网络数据隐私保护,阿里工程师怎么做?

阿里妹导读:基于海量个人数据的挖掘和分析,在带来巨大价值的同时,也让个人隐私岌岌可危。比如,在移除数据中标识符属性(身份证号码,手机号码,姓名等)的情况下,简单地分析其他属性组成的准标识符,仍能够轻易地识别个人,个人信息存在巨大的暴露风险。如何更好保护网络数据隐私?一起来看看阿里技术团队的探索。
个人数据挖掘和个人隐私保护,并非鱼与熊掌,可视分析的技术手段能够帮助我们保护个人隐私数据,避免后续的数据挖掘暴露隐私的同时,平衡数据质量发生的变化,减少对后续数据挖掘的影响。针对网络数据中的隐私保护问题,浙江大学、加州大学戴维斯分校和阿里云DataV团队,共同发表了最新的研究成果《GraphProtector: a Visual Interface for Employing andAssessing Multiple Privacy Preserving Graph Algorithms》【1】,这项成果也已论文形式收录在IEEE TVCG中。
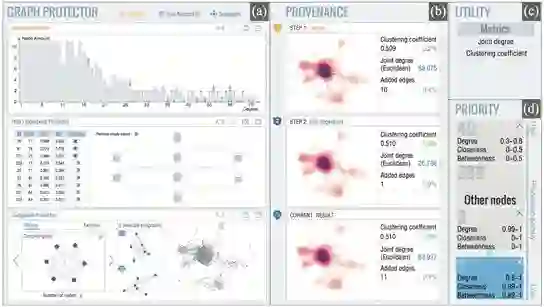
图一 GraphProtector 系统。 a) 保护器视图 b) 历史记录视图 c) 实用性视图 d) 优先级视图
背景
关系描述了人与人之间的互相联系,它可以是一种静态的连接,如“亲属”、“朋友”等,也可以是动态的,通过动作将其关联,例如“通话”、“邮件”等。科技的进步使得人与人之间的联系更为密切,关系变得更复杂,进而形成了一张偌大的网,因此,我们也把这类数据称之为网络数据(或图数据)。网络数据的研究被广泛应用于各个领域,它能够帮助识别社团、划分人群,定位特殊人物、研究信息传播、追踪欺诈行为等。但在对这类数据进行研究的同时,伴随着巨大的隐私泄露风险。为了能够在探索数据背后巨大价值的同时,保护用户的隐私不被泄露,我们提出了一个能够应对网络数据隐私攻击,提供有效隐私保护的可视分析系统——GraphProtector,它不仅能够更全面、更细致地保护用户隐私,同时也能够兼顾数据的实用性,保证数据的质量。
隐私保护方法和流程
针对网络数据的隐私保护相较于一般数据而言,更为困难,原因主要有以下两点:
1) 网络数据自身结构特征繁多,例如,度数分布,最短路径分布,接近中心性分布等,任意的结构特征都有可能成为攻击者的攻击入口,可谓是防不胜防;
2) 网络数据中节点和边都携带了大量的数据,这些数据无疑给了攻击者更多的机会去识别用户现实世界中的身份。
因此,想要完全解决图数据中的隐私问题,将会是一个非常复杂和困难的工作。在当前阶段,我们将研究的重点放在了网络数据的结构特征上,通过修改图的结构特征保护用户的身份不被泄露。其中,之所以选择结构特征作为着手点,最重要的原因是结构特征是网络数据的基础属性,解决结构特征暴露的隐私风险是是解决隐私暴露的必经之路。在这次的研究中,我们先以以下三种结构特征作为示例:
度数:节点度数是和它关联的边的总数(如图二中,图c表格中Degree展示了原始图图a的度数分布);
中心指纹:是指在最长路径`i`的限制下,图中普通节点和中心节点们之间的最短路径所形成的向量。这里为了简化复杂度,我们取`i`设为了`1`,即普通节点和中心节点们是否存在相邻关系作为节点的中心指纹(如图二中,图c中HubFingerprint为选取了原始图图a中4号节点和7号节点作为中心的的中心指纹分布);
子图:指节点集和边集分别是某一图的节点集的子集和边集的子集的图(如图二中,图b为原始图图a的子图);

