赵学敏:京东商品图谱构建与实体对齐

分享嘉宾:赵学敏博士 京东科技
编辑整理:蔡丽萍 TRS
出品平台:DataFunTalk
导读:在电商企业采购和运营过程中,如果要想掌握商品的实时价格等行情信息,就需要对齐各个电商网站的商品。由于各个电商网站的运营体系不同,网站的类目体系、商品属性等等往往存在很大差异,需要将这些实体信息进行统一的对齐和匹配。此外,还需要考虑在数以亿级的商品体量下,商品信息有各种错误的情况下如何提升算法效果。本文将介绍商品图谱构建与表示、实体对齐等技术在电商领域的一些具体实践和应用。
主要内容包括:
背景介绍
技术进展
商品图谱中的实体对齐
总结与展望
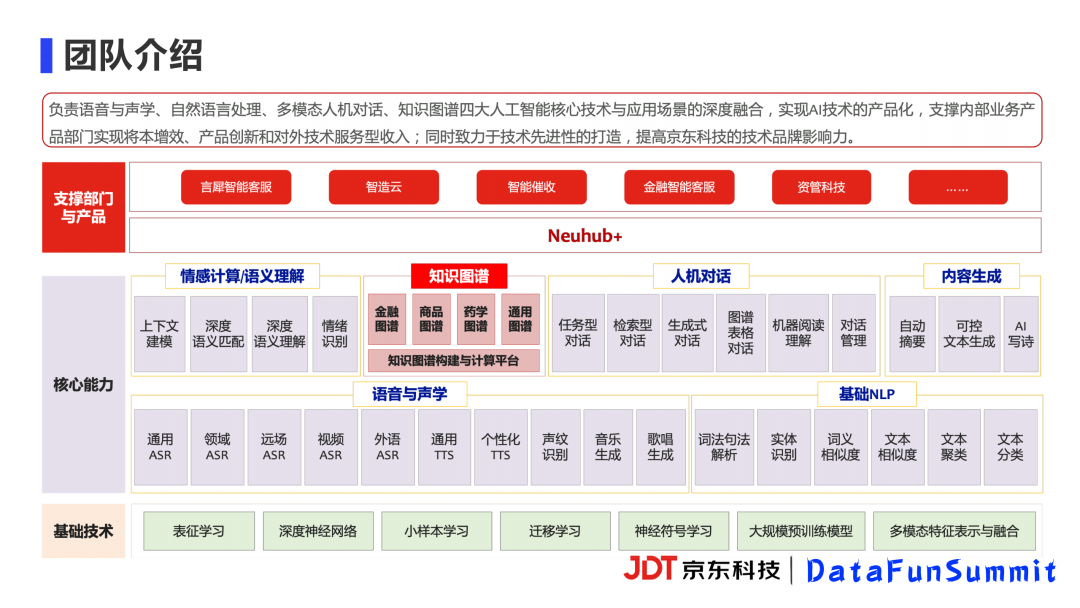
我们团队的主要研究方向包括语音识别、自然语言处理、人机对话、知识图谱,负责将这些AI相关的研究落地于京东科技内外部的各种产品中,提高京东科技的机构品牌影响力。

在知识图谱方向上,我们围绕金融图谱、商品图谱、药品图谱都有一些具体工作以及落地的应用。我们依托平台内部的一些能力,像大规模图谱处理库、机器学习平台等,为上层的各种应用提供知识图谱底座以及相关算法能力。

今天分享的内容是商品图谱当中的一个具体应用。商品图谱是以京东海量的商品为中心,全面沉淀相关的商品知识。构建图谱时区分概念层和实例层:概念层主要是沉淀一些抽象概念,比如品类与属性之间的关系;具体的实例,如属性值或者是商品SKU都会放在实例层。此外,我们还在持续推进商品图谱和通用百科图谱打通的工作,进而更好地为上层的应用提供相关的知识。

在商品图谱中,实体对齐包含商品对齐、属性对齐、属性值对齐,我们的应用中最关心的是商品之间的对齐,尤其是跨电商平台商品之间的对齐。有了这些商品对齐的结果,采销团队可以对京东商品的价格竞争力等等有一个全面的了解。跨电商渠道的商品对齐面临的最大问题是,因为各个电商渠道的运营体系完全不一样,会导致同一商品的具体描述有较大差异。同时,因为执行的运营标准也不一致,像京东自营商品的属性信息要更全一些,但是很多第三方商家的商品属性就有很多缺失,会把关键的信息直接放到标题中。此外,因为电商平台的商品都是海量数据,大数据下也会对算法的选型产生影响。
1. 实体对齐任务介绍
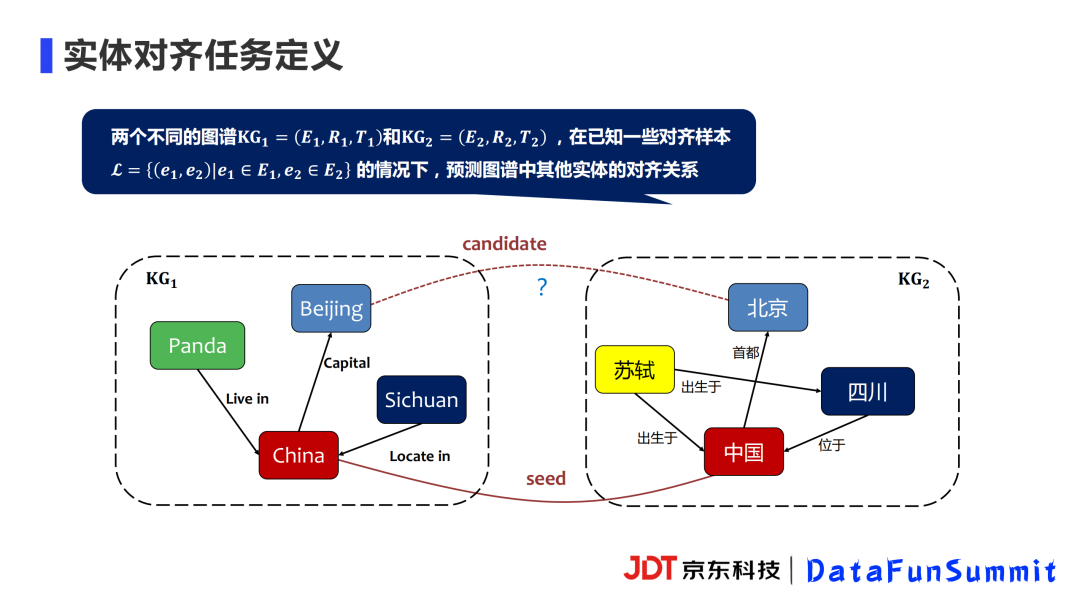
