。
于是最终你通过分析发现没有找到非常强的规律:下雨(不下雨),男友 HH:MM 从家(公司)出发,开车(不开车)的情况下晚到具体的时间。
但是你分析到下雨天男友在公司晚于 17 点出发的情况下迟到时间一般在 30-45 分钟,不下雨天男友在家早于 17 点出发的情况下迟到时间一般在 10-20 分钟,以及等等情况。
不过你还是想再精确一点,于是你请教了你的好朋友–一个算法工程师,经过他的一番数据挖掘,他告诉你了一个公式,只要按着他的公式计算你晚到的时间即可。
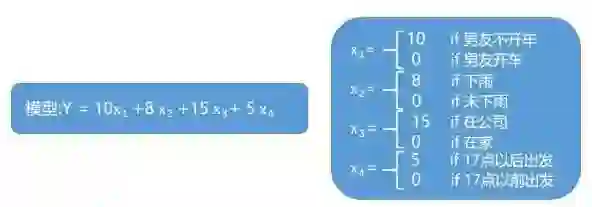
你很想知道他是怎么做到的,于是你开始请教他。他告诉你其实上面的种种因素都可以作为一个变量,每个变量有一个权重;比如天气的权重是 8,当下雨则迟到时间加 8 分钟,不下雨则不加。
再比如开不开车的权重为 10,不开车迟到时间加 10 分钟,开车的时候不加等等。
然后进一步的问题就是这个权重怎么得来的呢?那么学到以上决策机制的流程就需要以下几个要素:
数据:男友历次迟到的时间,以及迟到前的状态(天气,位置,出发时间等等)。
特征工程:比如上面的地点和是否开车的二维联合就是特征工程(交叉特征)。
算法:使用决策树(非线性)还是线性回归(线性)等等其他算法。
学习到模型:主要指上面各个特征的权重组成的公式。
注:这里涉及到一个问题就是权重为多少才是对的权重呢?这里就涉及了一个模型评估的问题。
举个例子,如果利用你学习到的权重模型 A 与模型 B 比较,A 模型在后面的十次约会中累积误差为 10 分钟,而 B 模型为 15 分钟,则 A 模型的权重比 B 好。当然具体算法模型的迭代过程,我们在未来会讲到。
延伸:上面的例子讲诉的就是在机器学习整个框架下,有深挖特征和深挖算法两种。
做特征就是针对具体问题构造各种可能对问题结果有影响的因素(包括单特征与交叉特征)。
深挖算法其实是尝试不同的算法,比如线性与非线性(浅层学习与深度学习算法)。
目前业界比较代表的做法是 LR+深层特征,DNN+浅层特征。上面的三个约会的例子的渐进性其实在这里也正好对应了机器学习中的反馈学习及强化学习,根据男友迟到的时间,女生在动态的调整自己晚到的时间。
机器学习过程中的几个注意点
①从感知到认知:感知的一个重要体现就是数据的获取与收集(可类比人对信息的获取,如眼睛),认知强调理解。
②从学习到决策:学习,对已有数据应用相关算法进行规则/模型的计算归纳;决策,遇到新的问题时,使用学到的知识进行学习。
算法和数据哪个更重要:数据秒杀一切算法,但真正推动社会进步的是算法,而不是数据。
数据就好像是工业革命时期的煤炭,非常重要,蒸汽机就像是算法,最后大家记住的是瓦特发明了蒸汽机,而不是英国的煤矿。
机器学习常见的概念
监督学习
监督学习的数据比较特殊,举个例子,比如你在中学学习英语,在老师的帮助下练习英语发音,数据是你的发音和这个发音的对错/准确程度(对错/准确程度是老师告诉你的)。
