Reading Club | 算法和人生选择:如何给洗好的袜子排序呢?

大数据文摘作品
作者:Andy
主播:段天霖
在美国的计算机程序及代码问答平台Stack Overflow上,有这样一个神级问题,它在2013年被提出之后,就引发了上千人总计万字以上的激烈讨论:如何在洗完衣服后把洗衣机里10双不同花色甚至大小的袜子精准并高效地匹配起来呢?
其实小到一双袜子,大到整个人类社会,排序都是无处不在的:当你打开微信,聊天信息是由最新时间排序的;当你在某宝剁手,商品是按热度排序的;当你百度一下你就知道,你所看到的链接也是按照相关性排列的,甚至度娘和其他搜索引擎本身就是一个复杂的排序引擎。
本周,我们来聊聊【排序】这个或大或小的话题。点击收听由来自杜克大学美女主播段天霖与大家分享:无处不在的排序。
如果真要追本溯源,排序从某种意义上促成了计算机的诞生。
排序的盛宴
19世纪末,美国人口大量增长,导致人口普查整理表格时需要花费大量时间。那时可没有Excel这么方便的排序功能,都得靠人力。应运而生的就是由Herman Hollerith发明的可以用来储存信息的打孔卡以及配套的“读卡系统”Hollerith Machine。当时很多人并不看好这项发明的应用前景,认为它只适用于处理政府事务,事实证明悍跳预言家是很容易被实力打脸的,几年后,Hollerith的公司合并更名为International Business Machines,简称IBM。
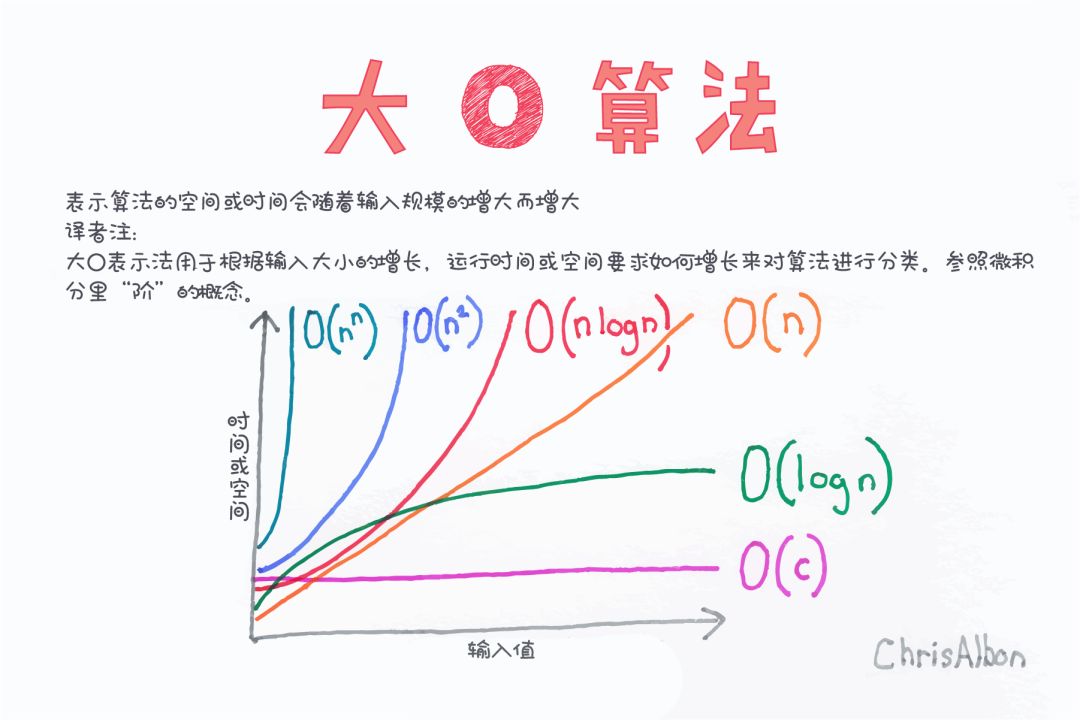
在介绍具体的算法之前,我们需要一个标尺来度量在这样大量级下算法的性能。
Big-O
偷懒的计算机科学家们从数学里借来了Big-O表示法,O 表示 order of function (函数的阶),而计算机科学里习惯称计算复杂度。值得注意的是,它所衡量的是在最差初始情况算法完成排序时的计算复杂度,而并非最优情况。
根据最差情况下的计算复杂度,我们可以将不同算法大致分为以下几个量级:
O(1),也叫“常数复杂度”
表示计算时间与n无关。比如今晚你要喊老铁来家吃饭,得先收拾一下房间,因为你的客厅并不会根据人数的多少而变大变小,单论打扫的时间应当是一个与人数无关的常数。
O(n),线性复杂度
假设你要为每位老铁准备一道菜,那准备菜的时间便会随人数n线性增长。所以收拾房间和准备晚餐的时间一个是O(1)一个是O(n),那么到目前为止你所花费的时间用Big-O表示是不是就是O(n+1)呢?并不是。Big-O表示法关注的并不是一个具体的数值,而是一个计算的复杂级别,这是因为n非常大时,往往低级别的计算复杂度可以直接忽略。还有n前的常数项都要省去,比如2n和n的Big-O表示法都是O(n)。