我们这里的实体对齐任务是知识图谱中的实体对齐。在很多论文中具体把任务定义为:两个不同的图谱KG1、KG2,当中的实体有一定的对应关系,在已知一些对齐样本的情况下,去预测图谱中其它实体的对齐关系。图谱一般以(E,R,T)表示。E为实体,R为关系,T为图谱中的三元组。
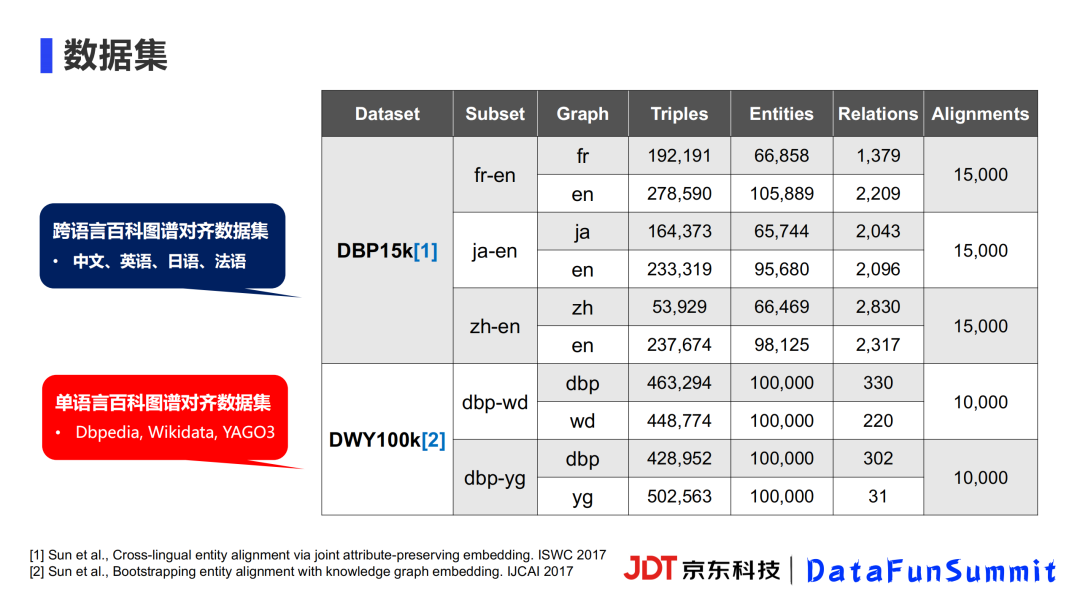
相关论文中常见的数据集有两个,都是百科图谱对齐的数据集。其中DBP15K是一个跨语言的百科图谱对齐数据集,DWY100K是三个不同来源的百科网站图谱对齐的数据集。

很多图谱对齐算法都以图谱表示学习为基础来实现,先对知识图谱当中的所有实体进行编码,从而提取实体的图谱特征。之前的研究一般采用分布式图表示学习,像TransE及其各种改进算法。目前更多的论文使用了图神经网络GNN。计算得到实体的图谱特征后,会将特征传入对齐模块。对齐模块常用的做法有两种,一种是拉近已知对齐实体特征向量在高维空间中的距离;另一种是使用一些复杂匹配模型,去学习预测实体间的对齐关系。目前主要工作都围绕着图谱编码和对齐模型两个部分展开。具体到评价指标,会把实体对齐看成是一个排序任务,使用搜索排序的相关指标进行评价,如TopK命中率,即统计前K个得分最高的预测结果中,是否包含有正确的对齐实体。
2. 实体对齐算法技术趋势
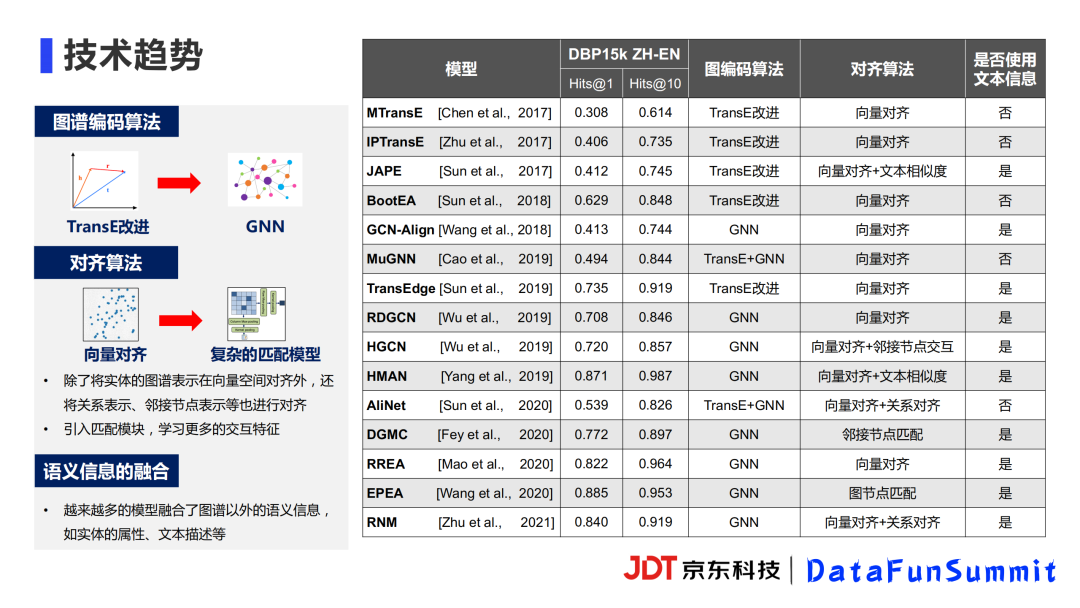
近几年图谱对齐的论文有很多,这里可能只列举到一小部分。图谱编码的算法从19年开始,几乎都用到了GNN图神经网络,之前更多的是TransE的各种改进。一方面是图神经网络表达能力比较强,另一方面是因为TransE模型是基于链接预测等任务设计的,而图神经网络可以针对实体对齐任务设计相应的特征。
在对齐算法部分,现在采用的对齐算法越来越复杂。除了最开始简单的向量对齐之外,更多的实体特征可以被引入,比如:图谱中的关系表示、邻接节点的匹配关系等等。同时也可以引入匹配模块,专门学习实体对之间的交互特征。
我们还发现越来越多的论文融合了图谱以外的语义信息,如实体的属性、文本描述等,这和实际应用场景是非常契合的。因为实际应用中图谱里面的实体一般也有一些对应的一些文本描述,甚至是多模态的信息比如图像等等,这些信息都可以加以利用。
1. 商品图谱对齐需要考虑的问题
商品图谱实体对齐需要解决的问题,包含以下三个方面:
大数据下商品知识图谱如何进行训练和在线预测。
商品属性多,属于关系稠密型图谱,需要自动学习关键商品属性并减少噪音信息影响。
文本语义信息在商品描述中作用很大,需要融合结构化和非结构化的信息。
2. 线上预测流程

