深度压缩网络 | 较大程度减少了网络参数存储问题
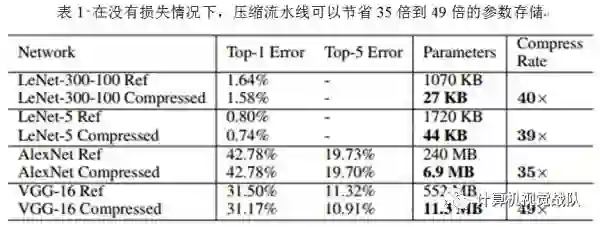
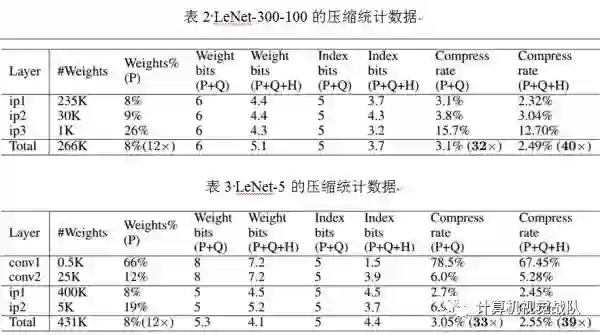
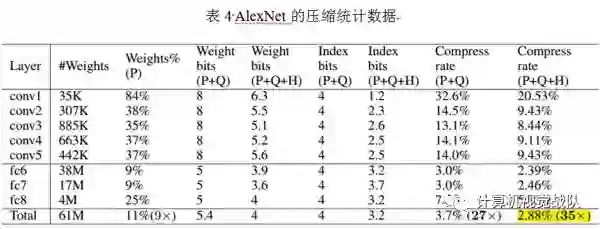
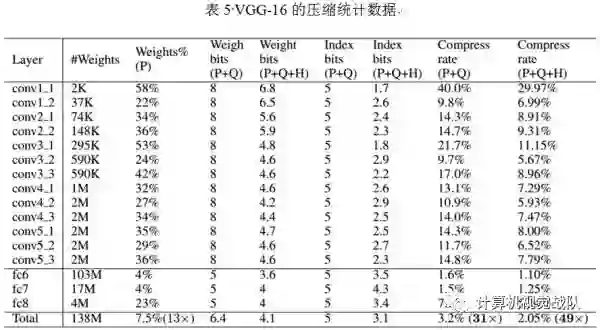
神经网络是计算密集型和内存密集型,很难使它们用有限的硬件资源去部署在嵌入式系统中。为了解决这种限制,本文引入“深度压缩”,一共有三个阶段的流水线:剪枝、量化和霍夫编码,它们一起工作去减少神经网络的存储问题,并在没有影响精确度的情况下压缩了35倍到49倍。最后在ImageNet数据集上的实验结果,将AlexNet压缩了35倍(从240MB压缩到6.9MB)并没有精确度损失;将VGG-16压缩了49倍(从552MB压缩到11.3MB),也没有精确度损失。
训练主要步骤:
剪枝神经网络,只学习重要的连接;
量化权值去使权值共享;
应用霍夫编码继续压缩。
主要框架
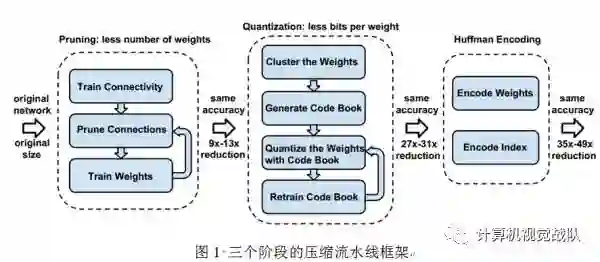
一、网络剪枝
网络剪枝已经被广泛研究于压缩CNN模型。在早期工作中,网络剪枝已经被证明可以有效地降低网络的复杂度和过拟合。如图1所示,一开始通过正常的网络训练学习连接;然后剪枝小权重的连接(即所有权值连接低于一个阈值就从网络里移除);最后再训练最后剩下权值的网络为了保持稀疏连接。剪枝减少了AlexNet和VGG-16模型的参数分别为9倍和13倍。
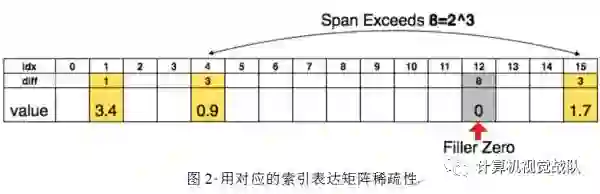
为了进一步压缩,本文存储不同索引而不是绝对的位置,然后进行编码,8 bits用于卷基层,5 bits用于全连接层。当需要的不同索引超过所需的范围,就用补零的方案解决,如图2中,索引出现8,用一个零填补。
二、Trained quantization and weight sharing
网络量化和权值共享会进一步压缩剪枝的网络,通过减少所需的bits数量去表示每一个权值。本文限制有效权值的数量,其中多个连接共享一个相同权值,并去存储,然后微调这些共享的权值。
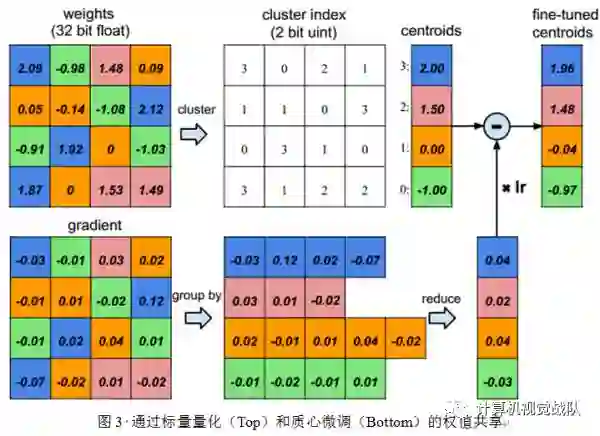
假设有4个输入神经元和4个输出神经元,权值就是一个矩阵。在图3的左上角是一个权值矩阵,在左下角是一个梯度矩阵。权值被量化到4 bits(用4种颜色表示),所有的权值在相同的通道共享着相同的值,因此对于每一个权值,只需要保存一个小的索引到一个共享权值表中。在更新过程中,所有的梯度被分组,相同的颜色求和,再与学习率相乘,最后迭代的时候用共享的质心减去该值。