然后算法就是你去尝试去模拟数据(发音)的规律,不断根据英语单词的拼写规律来学习发音,最终你学习到了基于拼写及句子的上下文调整发音。
无监督学习
无监督学习的数据中没有人告诉你对错信息,举个例子,今天老师给你了一个碗,里面有黑米有红米,让你对这个碗里的米分个类。
你可能根据颜色分类,也可能根据大小、重要分类,都没有问题,因为老师没说按什么分,对不对这个问题。
降维
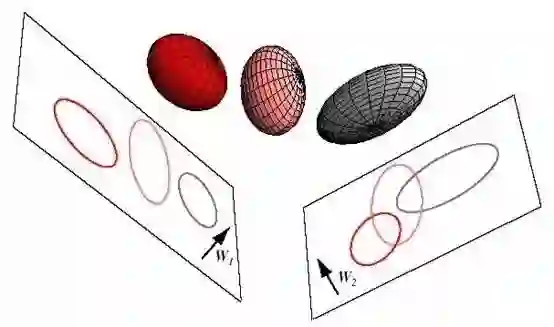
降维是从更基本的维度来看问题,举个例子,<Nike 空军一号>这双鞋,对其降维可以是 Nike 这个运动品牌,也可以是运动鞋这个类目。
泛化
泛化就是你学到的规则/模型的普适程度。举个例子,今天老师让你看了 20 个西瓜,并告诉你熟不熟,然后给你一个西瓜,问你只看外观。这个西瓜熟不熟,你可能根据以下来判断。
可能你是这么做的:看表皮,你发现 20 个瓜里面,瓜皮表面光滑、花纹清晰、纹路明显、底面发黄的瓜都是熟的,但是不满足任何一个条件的都是不熟的。
所以你学到的模型如下:如果瓜皮表面光滑、花纹清晰、纹路明显、底面发黄的,就说明是熟瓜;其他的是不熟的瓜。
但是其实有时候,纹路不明显,但其他条件满足的时候也会有一部分是熟的瓜。所以你学到的模型具有一定泛化性能,但不具有很高的泛化性能。
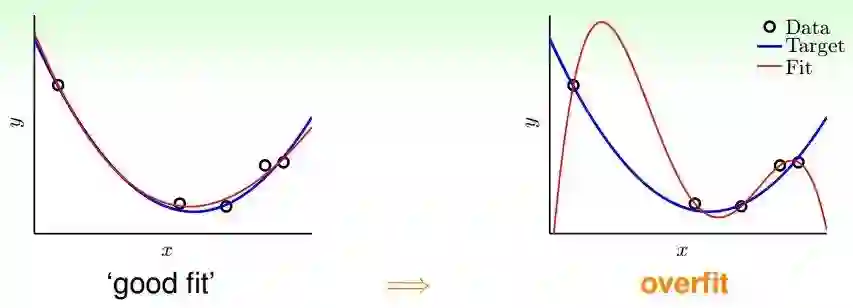
如上图,目标是蓝线,你从 Data 里面学到了左右两条红线,左边的有一些误差,右边的无误差,但是对于真实的目标而言,左边更好,因为日常问题中,你没法获取所有的数据,所有会出现泛化这个问题。
机器学习最难的是什么
机器学习最难的一步,就是把现实生产生活中的问题, 提炼成一个机器学习问题 。
这基于对问题本身的深刻洞察。如何从一个全新的领域, 去提取机器学习可以有助解决的最重要的问题。
淘宝的机器学习
由上面机器学习相关的介绍可以类推淘宝 App 为什么能够知道你喜欢什么,是基于一个假设条件的:一个人历史的购物行为及偏好,会在未来的行为中也有迹可循。
所以利用机器学习我们通过用户历史交互数据(特征包括:谁在什么时间买了什么东西,这个东西的名字叫什么,什么颜色,价格多少等等)。
比较有用的可以对未来推荐有指导意义的特征包括:
购买力,一个平时只买 100 元左右牛仔裤的用户,未来短期内买 10000 元和 10 元的裤子的概率远远低于买 100 左右或者 200 左右的概率,所以推荐的时候会更优先给你看到 100-200 左右的裤子。
性别,平时在淘宝上只买男性或男女通用商品的用户,未来短期内买女性商品概率远远低于男性和男女通用商品的概率。
年龄,一个一直购买 20-25 岁左右服饰的用户,未来短期内购买其他年龄段的概率远远小于 20-25 岁年龄段的概率。
等等。