这是我们目前线上采用的预测流程。我们的任务是将商城A的商品数据和商城B的商品数据进行对齐。如果我们把这个任务看成搜索或者匹配过程的话,我们实际上是以商城A的商品信息作为查询条件,在商城B的所有商品中查找要匹配的商品,同时对查询的候选结果进行排序。当然这个过程也可以反过来,把商城B的商品信息作为查询条件。在我们具体应用中,一般是京东商品和别的渠道商品进行对齐。我们能获取到的京东商品数量远远大于其他渠道的商品数量,所以一般把其他渠道的商品作为查询条件,京东商品作为搜索的候选集,这样可以加速查询匹配的过程。
对齐可以分成四步:召回、精排、粗排、重排。重排实际上是结果的后处理,主要是根据一些校验规则过滤一些bad case。在匹配之前,我们会预先做一些图谱schema的对齐工作,包括商品类目的对齐、属性的对齐等等。粗排和精排都使用了有监督模型,确保排序结果的准确率,对于属性值缺失的情况,会应用属性抽取模型补齐商品属性,强化商品自身的结构化信息。
3. 数据集构建和业务评价方法

前面提到粗排和精排都使用了有监督模型,模型训练需要一些正负例的数据。正例数据是互相匹配的商品pair,正例数据的获取是先通过简单的无监督商品相似度模型得到初步的候选集,再结合一些规则过滤后,通过众包标注确认是否匹配而得到的。
负例数据是不匹配的商品pair。理论上我们可以通过随机采样轻易地获得,但这样得到负例样本非常容易区分,不利于提高我们模型的鲁棒性。我们希望能够尽可能得到一些比较对抗性比较强负例,也就是很相似但又不匹配的样本。我们可以利用电商网站中SPU和SKU的概念去构建大量对抗性的负例。比如我们打开京东app要购买一个手机,通常在一个手机商品的页面上,有很多不同配置的手机,比如内存大小颜色不同。SPU就是同一款商品的概念,SKU就是配置具体到不能再区分的单品。一般情况下同一款SPU下,不同SKU的商品之间仅在个别属性上有区别,这样的商品作为负例的话,对于模型区分的难度是很大的。
在具体业务中,我们可以离线评价模型的算法性能指标,比如使用之前提到的TOPK命中率,但在线上业务中,TOPK命中率作为指标就不适合了。这是因为TOPK命中率只是把测试集中的商品样本作为候选,但在线上检测时,面对的是全量的商品库,数量要大得多,同时还存在很多难以区分的商品。所以,我们线上是通过商品检出率和检出商品的准确率两个指标评价模型的效果。我们以京东商品作为查询条件为例,如果能在其他渠道的网站中能找到对应商品,那么我们统计有对应商品的京东商品数量,然后计算这部分京东商品在全部京东商品当中的比例,这个比例就是商品检出率。理论上两个商品库都可以以此方式分别计算检出率,我们的实验结果显示,两个商品库的检出率指标往往是正相关的,我们计算一个就可以了。
