全面挑战x86!Arm公布最强服务器内核及首款ArmV9平台

新智元报道
新智元报道
来源:VB
编辑:LQ
【新智元导读】去年9月,Arm公布了两大服务器芯片平台Neoverse V1和N2,但并没有公开性能情况,那么到底性能如何,是否能全面挑战x86?刚刚,Arm揭晓了答案。
Arm公布了Neoverse V1和N2服务器芯片平台的「性能数据」,处理能力比上一代增强了40% -50% .

数据中心工作负载和互联网流量的需求呈指数级增长,这就需要新的方案——要满足这些需求,同时还要减少当前和预期的耗电量增长。
但Arm表示,目前运行的各种工作负载和应用程序意味着,「一刀切」的计算方法不是最终解决办法。这是对使用x86架构的「英特尔」和「AMD」嘲讽。
Neoverse V1:性能提升50%
Neoverse V1:性能提升50%
50%的性能提升,1.8倍的矢量工作负载范围的提升,比N1高出4倍的机器学习工作负载。
这就是Neoverse V1的性能表现。
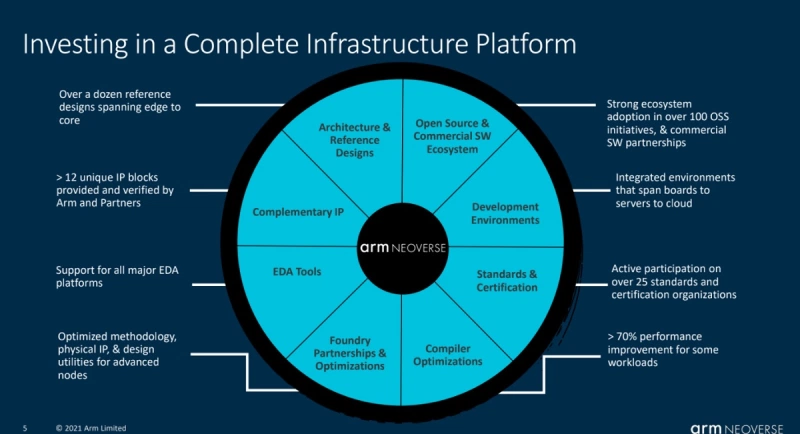
V1是Arm新的性能优先计算层中的第一个。V1为芯片给了合作伙伴更多灵活性为更依赖于 CPU 性能和带宽的应用程序构建计算,同时也给了SoC设计灵活性。
Arm奔着「性能第一」的设计理念设计V1,想要建立一个有史以来「最广泛」的微架构,容纳更多的飞行指令支持高性能和百万兆等级运算。
Arm表示,这种宽而深的架构ーー加上可伸缩矢量扩展(SVE)ーー使V1在单核性能和代码寿命方面处于领先地位,并为SoC设计者提供实施的灵活性。
这是HPC计算的发展方向,可以参考SiPearl和ETRI的HPC SoCs.
Neoverse N2:首款Arm V9微架构
Neoverse N2:首款Arm V9微架构
第二代的N系列平台Neoverse N2的目标是覆盖从云到边缘计算的所有设备。
几周前,Arm刚推出了Armv9架构,以满足各个领域对于专用处理器的需求。Neoverse N2平台也是「第一个」基于Armv9架构的平台的芯片,在安全性、能效和性能方面都有改进。
与N1相比,Neoverse N2提供了40%的单线程性能,仍然保持与Neoverse N1相同的功率和单位面积效率。除此之外,Neoverse N2的也拥有更好的扩展性。
Neoverse N2平台单线程性能和工作效率方面均具有行业领先的性能,从而降低了用户的总体拥有成本。Neoverse N2是第一个具有SVE2功能的平台,该功能是Armv9功能,可显着提升云到边缘的性能。
对于机器学习、数字信号处理、多媒体和5G系统等领域来说,SVE2有更好的性能,也更易于编程,以及还继承了SVE的可移植性优势。
Arm也玩凡尔赛?
Arm也玩凡尔赛?
分析人士指出,V1对于高性能计算机来说也是一个强劲的开端;而通过N2,人们还会发现「单线程设计」的性能也能如此高。
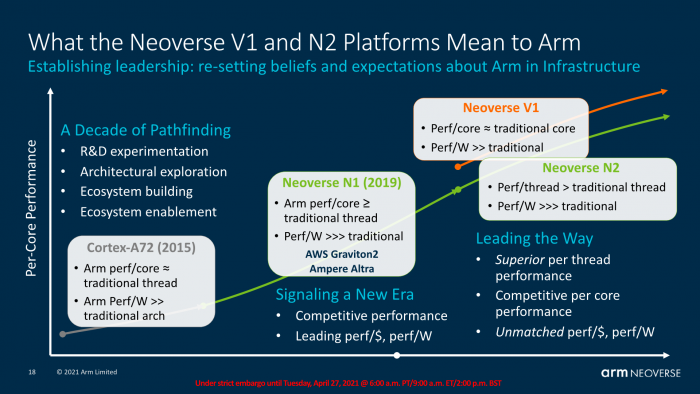
总之,Arm正在努力提升其在计算市场的竞争力。
Arm基础设施业务高级VP Chris Bergey介绍,Arm自10年前就开始研发具有竞争力的服务器芯片,基于此种设计的芯片或将于今年年底或明年年初上市。
Arm表示,Neoverse CMN-700是业内最先进的网状互连系统,可以释放 Neoverse V1和 N2平台的性能和功率效益。它是制造高性能V1和N2芯片的关键元件,并支持更高的核心计数和缓存内存。
随着「摩尔定律」的终结,方案供应商正在寻求专业化的处理方法。自Neoverse系列平台发布以来,启用专业化处理一直是一个焦点,Arm预计这些功能更新将加速这一趋势。
去年9月,Arm公布了V1和N2,但是没有公布性能,这次则公布了效能功耗比,所有权的总成本收益,以及采用这些设计的合作伙伴。
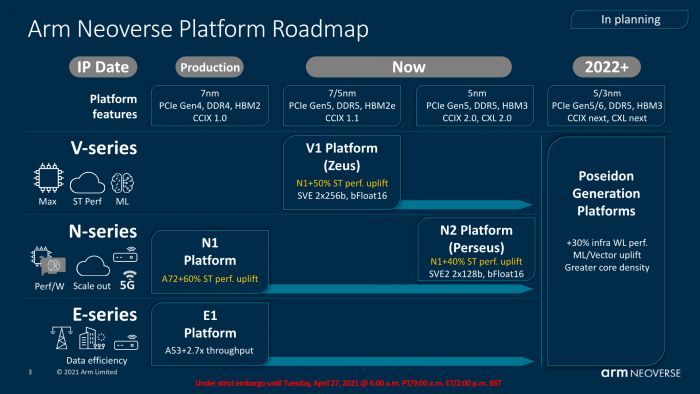
Arm列举了一些客户的测试数据:
美国芯片制造商Marvell透露,其基于N2的Octeon系列网络解决方案将在2021年底开始抽样筛检,性能比上一代Octeon芯片高3倍。
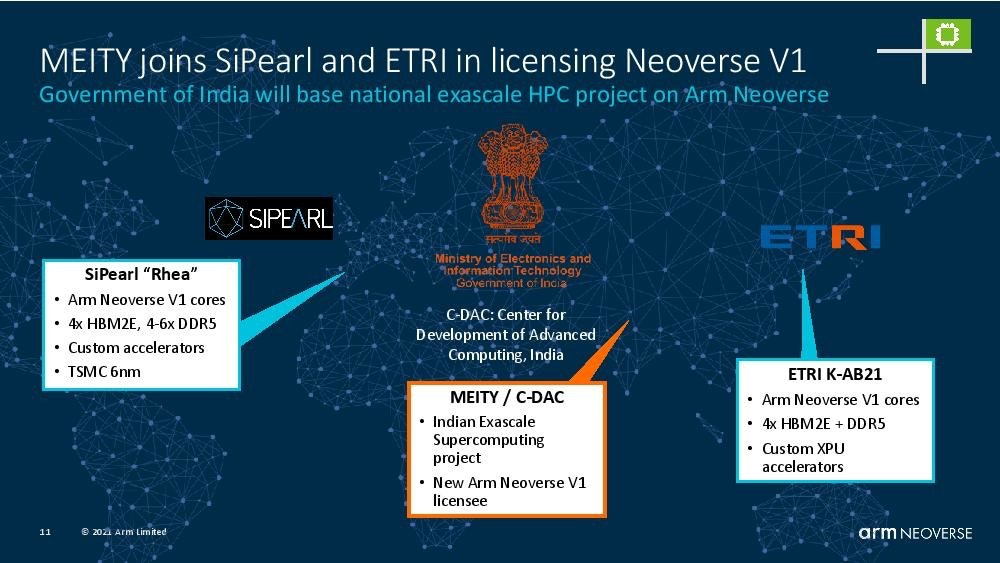
印度电子和信息技术部(MeitY)宣布,将与 SiPearl 和 ETRI 一起为V1的国家级高性能计算项目颁发许可证。
甲骨文计划在Oracle云基础设施中采用Ampere Altra CPU,作为各种工作负载的价格/性能领先者。
基于Arm的亚马逊AWS Graviton2继续以稳定的增长和区域扩张迅速扩大其 EC2的覆盖范围。
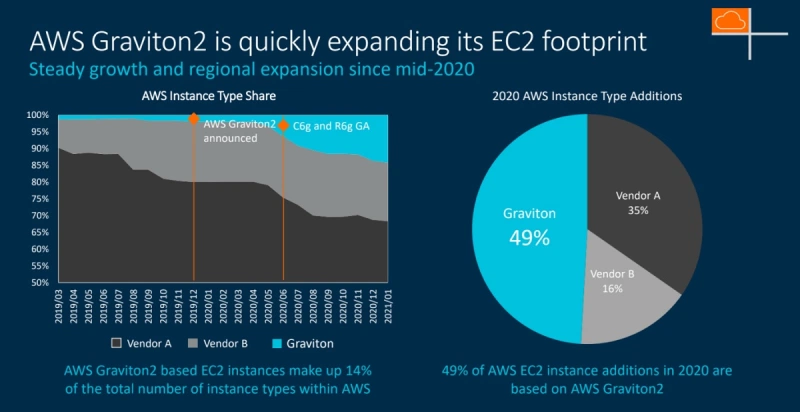
阿里云刚刚测试了即将推出的阿里云 ECS Arm 实例,展示出DragonWell JDK 性能提高了50%.
腾讯正在硬件测试和软件支持方面进行投资,这将使其能够在云应用中采用Neoverse技术。Arm高级VP Bergey表示,测试结果表明Arm的设计具有很高的效能功耗比。