注:以上特征均会在最后预测用户可能喜欢什么中有用,但是注意一个人也可能很违背之前的购物行为。
比如一个只够买 20-25 岁衣服的女性,突然买了一个婴儿的衣服,可能从这个节点是她小孩诞生或者是给姐姐的小孩买礼物等等,这一瞬时购物兴趣的变化一般由实时推荐 Cover。
为什么能够做到每个人不一样
参看上面的公式你会发现,如果在机器学习阶段考虑一些跟人相关的因素(特征),那这个因素的不同值就会影响结果输出。
比如我们现在根据用户对他购物的商品的评分数据,来预测一个他从未买过的商品的评分,背后影响用户评分的因素可能包括以下几个:价格,售前/后,物流,商家主营类目是否和用户购买的类目相同,其他用户的评分(如果其他用户评分高则一定程度上代表了这个商品的好坏)等等。
比如物流和价格这类因素(特征),如果和用户这个特征做交叉后,其实会有非常迥异的权重值,而这一切是每个用户的购买力和用户体验耐受力等不同带来的。
所以如果你考虑了用户的特征则这就会影响每个人的推荐结果不一样。
为什么淘宝要这么做
至于为什么淘宝会去花这么多资源做个性化,可以概括为以下三点:
获取新的认知
创造新的智慧
产生有价值的决策
从历史数据中探索用户的消费需求,旧数据中挖掘新认知,从新认知出发结合机器学习算法创造新的智慧,最后帮助用户发现他感兴趣的商品,将最适合的商品呈现给他。
长尾挖掘
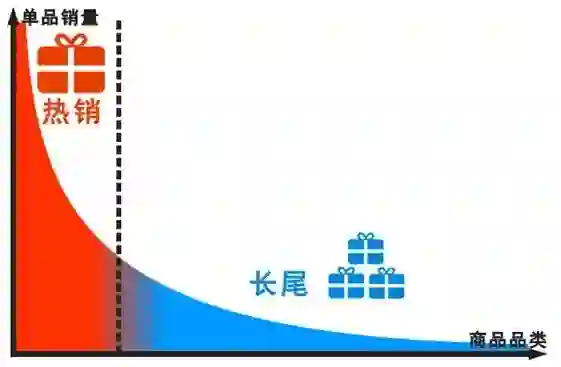
打破 80% 的用户只买 20% 的商品的规律,更好地降低长尾商品的比例。因为在电商产品中,在非个性化的商品展示过程中,往往爆款商品拥有更多的流量,这样其实不能很好的照顾到高质量长尾用户和高质量长尾商品。
举个例子,在淘宝的某个频道,有很多裤子,A 裤子 100 元近 5 天的销量可能 1w 件,B 裤子 1000 元近 5 天的销量是 100 件。
在不考虑其他因素的情况下,非个性化模型(或运营排序)一般会偏向于 A 裤子在 B 裤子前面。
但是如果这个用户在平台历史购物行为都是集中在高价格商品(名牌包包等),则如果你个性化的考虑每个人的这个偏好,那么有可能 B 裤子就在前面了,而且用户可能真的更喜欢 B 裤子。
流量利用
在 App 或网站有限的商品曝光机会下,为每个展现的商品争取最大的点击/成交等。
因为用户在平台上地时间是有限的,如果能在海量的商品中,为用户找到他感兴趣地商品,那么平台将在这有限地流量资源下收获更大的价值。
举个例子,有可能用户在某个频道下,看了 A,然后看了 B,再看了 C,最终买了 D,并且 ABCD 这四个商品都是有一定关系地商品,那么平台能否在一开始在我看完 A 以后就帮我找到 C,并在 A 下面推荐 D 商品。
在最大限度挖掘用户购物需求的情况下,最大限度缩短用户购物的时间。
用户体验
为每个用户创造极致的用户体验。极致的用户体验是用户信任依赖平台,在每次购物过程中,希望平台能够帮助其快速,准确地找到其想要地商品。
