灵活开发、高效训练、便捷部署不可兼得?这款国产框架表示都可以有
机器之心编辑部
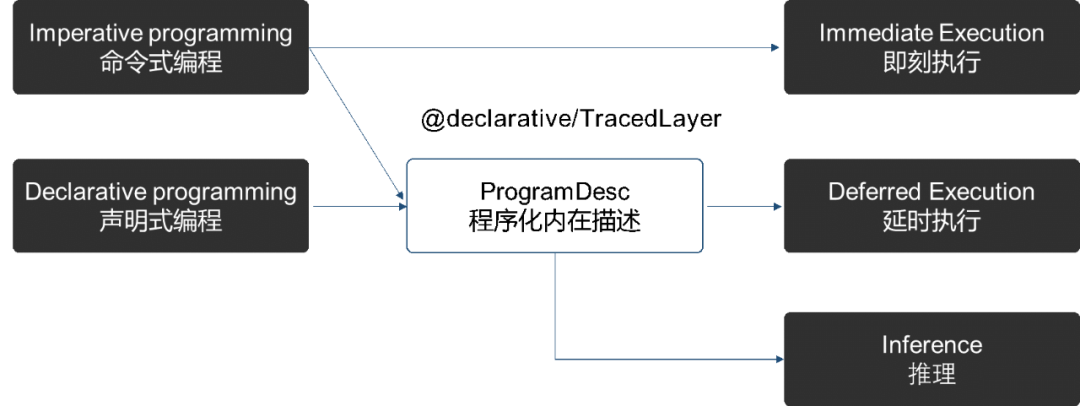
动态图性能更卓越,经过多个版本的持续深度优化,飞桨动态图的训练性能已经媲美静态图。
动静更加统一,完备实现了一键式动转静、动静混合编程,使动态图开发可以无缝衔接部署,并能通过静态图执行模式对部分模型实现进一步的训练加速。
class MNIST(fluid.dygraph.Layer):
def __init__(self):
super(MNIST, self).__init__()
self.conv = Conv2D( 1, 20, 5)
self.pool2d = Pool2D( pool_size=2, pool_stride=2 )
self.pool_2_dim = 5 * 4 * 4
self.proj = Linear(self.pool_2_shape, 10,
act="softmax")
@declarative # 添加装饰器,将forward函数内Layers递归地转为静态图的Program执行
def forward(self, inputs):
x = self.conv(inputs)
x = self.pool2d( x )
x = fluid.layers.reshape( x, [-1, self.pool_2_dim])
x = self.proj(x)
return x
import paddle.fluid as fluid
from paddle.fluid.dygraph import to_variable
fluid.enable_imperative()
prog_trans = fluid.dygraph.ProgramTranslator()
model = MNIST()
in_np = np.random.random( [20, 3, 28, 28]).astype("float32")
in_var = to_vairbale( in_np )
out = model(in_var)
prog_trans.save_inference_model("./dy2stat_infer_model", fetch=[0])
训练加速,在最外层的 Layer 加上一个 declarative 装饰器,即可把动态图转成静态图进行训练,通过全局优化可对部分任务(例如 RNN 类模型)明显提升训练性能。
部署便捷,通过 ProgramTranslator 将动态图的模型转成静态图的 program,即可实现模型的静态存储和部署应用。
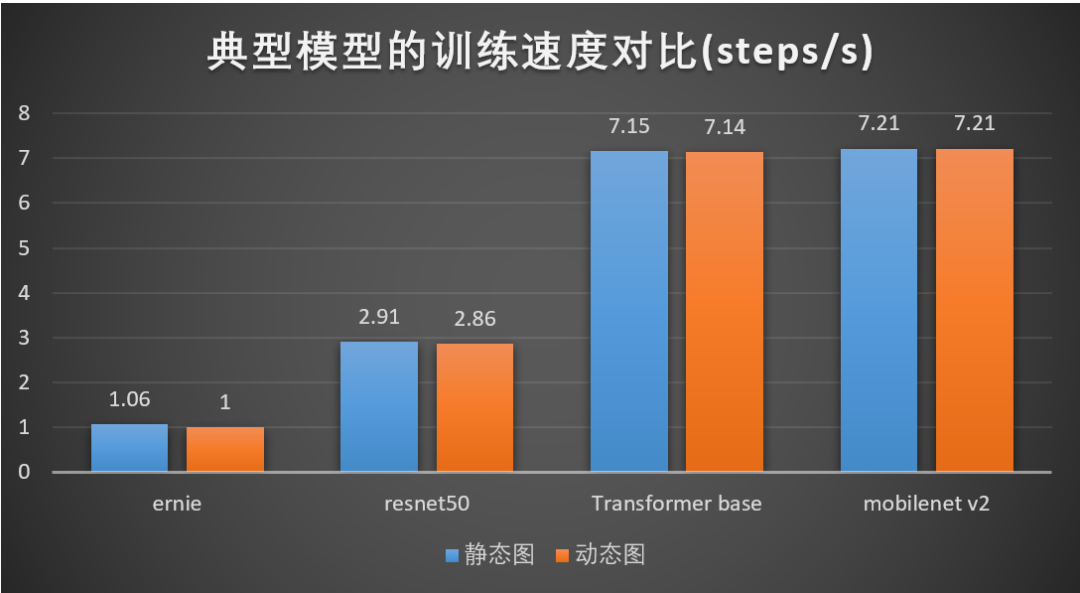
Ernie:基于 Wikipedia 数据集,配置 batch_size 50, seqlen256;
Resnet50:基于 imagenet 数据集,配置 batch_size 128;
Transformer base:基于 iwslt14 de-en 数据集,配置 max_token = 4096;
Mobilenetv2:基于 imagenet 数据集,配置 batch_size 256。
a) 减少 Python 与 C++ 交互复杂数据结构开销。由于 Python 和 C++ 端使用的数据结构不一致,会引入一次开销比较大的转换,通过优化流程,避免这类数据结构转换。
b) OP 执行优化。每个 OP 执行时,均需要做一次数据构造,OP 运行结束之后进行析构。通过优化 C++ 端的执行流程,简化数据结构,降低整体的 overhead。
c) 移除非必需的属性。在静态图时,每个 OP 需要引入一类属性对 OP 进行标记,这些属性的构造和析构耗费比较多的时间,但对于动态图不是必须的,通过移除属性的构造和析构,减低框架 overhead。
with fluid.enable_imperative() # 激活动态图模式
x = fluid.layers.ones(shape=[1], dtype='float32')
x.stop_gradient = False
y = x * x
# Since y = x * x, dx = 2 * x
# 调用grad方法
dx = fluid.dygraph.grad(
outputs=[y],
inputs=[x],
create_graph=create_graph,
retain_graph=True)[0]
z = y + dx
z.backward() # double grad计算 import paddle.fluid as fluid
import numpy as np
# forward_pre_hook函数修改了layer的输入:input = input * 2
def forward_pre_hook(layer, input):
# 改变输入值
input_return = (input * 2)
return input_return
fluid.enable_imperative()
linear = fluid.Linear(13, 5, dtype="float32")
# 注册hook
forward_pre_hook_handle = linear.register_forward_pre_hook(forward_pre_hook)
value0 = np.arange(26).reshape(2, 13).astype("float32")
in0 = fluid.dygraph.to_variable(value0)
out0 = linear(in0)
# 移除hook
forward_pre_hook_handle.remove()
value1 = value0 * 2
in1 = fluid.dygraph.to_variable(value1)
out1 = linear(in1)

登录查看更多
相关内容
Arxiv
6+阅读 · 2019年8月17日
Arxiv
4+阅读 · 2018年7月10日




相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2019年8月17日
Arxiv
4+阅读 · 2018年7月10日