图二结构特征举例。 a) 原始数据 b) 子图 c) 度数分布和中心指纹分布
前人的研究提供了多种隐私匿名保护思路,如k-匿名、聚类和查分隐私等等,我们在研究中选取了k-匿名模型作为我们保护的基本方法。k-匿名模型是最经典的语义匿名模型之一,在隐私保护领域得到了广泛的应用,在这个模型中,它通过准标识符将数据分成若干个等价类(例如度数相同的节点形成了一个度数等价类,中心指纹相同的节点形成了一个中心指纹等价类,结构相同的子图形成了一个子图等价类),并要求每个等价类中至少存在k个数据记录(例如当k为2时,k-匿名模型要求每一个度数等价类中至少存在2个节点),对于这k个数据记录中的任意一条,被识别出的概率为1/k,从而使得攻击者无法确定他们的攻击目标。
通过前人的研究分析我们得知,没有任何一种隐私保护方法能够抵抗所有的攻击,k-匿名模型是众多方法中最为强大的一种,它在一定条件下可以抵抗大部分的隐私攻击,并且对于数据质量伤害的程度较小,使得经过隐私匿名保护后的数据仍然能够应用于后面的分析和研究中。
在k-匿名模型的基础上,为了尽可能地减少对数据质量的损害,我们采取了保持节点个数不变,仅增加或减少边的策略。同时,在目前我们的研究中,为了减少保护方法之间的冲突以及降低计算的复杂度,我们首先将研究的重点放在了增加边的策略上。
上文中多次提到了“数据质量”,保证数据质量是我们隐私保护过程中的一个重要目标(试想,如果不考虑数据质量,我们完全可以同化所有的用户数据,这样一来攻击者将无法定位到攻击目标,但这样的数据却失去了研究意义)。在使用k-匿名模型增加边的方法来保护数据隐私时,有两种处理策略:
1)为当前等价类中的元素增加适当的边,使得这些元素全部转移到其他等价类中,使得当前等价类不存在,也就不会存在隐私暴露风险;
2)为其他等价类中元素增加适当的边,使其中的元素转移到当前等价类中,从而使当前等价类满足k-匿名模型的要求。基于保护数据质量的目的,对于这两种策略,我们将计算它们的代价,及增加边的数量,采取代价较小的的方法执行。我们设计了详细的算法来实现这一目标。另一方面,对于数据质量的变化,系统提供若干的实用性指标,如度数、最短路径等,我们将在数据处理中以及数据处理后呈现这些指标的变化,帮助使用者进行决策,从而能够采取“最优”的解决方案。
下图展现了采用`GraphProtector`进行网络数据隐私保护的流程:
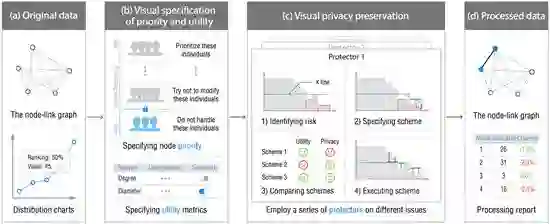
图三 GraphProtector 的隐私保护流程。 a) 数据导入 b) 优先级制定及实用性指标选取 c) 隐私保护处理 d) 数据导出
数据导入:首先,导入待保护的网络数据,系统将使用节点连接图的形式呈现原始数据。此外,系统还提供一些原始数据的结构特征分布供使用者观察和探索。
优先级制定及评估指标选取:在这个阶段,通过观察原始数据的结构特征分布,使用者对节点的优先级进行排序,优先级排序决定了节点的处理顺序,排序较高的节点将会被优先处理。此外,使用者在优先级排序时可以锁定一些节点,被锁定的节点(一般为比较重要的节点,如核心人物等)将不会参与到处理过程中,因此在隐私保护处理前后,它的关联关系将不发生改变。在这个阶段,使用者还需要选择关注的实用性指标,在数据处理前后,系统将呈现这些指标的变化,使用者可以通过它们来评估数据质量的变化。
隐私保护处理:经过以上步骤,我们进入了隐私保护的核心步骤,系统在这个阶段提供多个保护器(Protector)用来进行隐私保护处理。每一个保护器仅针对一种结构特征,使用者可以按照自己的需求选择多个保护器进行组合,从而实现更为全面和细致的保护。
这些保护器的使用方法将统一遵循图三种c图所示的流程,首先,根据用户自定义的k值,保护器会去识别数据中风险,并将风险通过一定的视觉编码呈现给使用者。然后,使用者可以制定一个或多个保护方案(即保护目标),对于每一个制定的方案,使用者都可以查看处理前后数据实用性指标的变化。接着,使用者对比不同方案的处理结果,观察是否达到了隐私保护的目的,以及数据质量变化是否在可接受的范围之内,最终选择“最优”的方案进行执行。
导出数据:最后,当数据处理到满意的程度时,使用者可以选择导出经过处理的的数据和数据的节点链接图,以及指标变化情况。
系统设计
下面将向大家详细介绍GraphProtector 系统的可视化及交互设计。系统主要围绕两个界面进行(图一和图四):
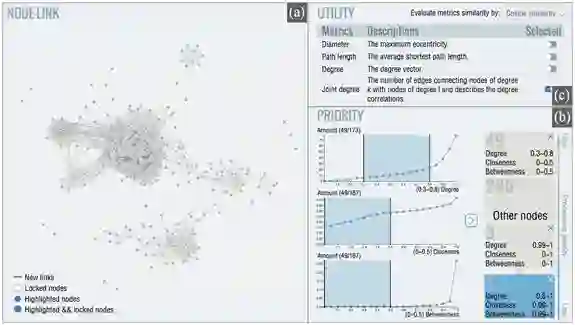
图四 GraphProtector 系统主要初始界面。 a) 节点链接图视图 b) 优先级视图 c) 实用性视图
图四展示了数据导入(图四a)和优先级制定(图四b)及评估指标选取(图四c)阶段的视图:
节点链接图视图(图四a):主要通过节点链接图以及力引导布局形式展现了原始数据的分布,在数据处理过程中,用户可以调出该视图查看数据变化。
优先级视图(图四b):使用者可以通过结构特征优先级的分布,在坐标轴上选取节点属性的范围,从而制定节点的优先级。视图右侧的每一个区块都代表了一个节点集合,其中罗列了该集合中节点的属性以及该集合中节点的个数,使用者通过拖拽交互来调整集合的优先级顺序,以及选择是否锁定某些集合的节点。
实用性视图(图四c):使用者通过这个视图,选取所关注的数据质量评估指标,这些指标的变化将会在处理前后呈现出来。
图一为隐私保护处理(图一a,b)和数据导出阶段的视图:
保护器视图(图a):主要用于风险定义,风险识别,风险处理和数据评估。这些保护器具有统一的处理流程(如下图五所示),分别通过保护器中的以下控件完成:

图五保护器主要控件。 a) k值输入框 b) “半运行”按钮 c) “记录”按钮 d) “方案相册”按钮
全局k值输入框:快速设定保护器内的k值;
“半运行”按钮:模拟执行制定方案的运行结果,并记录数据变化;
“记录”按钮:记录一个方案,方便后续对比不同方案的执行效果;
“方案相册”按钮:展现所有被记录的方案以及这些方案被执行后的实用性指标变化,方便使用者进行比较,从而选取“最优”方案执行;
目前系统设计了三种保护器,分别为度数保护器,中心指纹保护器和子图保护器。
度数保护器
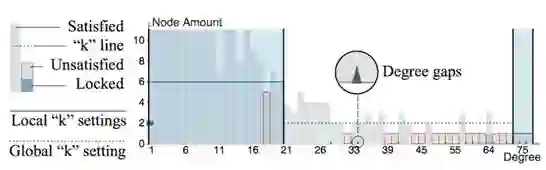
我们采用柱状图可视化了数据中的节点度数分布,横轴编码度数,按照从小到大的顺序排列,此外,在横轴上,我们还设计了一个“度数跳跃”符来编码度数分布之间的跳跃情况。纵轴编码该度数等价类中的节点个数,蓝色和灰色矩形分别编码锁定和未锁定的节点个数。
为了减少用户的认知和交互负担,我们设定了纵轴上的最高值,这个值是我们认为的安全值,即当度数等价类中的节点个数超过这个值时,这个等价类一般是安全的,所以当节点度数高于这个值时,我们可以暂且忽略其具体值,而将重点放在那些不满足k值的节点上。系统用虚线来编码整体k值(在系统中,我们称之为k线),辅助用户判断k值和节点个数的关系,从而定位风险所在。使用者除了可以通过滑动坐标轴上滑块来调整当前保护器内的整体k值外,还可以通过刷选度数范围,调整范围内的局部k值(系统中用实线编码),制定更加细致的隐私保护方案。
中心指纹保护器
中心指纹保护器分为两个部分,左侧为中心节点选取面板,右侧为中心指纹树。中心节点选取面板呈现了所有节点的结构信息,用户通过这个面板,选取重要的节点作为中心节点。右侧中心指纹树将根据用户的选择进行实时响应,树上每个节点代表了一个中心指纹等价类,即这个等价类中的节点具有相同的中心指纹,树中深度为i+1的等价类节点表示与i个中心节点相邻,所以若n为中心节点的个数,那么树的高度为n+1。
中心指纹树上的每一个节点编码与度数等价中的编码保持一致,虚线表示当前保护器设定的整体k值,蓝色和灰色举行分别编码锁定和未锁定的节点个数,右侧从上到下排列的i个矩形分别代表i个中心节点,顺序和左侧中心节点选取面板中中心节点的顺序保持一致,只有与当前节点等价类关联的中心节点所代表的矩形将才会被绘制出来,通过这种编码方式表达每个中心指纹等价类的指纹信息。

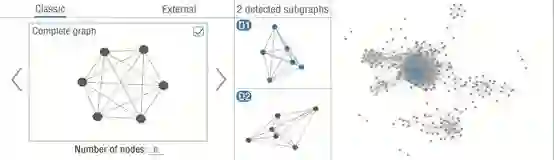
子图保护模块
子图保护器分为三个部分,左侧为子图设定面板,使用者通过这个面板设定子图,子图可以来自于一些经典拓扑结构,如形状结构,环形结构等,也支持从外部导入。在子图设定面板中,系统同样通过灰色矩形的个数编码识别得到的子图的个数。中间面板为子图识别面板,将可视化图中识别得到的当前子图结构和相似子图结构,当识别得到的当前子图结构不满足k值时,用户可以选择将相似的子图补全成为当前的子图。右侧子图结构展示面板,使用者可以通过与子图识别面板的交互查看子图在图中的位置。
历史记录视图
历史记录视图使用时间轴的形式可视化了每一步隐私保护操作后数据的变化。在每一个历史记录中,标题描述了该步骤采用的是哪种类型的保护器,记录左侧我们采用CDE(curvedensity estimates)的方法可视化了图的原始分布(即图四a的节点连接图),边越多颜色越深。在CDE得到的分布图上,我们使用深色的直线表示当前处理所增加的边,当用户鼠标移动到一个历史记录时,该步所增加的边将在图四a中高亮出来。右侧则呈现了数据指标的变化,包括指标的当前值和变化量,通过红绿颜色编码指标的增加和递减,而对于不能计算增量的指标,我们用蓝色进行编码。

最后,通过一段视频结束本次的介绍,欢迎关注和探讨。
参考资料:
【1】https://ieeexplore.ieee.org/document/8440807/

你可能还喜欢
点击下方图片即可阅读




关注「阿里技术」
把握前沿技术脉搏