这一过程中包括了基于用户历史兴趣的再延伸,也有基于用户角色的行为探索。
比如用户每隔 25-30 天会购买尿不湿,未来平台是否能够在 23-33 之间快速捕捉用户购买尿不湿的需求。
再比如用户在平台上第一次浏览电脑,我基于用户的其他购物行为(比如用户之前在平台上经常买 20-25 岁的衣服,并且大部分邮寄的地址为大学宿舍),是否平台可以在接下来的浏览中为用户呈现适合学生族高性价的电脑。
推荐技术概述
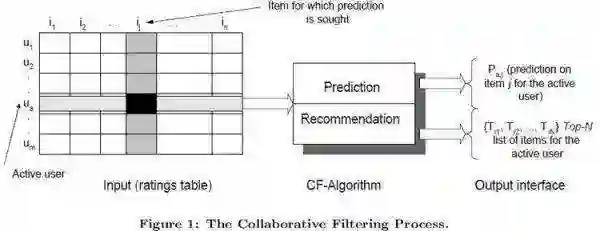
①推荐在电商购买决策过程中的作用
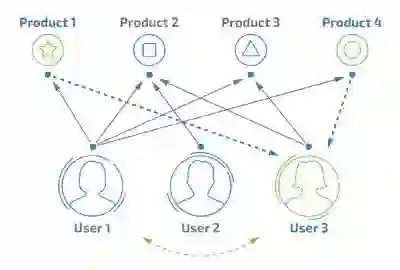
电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程,经典配图:
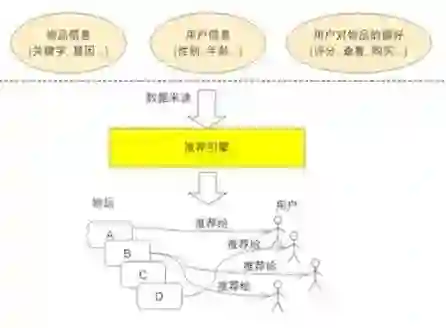
上图隐含的 2 个重要的推荐系统的核心功能:
路径优化(弱化主动筛选功能):从看了 A 再看 B 再看 C,最后买了 C 到看了 A,推荐系统推荐 C,用户下单。
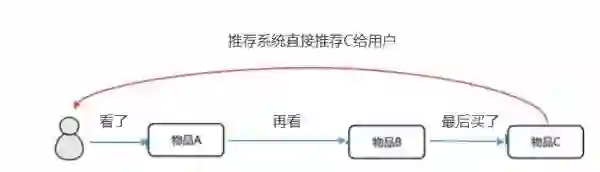
兴趣发现(贴心小秘书):从你上淘宝不知道买什么的时候,告诉你你可能喜欢什么,常用的推荐产品。

②推荐系统是怎么做到的类比人的行为

其实推荐系统做的事可以类比于生活中的贴心男友或者女友,那我们就当他是男友吧,来看看他是怎么做的:
上知天文,下通地理:下雨了,男友知道你没带伞,把伞送到了公司。
察言观色:女朋友一直在看宝宝,尤其是 LV 的,生日那天买了一个。
人情练达:看到和你玩的好的几个闺蜜都买了某款口红,没过几天就买了这款口红。
念念不忘:你经常说的偶像、崇拜的人他会记住,时不时买几个他们的新作品。
体贴入微:他知道你大姨妈来的时候比较喜欢吃甜品,所以到了那几天他都会带你去吃。
紧跟时尚:新品发布,只要是你有兴趣的那个方向的产品,都会买给你。
③推荐系统怎么来做到上面这些方面呢
上下文:推荐系统会在给你推荐商品时将考虑你所在的城市、天气、季节等因素;梅雨天伞比平时好卖,夏天空调需求比秋天高等,北方人比南方人更喜欢保湿的化妆品。
用户画像:男-女/经期时间/甜品这些都可以做成标签,作为推荐的依据,上次你买的姨妈巾/纸尿裤/奶粉多少天会用完,19 岁男生一般不会(低概率)买女性比基尼。
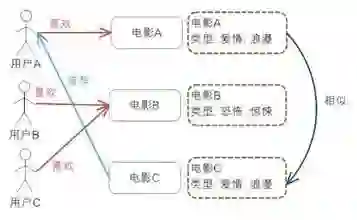
协同过滤:基于用户:在茫茫购物的人海中,总有那么一些人是跟你非常像的(类似上面的闺蜜);推荐系统根据你们的行为(浏览、点击、购买)计算跟你最像的那些用户,当他们看了/买了什么的时候,他就可能会推荐这些商品。
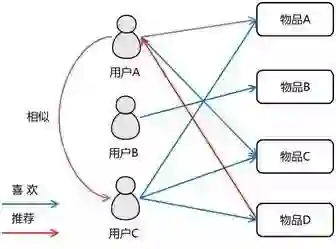