检出商品的准确率,是将检出的商品匹配结果进行抽样后,然后标注计算正确结果的比例得到的。随着线上商品上架下架,以及随机采样的差异,检出准确率会有一定范围的波动,我们会调整模型检出阈值等,将准确率稳定在一定范围内。在准确率稳定的情况下,就可以通过比较模型的检出率来评估模型的效果了。
4. 召回与粗排部分

我们用到的精排模型是深度图谱对齐模型,模型的运算量比较大,为提高运算效率,候选的商品数量应控制在一定范围内,比如100以内。而召回是通过简单的规则如判断是否为同一品牌的商品等等实现的,召回商品的数量还是很多。因此,需要在中间加入粗排模型,我们使用了一个文本匹配的模型作为粗排模型。该模型训练时,把商品的标题作为输入,然后通过Bert编码得到编码结果后计算两个商品向量的余弦距离来进行匹配的。为了加速,我们将模型进行了蒸馏,提升模型的编码速度。另外,我们还使用了向量索引进一步加速粗排的过程。
5. 精排算法
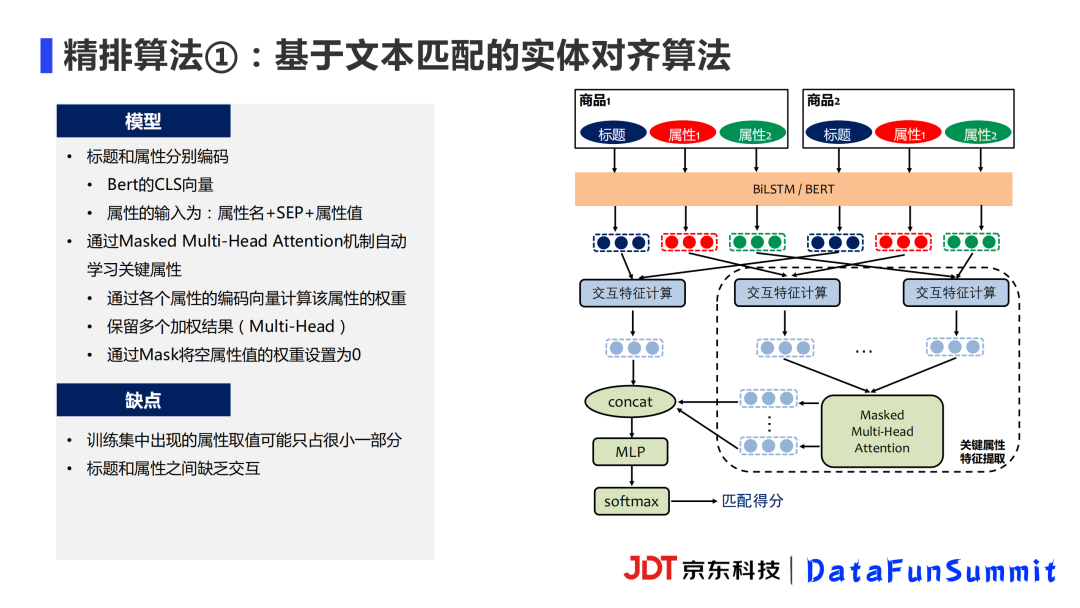
最开始使用的精排算法也是基于文本匹配来实现的。粗排用到的匹配模型只考虑了标题。人工对比商品时,我们会去比较商品的关键属性,比如笔记本电脑,我们会去看CPU型号是否匹配,内存大小、屏幕大小等等是否一致。除了将标题进行编码外,属性值也要进行编码,然后分别在两个商品之间进行特征匹配。因为商品的属性很多,需要提取关键属性,我们采用attention机制去自动学习各个属性的权重。因为关键属性可能不止一个,我们会保留属性匹配特征的多个加权结果,类似于Transformer里面的Multi-Head机制。对于空值属性,我们使用Mask将其权重直接设置为0。最后再基于关键属性和标题的交互匹配特征计算两个商品之间的相似度。
以上模型的缺点有两个:一是需要预先将属性进行对齐;二是训练集当中商品样本在商品库当中只占据很小的比例,很多商品属性值在训练阶段都没有见过。因此我们希望引入图谱表示学习对整体的商品库进行建模,从而增强模型的效果。
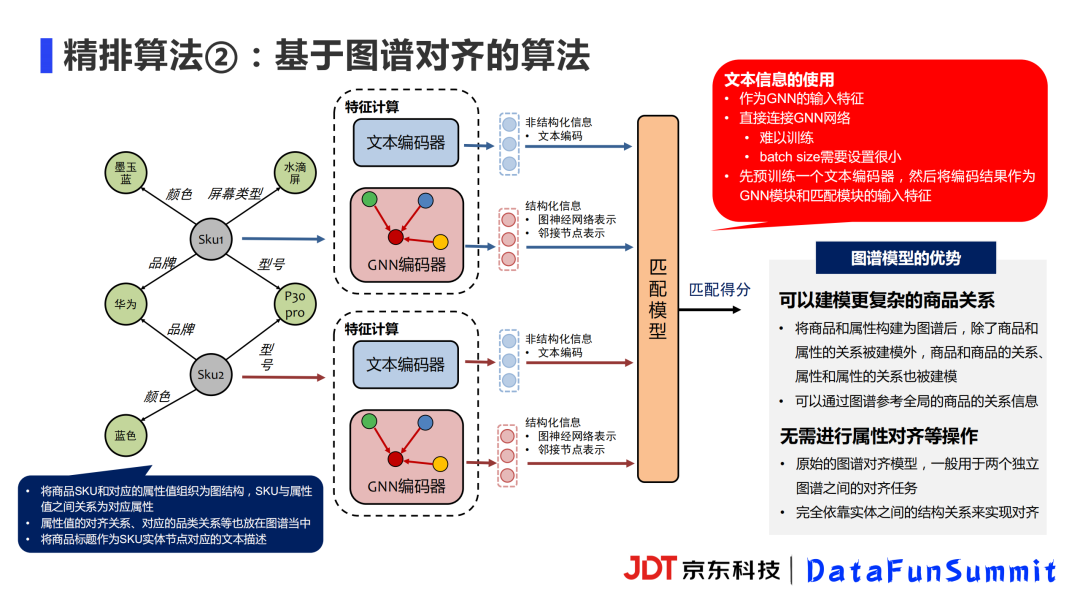