O(n^2 ),又叫“平方复杂度”
准备工作完毕,老铁们陆续到来,秉着团结友爱的精神你和n个老铁总共n+1个人决定要两两之间来一个深情拥抱 ,那么你们所需要的时间就是平方复杂度O(n^2)了。
O(2^n),指数复杂度
一种比较坏的情况,每增加一个对象花费翻倍。
平方级:冒泡排序和插入排序
最经典的两种经典排序算法就是冒泡排序和插入排序。有多经典呢?要知道奥巴马当年因为在和谷歌CEO的访谈中正确回答了一个关于冒泡排序的问题,不知道获得了多少程序员的选票。
为了更好地了解这两个经典算法,我们来假设有一队高矮不一的小朋友杂乱地站成一列,而我们的任务是要帮助他们按照身高来排队。
冒泡排序,就是从第一个小朋友开始,和第二位比,如果比他高就交换,矮就不变。然后第二个位置,和后面一位比,同样的操作... 当到达队尾,再循环回队头,直到将整个队伍过一遍,而没发生一次交换。这样交换的方式有点像气泡上浮的感觉,因此叫冒泡算法。
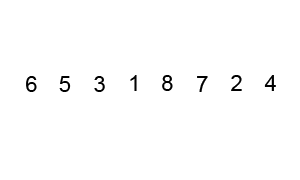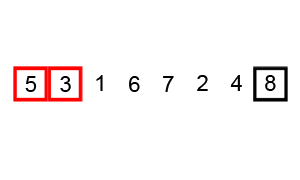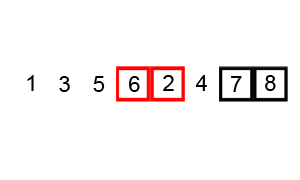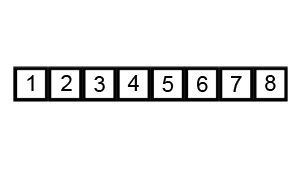
图片来源:维基百科
而插入排序,则是先随便挑个小朋友站出来,然后再从其余中挑一个,和站出来的小朋友比,放到适当位置。之后挑下一个,和已经排好的小朋友比较,插入到适当位置... 直到把人都放入排序组。
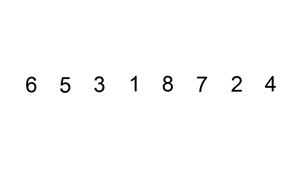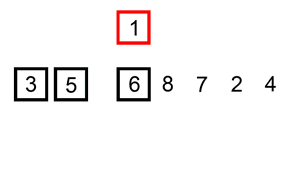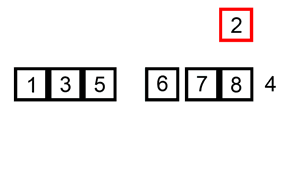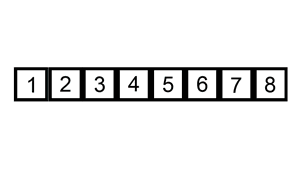
图片来源:维基百科
合并排序 (Merge Sort)
有没有比平方级更高效的算法呢,这个倒真可以有,这就要说天才冯诺依曼提出的合并排序 (Merge Sort)算法了,它利用一种叫做分而治之(Divide and Conquer)的思想找到了一种介于O(n)与O(n^2)之间的复杂度,那就是线性对数(Linearithmic)复杂度O(n logn)。
