【R爬虫-2】上海市各小区挂牌均价

傅兴:R语言中文社区专栏作者
个人公众号:Rapp
房价一直是中国老百姓最关心的话题之一。Rapp 也一直想分析房地产方面的数据。如果拿到全国的房价数据,不仅可以知道各个城市最贵的和最便宜的房子在哪里,哪些区域的房价更高,还可以研究房价和医疗、教育资源以及公共交通设施之间的关系,房价与政策之间的关系等等。
想要获取这样的数据并不难,只需要一点点编程知识。看完本文后就会觉得更加简单了,只需要安装Rapp开发的R程序包(lianjiaScraper),使用一个命令就可以轻松下载上海市各小区的挂牌均价。
下面我向大家介绍一下 lianjiaScraper 的开发过程以及使用方法:
1. 选择目标数据源,确定抓取的对象和范围。
经过一番比较,我选择了链家网 (http://sh.lianjia.com/xiaoqu) 的“小区”信息作为抓取的对象:
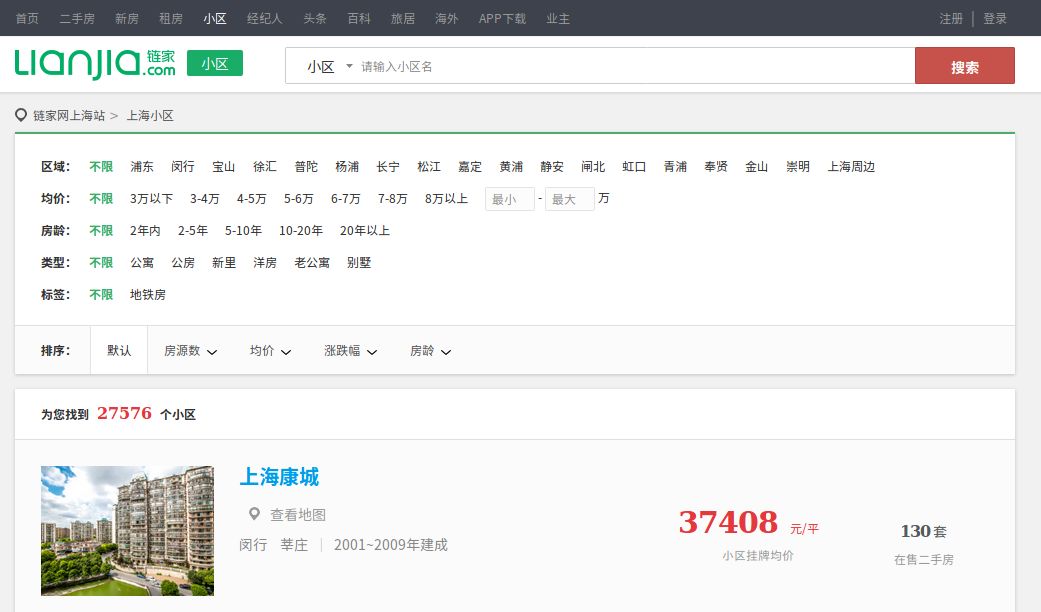
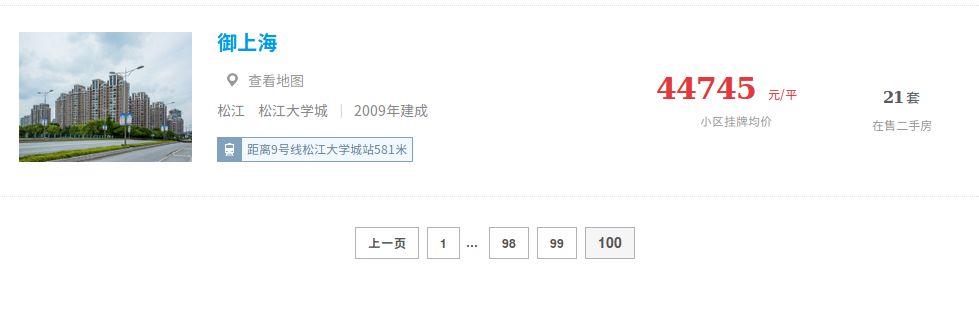
链家找到的27576个小区并不是列在一个页面中,所以我们还要弄清楚总共可以抓取多少页面,在小区列表的底部,我们看到一共有100个页面:
我们还发现每个页面的URL具有以下格式:
http://sh.lianjia.com/xiaoqu/d
调用每个页面的时候只需要在 d 后面加上页面序号即可。
2. 查看页面的HTML代码,找到需要抓取和解析的标签。

从页面的源代码中可以看到,页面中所有小区信息放在一个 <ul class="house-lst"></ul> 中,每个小区包含一个 <div class="pic-panel"></div> 和一个 <div class="info-panel">,我们感兴趣的信息在 <div class="info-panel"> 中的 <div class="where"></div> 和 <div class="price"></div> 中。
3. 用 rvest 写爬虫函数

4. 将爬虫函数以R软件包的形式发布,源代码上传至 Github (https://github.com/bioxfu/lianjiaScraper)
5. 安装 lianjiaScraper 的方法见README
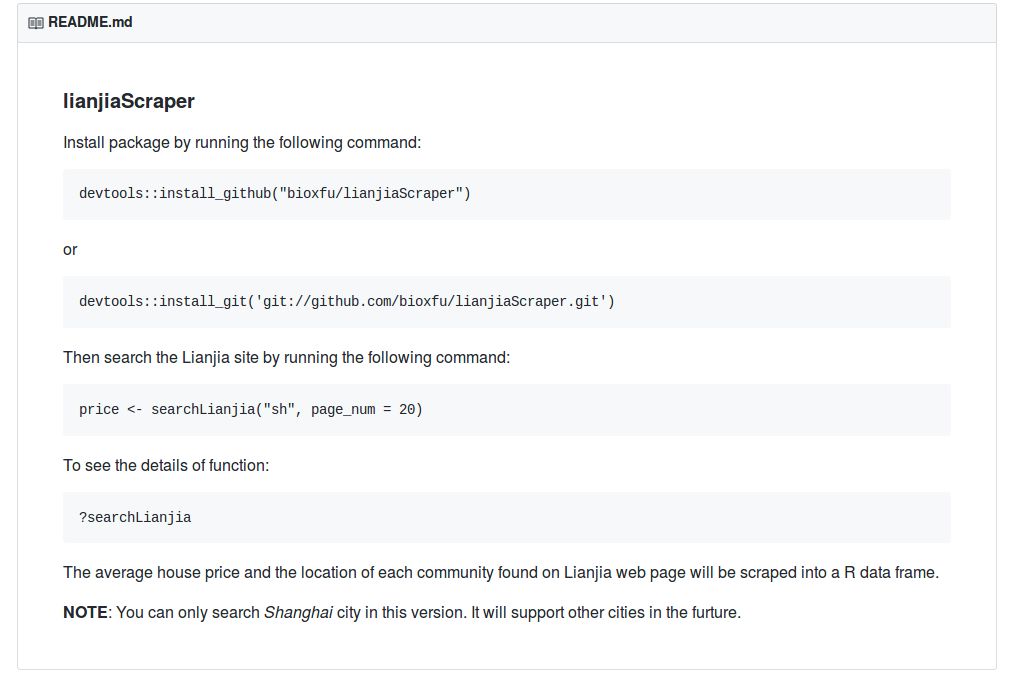
6. 安装完毕,测试

7. 抓取到的数据包含了小区名称、区域名称、板块名称、单价以及经纬度信息
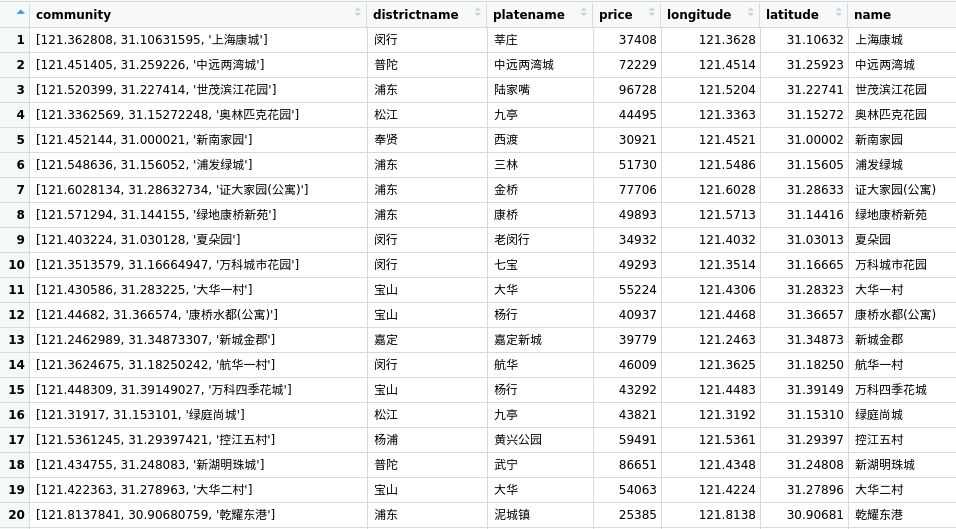
8. lianjiaScraper 现在仍处在开发阶段,目前只有一个 searchLianjia 函数,而且只能下载上海市的数据,我会不断完善相关功能:

房价数据到手后如何分析和可视化?请听下回分解。

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法