这是现在线上使用的图谱匹配模型的框架。我们会预先将商品SKU和对应的属性值组织为图结构,SKU与属性值之间的关系为对应属性类别。另外,已知的一些属性值的对齐关系、品类的对齐关系也放在图谱当中。因此图谱当中主要是两个类型的节点,商品SKU节点和属性值节点,其中SKU节点将商品标题作为该节点的文本描述内容。
除了图谱本身的结构化信息外,模型会融合非结构化的信息如文本等。很多论文将文本编码结果直接作为GNN的输入特征,我们曾经尝试将文本编码器直接放在GNN前面去进行训练,但这样做模型的训练速度非常慢,效果也不及预期。目前的做法分为两步:先预训练一个文本编码器,然后将编码结果作为GNN模块和匹配模块的输入特征。另外,这个文本编码器同时还作为粗排模型。
图谱模型与前面的文本匹配模型相比,有以下优势:首先,该模型可以建模更复杂的商品关系。将商品和属性构建为图谱后,商品和商品之间的关系、属性和属性之间的关系都可以被建模;其次,可以通过图谱的结构化表示,引入商品在商品库中的全局信息。最后,图谱对齐模型并没有假定两个图谱各自的关系需要事先对齐,在本应用中,也无需预先进行属性的对齐操作,在训练过程中可以自动实现对齐。
6. 处理大规模图谱

商品图谱的数量一般比较大,我们考虑使用Inductive模型进行训练。传统的GCN等模型都是Transductive模型,需要全部节点参与训练才能得到embedding表示。当节点数量很多时,会因为显存或是内存的限制而无法进行训练。此外,在网络结构发生改变时,模型会直接失效,新加入的节点都需要重新训练才能得到对应的图谱表示。这在实际业务场景中是不可接受的,因为商品会经常有上架下架的操作。
我们采用了Inductive模型,该模型会不断聚合邻接节点的信息去更新目标节点的图谱表示。具体是基于图谱采样来实现的,比如:先查询得到图中红色节点的所有邻接节点,当节点的邻接节点非常多时,要对邻接节点进行采样,控制运算量。图神经网络一般会训练多层的表示特征,每一层节点的表示由上一层的邻接节点的表示聚合而来。经过多层的表示之后,也就集成了多跳的邻接节点信息。
7. 图谱表示学习

在介绍我们的模型前,我们简单回顾一下图神经网络模型。主流的图神经网络模型,都可以用Message Passing框架来进行描述,具体分为以下几步:
第一步:邻接节点决定向目标节点发送什么样的特征,也就是图中的Message函数,这个过程在图谱当中的每条边上单独执行。
第二步:目标节点聚合收到的邻接节点的Message特征,也就是图中的Aggregate函数,这个过程在图谱当中的每个节点上单独执行。