基于商品:在茫茫商品中,总有一些商品他们的属性、描述很像,或者他们经常被一起购买;推荐系统将会计算物品与物品之间的相似或关联程度,当你看了某个商品的时候,他将会把最相似/最相关的那几个商品推荐给你。
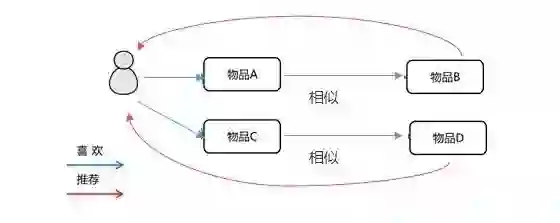
基于模型(这个比较抽象):利用数学建模的手段,评估你的购买意图,将模型计算出来的得分最高的推荐给你。
基于内容:在茫茫商品中,总有一些商品他们的属性、描述很像;当你看了某些商品后,推荐系统会将内容上最相似的那些商品推荐给你。
其他:基于统计/知识等 目前主流推荐系统都是以上各个策略的混合。
什么样的产品推荐效果明显
稀疏性,多样性,时效性的平衡,目前推荐更多地还是锦上添花,没有一定量的数据,效果将大打折扣。
稀疏性:稳定的流量与稳定的交互比例(PV/UV)
稳定的流量与稳定的交互比例保证了数据的稠密性,单用户和单商品有足够的数据可以完成机器学习,并且保证一定的置信度。
当有新用户(新商品)加入系统时,由于系统中缺乏用户(商品)历史反馈信息,所以完全无法推断用户的偏好,也就无法做出预测。
时效性:能够获得快速反馈
用户行为数据越快被反馈的产品推荐效果更明显:因为用户的兴趣是变化的,通过机器学习来推敲用户的兴趣所需的物料就是数据,如果你能够快速地反馈用户行为数据,那算法模型就能够实时地捕捉用户变化着地兴趣,当然效果就自然而然明显。
多样性:条目的类别多样
多样的类别可以从不同的角度满足用户,商品量越大,类目越多,推荐的价值就越大。
多样性与稀疏性:条目增长相对稳定
如果产品本身条目增长不稳定,那么大量新条目地涌入会使冷启动非常明显,而条目增长过缓会导致多样性问题,推荐无法很好地从有限的池子中挑选适合用户的条目。
未来电商不能只做成交
围绕商品更新,商品质量,商品与买家的匹配程度,推荐应该从以下四点出发来优化:
提升买家用户的体验,提高选购决策质量与效率实现优质买家的差异化服务。
提高商品的有效曝光机会与转化率,提升卖家用户的效果与效益。
利益均衡机制,均衡曝光机会,提升曝光商品及商家的覆盖率。
提升买家留存率与卖家续签率,提升买卖家的忠诚度,提升商品点击机率。
浏览与成交之间存在着巨大鸿沟,未来推荐将帮助平台挖掘消费的深度,在各个特定场景下提升推荐转换。
拓宽消费的广度,提升推荐对物料的覆盖,提升对用户的覆盖,各个场景的扩充,做到浅层消费到深层消费再到扩展消费。
围绕着商品与人的连接以及相应的商业诉求,让连接匹配的质量更高,连接的广度更宽,同时通过机制设计促进整个商业和生态的健康发展,成为整个新商业发展的引擎驱动。
作者:姚凯飞
简介:Club Factory 推荐算法负责人。硕士毕业于上海交通大学,前阿里推荐算法工程师,多年电商及视频推荐经验,目前在出海电商 Club Factory 负责推荐算法工作。
编辑:陶家龙、孙淑娟
出处:转载自微信公众号DataFunTalk(ID:datafuntalk)

精彩文章推荐: