学界 | 强化学习机器人也有很强环境适应能力,伯克利AI室验室赋能元训练+在线自适应

AI 科技评论按:在现实生活中,人类可以轻易地适应环境的变化,但机器人在适应力方面却表现得一般,要如何让机器人像人一样能够快速适应现实世界呢?加州大学伯克利分校人工智能实验室 BAIR 近期介绍了自己研究具有很高的环境适应能力的机器人的最新成果,雷锋网全文编译如下。

图一【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】
人类能够无缝地适应环境的变化:成年人能够在几秒内学会拄拐走路;人们几乎在瞬间可以捡起意料之外的重物体;不用重新学走路,儿童也能够让自己的步法快速适应从平地到上坡的转变。这种适应力在现实世界中起着很重要的作用。
另一方面,机器人通常被部署了固定行为(无论编码还是学习),这让它们在特定的环境中做的很好,但也导致了它们在其他方面做不好:系统故障、遇到陌生地带或是碰上环境改变(比如风)、需要处理有效载荷或是其他意料之外的变化。BAIR 最新研究的想法是,在目前阶段,预测和观察之间的不匹配应该告诉机器人,让它去更新它的模型,去更精确地描述现状。举个例子,当我们意识到我们的车在路上打滑时(如图二),这会告知我们,我们的行为出现了意料之外的不同影响,因此,这让我们相应地规划我们后续的行动。要让机器人能够更好地适应现实世界,就要让它们能够利用它们过去的经验,拥有快速地、灵活地适应的能力,这是重要的一点。为此,BAIR 开发了一个基于模型的快速自适应元强化学习算法。

图二【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】
快速适应
先前的工作使用的是试错适应方法(Cully et al., 2015)以及自由模型的元强化学习方法(Wang et al., 2016; Finn et al., 2017),通过一些训练,让智能体去适应。然而,BAIR 研究人员的工作是要让适应能力发挥到极致。人类的适应不需要在新设置下体验几回,这种适应是在线发生的,仅在几个时间步内(即毫秒),太快了以至于不能被注意到。
通过在基于模型学习设置中适应元学习(下文会讨论),BAIR研究人员实现了这种快速适应。用于更新模型的数据应该在基于模型中设置,而不是根据推算过程中获得的奖励而进行调整,根据近期经验,这些数据以模型预测错误的形式在每一个时间步长中发挥作用。这个基于模型的方法能够让机器人利用仅有的少量近期数据,有意图地更新模型。
方法概述
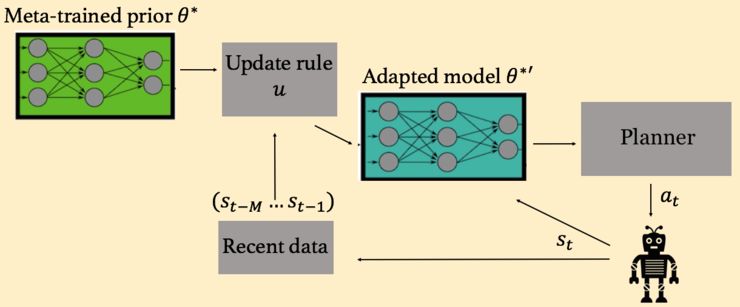
图三【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】
BAIR研究人员的方法遵循图三中的普适公式,利用对近期数据的观察去自适应模型,类似于自适应控制的总体框架(Sastry and Isidori, 1989; Åström and Wittenmark, 2013)。然而,真正的挑战是,当模型是复杂的、非线性的、高容量的函数近似者(如神经网络)时,模型该如何成功地自适应。为了进行有意义的学习,神经网络需要很多数据,因此,在模型权重上实行SGD是无效的。
因此,通过在(元)训练时间里明确地按照这个适应目标进行培训,能够在测试的时候快速自适应,如下节所述。在多种不同设置的数据中进行元训练,一旦得到了一个善于自适应的先验模型(权重用θ∗来表示)之后,这个机器人就能够在每个时间步内(图三)根据这个 θ∗来适应,把先验模型和当前的经验相结合,把它的模型调整到适合当前状况的样子,从而实现了快速在线自适应。
元训练:
给定任意时间步长t,我们处于st阶段,我们在at时刻采取措施,根据底层动力学函数st+1=f(st,at),我们最终将得到st+1的结果。对我们来说,真实的动态是未知的,所以我们反而想要拟合一些学习过的动力学模型s^t+1=fθ(st,at),通过观察表单(st,at,st+1)的数据点,做出尽可能好的预测。为了执行行为选择,策划者能够利用这个评估过的动态模型。
假定在首次展示过程中,任何细节和设置都能够在任何时间步长内发生改变,我们将把暂时接近的时间步看做能够告诉我们近况的“任务”细节:在任何空间状态下运行,持续的干扰,尝试新的目标/奖励,经历系统故障等等。因此,为了模型能够在规划上变成最有用的模型,BAIR研究人员想要利用近期观察到的数据进行首次更新。
在训练时间里(图四),这个总和是选择一个连续的(M+K)数据点的序列,使用第一个M来更新模型权重,从θ到 θ′,然后优化新的 θ′, 让它擅长为下一个K时间步预测状态转换。在利用过去K点的信息调整权重后,这个新表述的损失函数代表未来K点的预测误差。
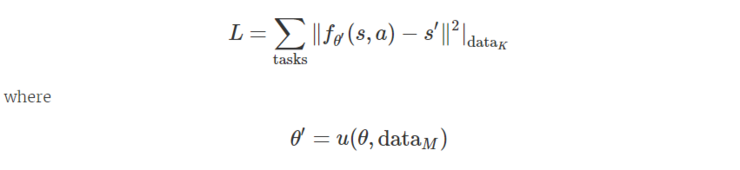
【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】
换句话说, θ不需要导致好的动态预测。相反,它需要能够使用具体任务的数据点,将自身快速适应到新的权重中去,依靠这个新的权重得到好的动态预测结果。有关此公式的更多直观信息,可参阅MAML blog post:
https://bair.berkeley.edu/blog/2017/07/18/learning-to-learn/
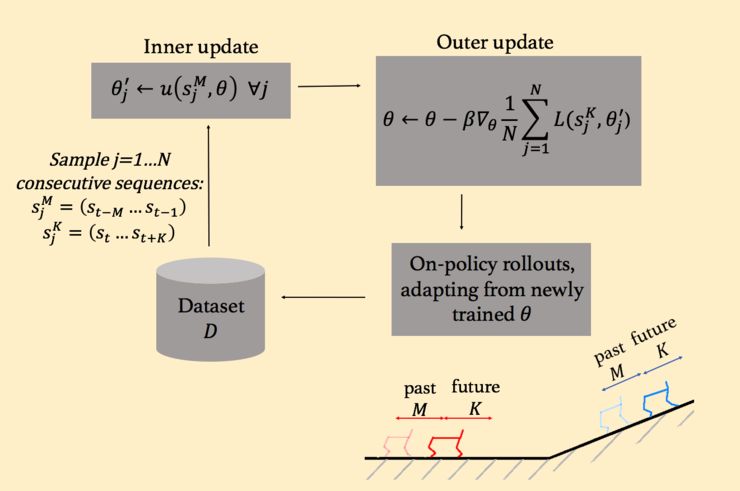
图四【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】
模拟实验
BAIR研究人员在模拟机器人系统上进行实验,测试他们的方法在环境中适应瞬间变化的能力,并且在训练环境之外,这种方法是否也能够泛化。值得注意的是,BAIR研究人员对所有智能体进行任务/环境分布的元训练(详见本文),但是研究人员在测试的时候评估了它们对未知的和不断变化的环境的适应能力。图五的猎豹机器人在不同随机浮力的漂浮板上训练,然后在一个水里具有不同浮力的漂浮板上进行测试。这种环境表明不仅需要适应,还需要快速/在线适应。图六通过一个有不同腿部残疾的蚂蚁机器人做实验,也表明了在线适应的必要性,但是在首次展示的时候,一条看不见的腿半途发生了故障。在下面的定性结果中,BAIR研究人员将基于梯度的适应学习者(‘GrBAL’)和标准的基于模型的学习者(‘MB’)进行比较,这个基于模型的学习者是在同样的训练任务变化但是没有明确的适应机制中进行训练的。
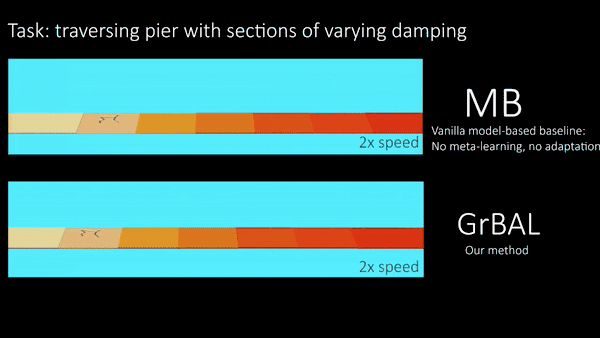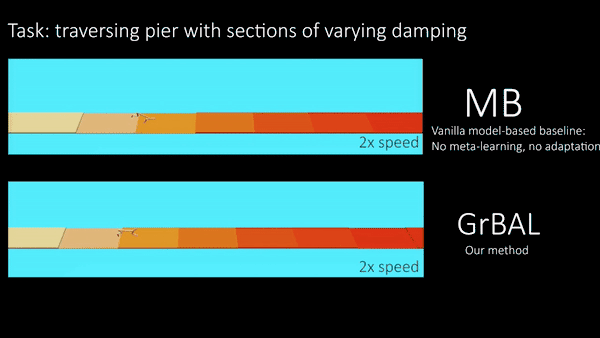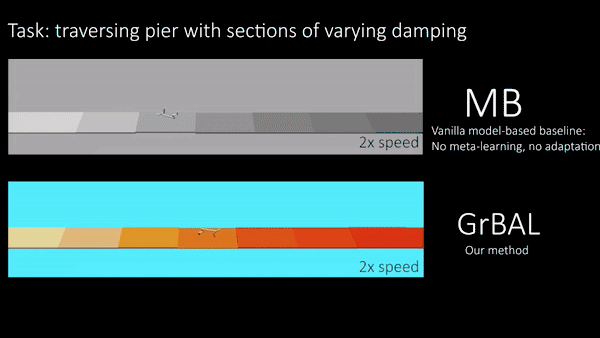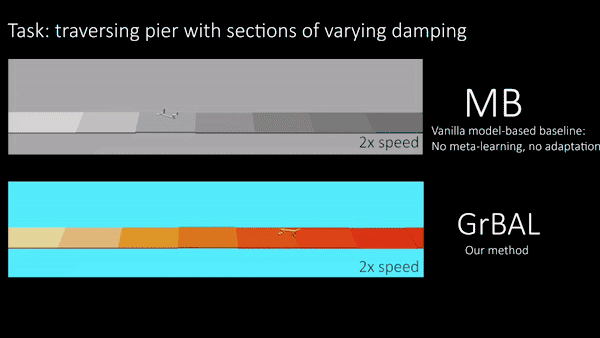
图五【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】

图六【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】
这个基于模型的元强化学习方法的快速适应能力让这个模拟机器人系统在表现和/或样本效率方面相比之前的最好的方法取得了显著的提升,以及在这同一个方法的对照实验中,有在线适应相比没有在线适应、有元训练相比没有元训练、有动态模型相比没有动态模型,都可以看到系统表现和/或样本效率的提升。这些定量比较的详情可参阅论文。
硬件实验

图七①【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】

图七②【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】
不仅要强调元强化学习方法的样本效率,而且还要强调在现实世界中快速在线适应的重要性,BAIR研究人员在一个真实的动态的有足微型机器人演示了这个方法(见图七)。这个小型的6足机器人以高度随机和动态运动的形式,展示了一个建模和控制的挑战。这个机器人是一个优秀的在线适应候选人,原因有很多:构造这个机器人使用了快速制造技术和许多定制设计步骤,这让它不可能每次都复制相同的动力学,它的连杆机构和其他身体部位会随着时间的推移而退化,并且,它移动的速度非常快,并且会随着地形的变化而进行动态改变。
BAIR的研究人员们在多种不同的地形上元训练了这个步行机器人,然后他们测试了这个智能体在线适应新任务(在运行的时候)的学习的能力,包括少了一条腿走直线任务、从未见过的湿滑地形和斜坡、位姿估计中带有校正错误或误差,以及首次让它牵引载荷。在硬件实验中,BAIR的研究人员们把他们的方法和两个方法做了比较,1,标准的基于模型学习(‘MB’)的方法,这个方法既没有自适应也没有元学习;2,一个带有适应能够力的动态评估模型(‘MB’+“DE”),但它的适应能力是来自非元学习得到的先验。结果(图8-10)表明,不仅需要适应力,而且需要从显式的元学习得到的先验进行适应。

图八【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】

图九【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】

图十【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】
通过有效地在线适应,在少了一条腿走直线的实验中,BAIR的方法阻止了漂移,阻止了滑下斜坡,解释了位姿错误校准,以及调整到牵引有效载荷。值得注意的是,这些任务/环境和在元训练阶段学习的运动行为有足够的共性,从先前的知识(不是从零开始学习)中提取信息是有用的,但是他们的差异很大,需要有效的在线适应才能成功。
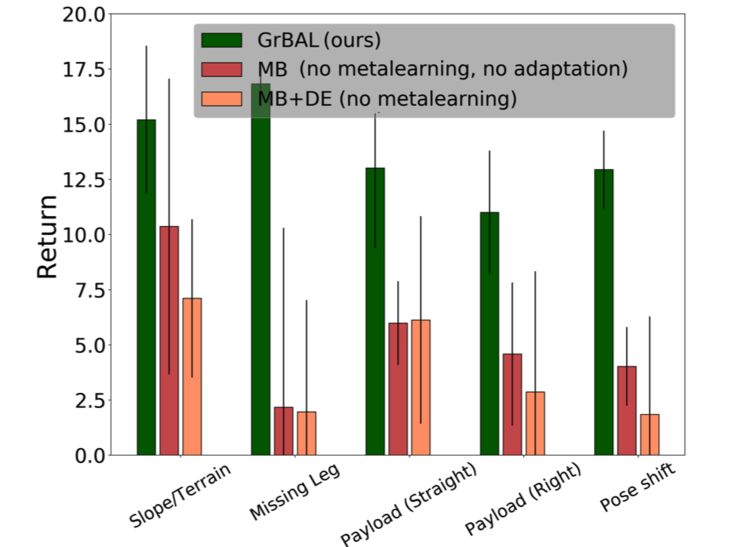
图十一【 图片来源:BERKELEY BAIR 所有者:BERKELEY BAIR 】
未来方向
通过使用元学习,这项工作能够让高容量神经网络动态模型在线适应。从以前的元学习开始,通过让模型的局部微调,BAIR研究人员排除了对精确全球模型的需求,而且能够快速适应到新情景中,例如意料之外的环境变化。尽管BAIR研究人员展现了模拟和硬件在不同任务中的适应结果,但是,仍存在许多相关的改进途径。
首先,虽然这种设置很强大,它总是从提前训练的先验中进行微调,但这个方法有一个限制,就是即使看了几遍这个新的设置,也会得到像第一次看到的同样的表现。在后续工作中,BAIR研究人员将采取措施,精确地解决这个随时间而变得严重的问题,同时不要也因为试验了新技能而忘记旧技能。
另一个提高的领域包含了制定条件或分析性能,以及适应的限制:鉴于前面所包含的知识,什么是能够适应的?什么是不能够适应的?举个例子,两个人正在学骑自行车,谁会突然在路面滑行呢?假定这两个人之前都没骑过自行车,因此他们也不可能从自行车上摔下来过。在这个实验中,第一个人A可能会摔倒,手腕受伤,然后需要进行几个月的物理治疗。相反,另一个人B可能借鉴与他先前学过的武术知识,从而执行了一个良好的“跌倒”程序(也就是说,摔倒的时候翻滚背部来缓冲而不是尝试用手腕来减弱下降的力量)。这就是一个实例,当这两个人都在尝试执行一项新任务的时候,那些他们先前知识中的其他经验会显著地影响他们适应尝试的结果。因此,在现有的知识下,有某种机制来理解适应的局限性,应该会很有趣。
原论文地址:https://arxiv.org/abs/1803.11347(已被 ICLR 2019 接收)
项目主页:
https://sites.google.com/berkeley.edu/metaadaptivecontrol
代码开源地址:
https://github.com/iclavera/learning_to_adapt
via:https://bair.berkeley.edu/blog/2019/05/06/robot-adapt/
2019 全球人工智能与机器人峰会
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

点击阅读原文,查看伯克利 AI 研究院其他相关报道