第三步:目标节点根据邻接节点消息聚合结果,以及节点自身的特征,更新节点在网络下一层中的特征表示。也就是图中的Update函数,也是图谱中每个节点都执行一遍。
这也是很多图深度学习框架如DGL等设计其API的基础。

在商品图谱中,图谱表示学习必须要考虑到实体之间的关系,我们构建的图中,大部分实体关系都是商品属性类别。前面的模型也提到,并不是所有的属性都对商品匹配有帮助,需要提取关键属性。我们采用的做法是设计特定的Aggregate聚合函数,使得聚合邻接节点的Message的时候,各个邻接节点的重要性权重由每条边上的Relation来决定。Message函数和Update函数我们直接使用线性变换来实现。
在公式中,mj是目标节点i收到邻接节点j的消息,聚合消息时,会有两个权重:第一个权重αij是根据邻接节点j和目标节点i的消息向量mj和mi拼接后计算得到的。在具体图谱中,这个权重代表了标题和属性值的匹配相关度,通常在标题中出现的属性值重要程度越高。第二个权重βij是根据节点连接边上的关系类型计算得到的,每个关系类型也用一个向量进行表示,然后基于这个关系向量去计算得分。两个权重相乘后,最终得到每个邻接节点在Aggregate函数中的权重。
8. 图谱匹配算法
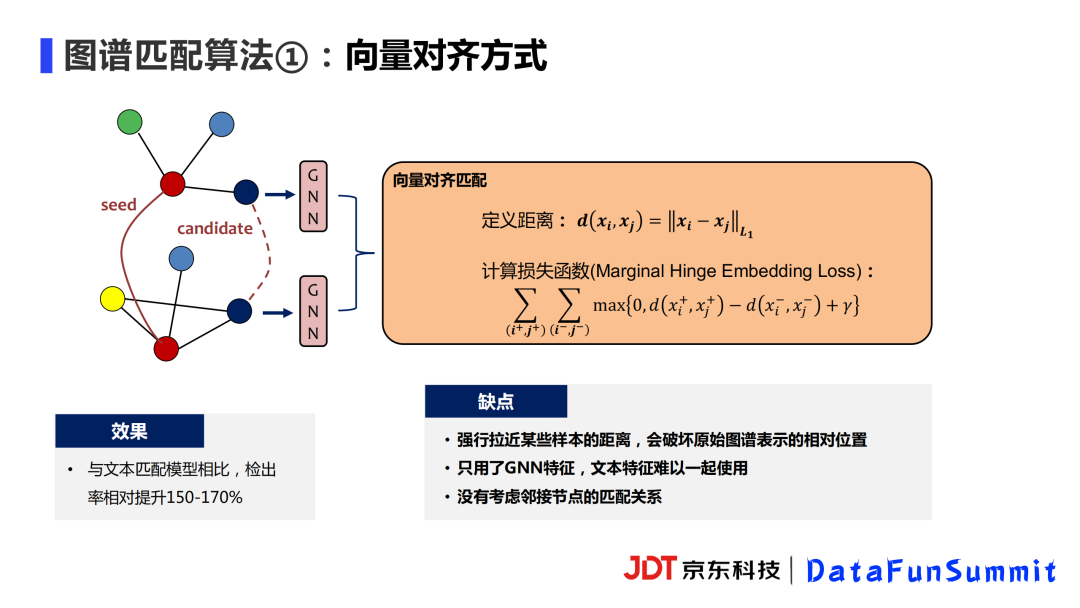
我们在一开始采用了向量对齐的方式实现图谱对齐,我们使用L1距离作为两个向量距离的度量。在Embedding Loss的影响之下,正样本之间的距离会越来越近,而负样本之间会保持一定的距离γ。与前面的文本匹配模型相比,本模型的检出率相对提升了150%以上。但是该模型有一个缺点,强行拉进两个图谱某些样本之间的距离,会破坏原始图谱表示。另外,这个模型利用到的文本信息、邻近节点信息都要少一些。

这是我们后来使用的匹配模型,除了将候选实体直接进行匹配外,还要利用邻接节点的匹配信息。这其实是基于一个假设,如果两个图谱当中的实体互相匹配的话,它们的邻接节点往往也有很多节点也存在匹配关系。
具体实现的时候,我们除了用到每个节点的GNN表示外,还要利用邻接节点的GNN表示进行匹配。提取两个向量的匹配特征时,主要是计算向量之间的余弦距离,得到两个向量的相似度得分。因为每个节点的邻接节点有很多个,两个节点的邻接节点两两计算会形成一个矩阵。我们需要对矩阵的关键信息进行提取,对于每个邻接节点来说,与之对应匹配的邻接节点一般也只有一个。这样的话,我们通过Max Pooling就可以提取出最匹配的邻接节点的相似度得分,这个Max Pooling在行、列方向都会进行。另外,不是所有的邻接节点都对最终是否对齐的判定有帮助,在Aggregate过程中得到的邻接节点的权重,可以在这个地方用于确定邻接节点的权重,这个权重与前一步邻接节点的相似度得分Max Pooling结果进行相乘。最后,为了进一步提取邻接节点相似度得分的关键信息,我们使用Kernel pooling,它既保留了关键信息,又没有引入过多噪声。最终预测得分要同时融合Kernel Pooling提取的邻接节点匹配特征、两个节点的GNN表示的余弦相似度特征、两个节点文本表示的余弦相似度特征计算得到。与向量对齐模型相比,本模型的检出率又有进一步提升。
9. 商品属性抽取

很多第三方卖家的商品属性填值没有那么规范,会存在很多商品属性的缺失或者错误。如右侧图片所示:CPU型号等关键信息都集中放在一些选项卡或者标题当中,没有放在具体属性里面。因此我们要预先对商品进行属性值抽取。商品属性的补全可以大大提升模型的检出率,重点品类的检出率能提升3到5倍。我们使用序列标注模型实现在商品标题当中的属性值提取。

商品属性抽取是一个典型的NER任务,因为商品的属性通常比较多,为了加快计算我们把整个属性抽取分为两步:第一步是预测商品标题中有哪些潜在的属性值;第二步,再去预测这些潜在属性值的类别。在商品属性提取时,使用商品的品类信息对于效果提升有一定帮助,品类的embedding特征会帮助我们在标题中要关注哪些字段。另外,我们根据已知的属性值,通过匹配的方式能在标题中找到一些候选的片段,利用这些候选片段可以提升属性抽取的召回率。商品属性预测也是一个比较大的话题,具体细节就不展开了。
1. 总结
本次分享介绍了通过融合了文本表示和图谱结构化表示的实体对齐模型,在电商领域中实现了商品之间的对齐任务,并利用商品属性抽取进一步提升了图谱对齐的检出率。
2. 展望
接下来的工作会考虑以下几个方面:
在商品图谱中引入更多的商品关系以及通用知识,进一步提升实体对齐的算法性能;
引入商品图像等特征,实现多模态图谱对齐;
将属性抽取的特征更好地应用于图谱对齐过程中;
更好的融合结构化和非结构化信息;
提升小样本类别的效果。
Q:数据schema对齐过程中,schema数据是人工对齐的吗?
A:schema对齐目前是采用无监督的方式。因为商品数量比较大,通过简单的无监督模型,效果已经比较好了。也可以结合人工审核去提升schema对齐的准确率。
Q:标注过程是需要人工的吗?
A:匹配结果标注是需要人工参与的。
Q:正负样本的选取过程中,它的比例是如何确定的?负样本的生成,有什么策略?
A:负样本的生成主要利用SPU下的不同的SKU来生成,每个正样本都会针对性的生成负样本,正样本商品所在SPU中,其它的SKU商品都可以作为负例,这类负例样本的对抗性更强。也有随机抽取、batch内计算相似度采样等方式。现在正负样本比例是1比10,这个比例是根据实验确定的。
Q:表示学习和对齐的模型中,属性是怎么学习的?
A:商品属性会有对应的embedding向量表示,这个embedding在训练过程中是参与优化的。在初始化的时候,我们会通过BERT编码计算所有对应属性值embedding向量,然后平均后作为属性初始化的embedding值。
Q:实体对齐的效率和性能会不会受到实体节点数量的影响?超大规模的节点对整个性能会有多大的影响呢?
A:目前处理速度要慢一些,我们做了几百个品类的对齐,对齐过程需要几个小时,运算量还是很大的,接下来会进一步优化处理效率。
Q:数值型的数据是如何在知识图谱中使用的呢?
A:目前没有单独处理数值型数据,会统一把这类数据当作文本数据来处理。
Q:商品实体对齐过程中结构信息占比有多大?它对实验效果有多大影响?
A:这个可以对比图谱对齐和文本匹配模型的实验效果:与未使用结构化信息的文本匹配模型相比,使用结构化信息的向量对齐模型检出率相对提升150%以上。
Q:不同品类的对齐用哪些属性有啥策略,这些是人工定义的还是自动生成的?
A:目前没有对类别进行特殊的处理,所有商品类别都在一个模型中进行训练。
Q:图注意力网络如何融入边的信息,通过边的信息来影响邻近节点的权重?
A:如前文介绍,我们有α和β两个系数,α可以看成标题和属性的匹配程度,β是根据属性类别,也就是边的类型来判断属性相似度。这个权重一方面会在聚合邻近节点时用到,另一方面在最后邻近节点匹配时也会用到。
Q:模型上线部署时,模型推理效率的问题是怎么解决的呢?
A:通过粗排模型减少候选的数量。此外,在文本编码时,可以预先去缓存一些高频属性值编码,这样在第二步训练时这部分内容可以直接作为输入,就不再单独计算了。
Q:请问老师schema构建的过程中,有用propagate这种本体构建工具吗?
A:没有用到。因为大部分数据是商品和属性之间关系,这个关系是商城中天然的结构化的数据。
Q:正负样本的比例不均衡的话,如何消除样本对结果的影响?
A:目前正负样本的比例是经过实验得到的。如果负样本很多的话,确实会对召回率、检出率会产生影响,需要在业务上和效果上需要一个平衡。
Q:在使用图结构融合时,有没有试过把两个实体的多个属性拼接成文本,转化成文本相似匹配的方式去做?
A:尝试过类似的模型,因为这种模型可以提前交互文本匹配特征,效果也不错,但是商品属性太多,有时候会影响计算效率。另外图神经网络的优势是可以融入结构化的信息。
Q:商品关系里面会有除了属性以外的其他关系吗?
A:我们还用到了属性对齐关系,品类归属关系等等。另外SPU关系也用到了。
Q:在RGCN模型训练中,如果图数据比较小,会影响embedding的效果吗?多大规模的数据训练会比较好呢?
A:我们没有使用RGCN模型。
Q:在训练过程中,如果图数据会比较小的话,该怎么处理?因为TransE等模型对于大规模数据效果比较好,但是小样本数据训练的话,该怎么去处理呢?
A:小样本的情况下,仅通过图的结构化信息是很难保证效果的,可以把优化的重点放到额外信息利用上,比如文本信息等等,这时候可以利用BERT等预训练的模型。对于图谱本身而言,样本数量少的话,很难达到预期效果。在小样本的情况下,文本信息可能要更重要一些。
Q:在这个训练过程中,如果结构信息不强的长尾实体,即:3元组比较小、比较少。这类长尾实体的匹配,您有什么好的解决办法吗?
A:对于结构信息不强的长尾实体,要设法对其进行信息补全,比如我们做的商品属性抽取的工作就是补全结构化信息。另外还是尽可能利用到额外的信息提升效果。
Q:在实体匹配的过程中,会提前去看文本的匹配效果吗?
A:会提前看。我们使用的粗排模型就是文本匹配模型,同时还作为图神经网络模型的初始化输入,直接影响最终效果。为了在粗排阶段不损失性能,我们训练粗排模型,使得Top100命中率达到一个比较高的效果,比如99%以上,也就是粗排的前100结果中基本都能包含正确结果。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“知识图谱” 就可以获取《知识图谱专知资料合集》专知下载链接