此外,还有英伟达的Grace,但现在还有很多「未解之谜」——Grace所采用的Arm处理器没有公布,Arm也没有透露Grace是否应用了Neoverse设计。
Arm高级VP Bergey表示,这些客户的「背书」只是「冰山一角」,不应该让创新者在性能和效率之间「二选一」。

Arm助你「二者兼得」。
不得不说,Arm也是凡尔赛的高手。
除了多家客户「背书」,分析人士也很看好V1和N2的表现。
Linley集团首席分析师Linley Gwennap也表示,第三方数据很能说明问题,他说:
AMD已经超过N1:「AMD 最新的 Epyc 处理器在几乎所有测试中都优于最快的 Neoverse N1芯片,优势很大,尽管 Arm 芯片拥有更多的内核,即使对 TDP 进行了调整,这两种芯片的效能功耗比也大致相同。Arm所谓的的优势在于合成的基准,这种基准最好能够跨越64个或更多的内核,这并不能代表 Phoronix 测量的真实工作量。我估计AMD Zen 3在单线程应用程序上领先N1 60% .」
「如果你根据Arm的数据进行N1比较和项目,在单线程(扩展)工作负载方面,N2仍然比 Zen 3落后20% 。根据 Arm 的说法,N2的功率比它的性能提高得多,因此 N2的功率效率实际上更低(V1的功率效率更低)。因此,如果 AMD 在效能功耗比上与N1匹配,N2也不会让 Arm 在这个指标上领先。总之,在 Arm 在单线程性能方面达到同一水平之前,它将仅限于扩展工作负载。而且,除非它能证明自己在实际应用中的效能功耗比优势,否则它的主要卖点就是更低的价格。」
参考资料:
https://venturebeat.com/2021/04/27/arms-neoverse-server-chips-generate-at-least-40-better-performance/

AI家,新天地。西山新绿,新智元在等你!
【新智元高薪诚聘】主笔、高级编辑、商务总监、运营经理、实习生等岗位,欢迎投递简历至wangxin@aiera.com.cn (或微信: 13520015375)
办公地址:北京海淀中关村软件园3号楼1100