为了计算压缩率,给出个簇,本文只需要 bits去编码索引,通常对于一个神经网络有个连接且每个连接用 bits表达,限制连接只是用个连接共享权值将会导致一个压缩率:
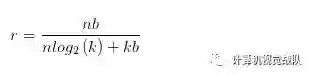
例如在图3中,有一个的初始权值,但只有4个共享权值。原始的需要存储16个权值,每个需要32bits,现在只需要存储4个有效权值(蓝色,绿色,红色和橙色),每个有32bits,一共有16个2-bits索引,得到的压缩率为16*32/(4*32+2*16)=3.2。
权值共享
一个神经网络的每一层,本文使用K-Means聚类去确定共享权值,权值不跨层共享。分配个原始权值到个簇,,所以去最小化簇类离差平方和(WCSS):
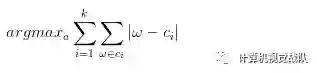
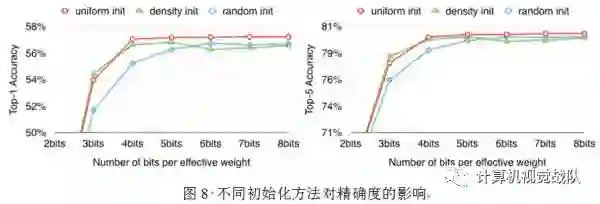
共享的权值初始化
质心初始化影响聚类的质量,因而会影响网络的预测精确度。本文实验了三种初始化方法:Forgy(random),density-based和linear初始化。
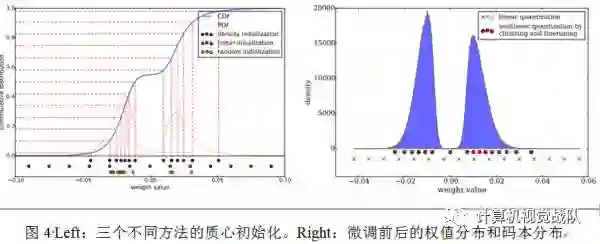
较大的权值比较小的权值有着更重要的角色,但是较大的权值很少。因此,Forgy和density-based初始化很少有大的绝对值,这就导致较少的权值被微弱表达。但是Linear初始化没有遇到这个问题,实验部分比较了准确性,发现Linear初始化效果最好。
三、霍夫曼编码
霍夫曼编码是一个最优的前缀码,通常被用于无损失数据压缩。它用可变长码字去编码源符号。通过每个符号的发生概率驱动,更常见的符号用较少的bits表达。
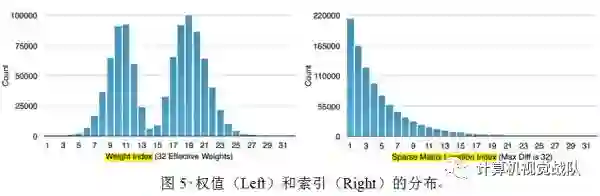
四、实验
实验一共用了四个网络:2个在MNIST数据集,另2个在ImageNet数据集。该训练用Caffe框架运行,训练时,霍夫曼编码不需要训练,在所有微调结束后实现线下操作。
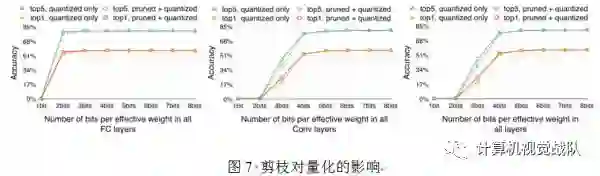

五、总结
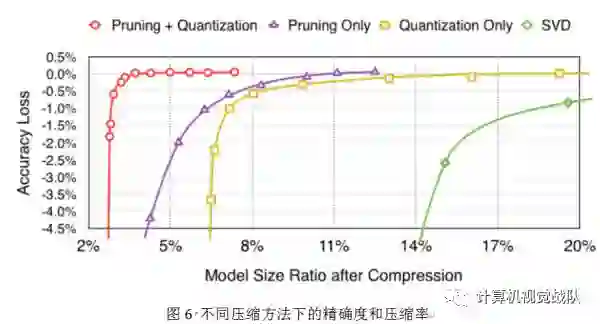
本文提出了“深度压缩”,在没有影响精确度的情况下进行神经网络的压缩。本文的方法使用了剪枝、量化网络权值共享和应用霍夫曼编码操作。本文强调了实验在AlexNet上,没有精确度损失的情况下减少了参数存储,压缩了35倍。相同的结果在VGG-16和LeNET网络中,分别压缩了49倍和39倍。这种结果就会导致更小的存储要求并应用到手机APP中。本文的压缩方法有助于复杂的神经网络应用在移动程序中,解决了应用程序的大小和下载带宽限制。