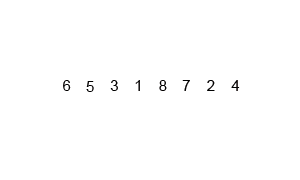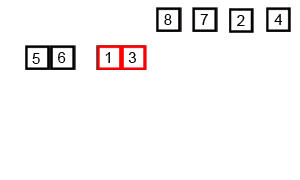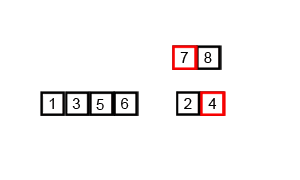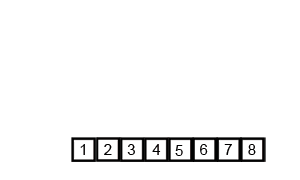
图片来源:维基百科
部分排序
其实真要说起来,线性级的复杂度也不是完全不可能,起码在华盛顿附近一个叫做普雷斯顿的小镇,有一个叫做普雷斯顿排序中心的神秘组织就号称到达线性复杂度的排序算法,并在美国国家图书馆排序比赛中取得了两次冠军。
他们能在线性时间内做到的只是部分排序,也就是将书分类放入几个内部不用排序的桶,然后对桶进行排序就好了。这种方法叫做桶排序 (Bucket Sort) 法,那么假设有m个类和n本书,需要比较的最大次数就是mn次,而当n很大m比较小时,其中m可被忽略表示成O(n),线性复杂度就这样达成了。
生活中排序那些事儿
仔细一想,生活中很多时候我们都不需要达成完全排序,而只是关注序列的某一部分,比如说百度时我们真正关心的只是前面的链接,而选秀节目只关心10进7、5进3,海选的千军万马并不需要决出谁是第2万名或是2万零一名。
首先马上能想到的是单淘汰赛 (Single Elimination),抓对厮杀,赢的进入下一轮,输的淘汰。不过这种赛制下实力第二的选手如果在前几轮中遭遇实力第一的选手,那么他们中总有一名要过早止步而拿不到任何名次,因此很多人都非常质疑这种赛制的公平性。
其实聪明的中国古人早就已用上合并排序算法,那就是科举制。
科举制从上到下分为殿试、会试、乡试、院试,还有县试和府试,而天下读书人从最低的县试与府试开始排序,之后合并到上一级,重新排序,再到上一级... 正与合并排序的思想相同。这样超前的排序方式一方面让李世民大叹:“天下英雄入我轂中矣!”,另一方面也着实漏掉了不少后人公认的才子,毕竟一次比赛或考试的结果也是由很多因素决定的。因此在评价一个算法时我们不仅要关注它的排序效率,还需要关心它有多强的抗干扰性,即在这样一个充满不确定性的世界中取得足够可信结果的能力。
算法中的许多假设和前提是将现实世界中我们所面对的情况极大简化了的,我们在做重大选择的时候,很少能用一两个简单的数值作为决定的标准,就像用某一特定个维度的表现来概括一个人是很不负责也不公平的。因次排序算法所启发我们的,依旧不是一个普适的解决方案,而是一种包容和平衡的视角:根据不同的需求和背景来选择最适合的方案。
以上就是Algorithm to Live by第三章的内容主要内容,点击阅读原文收听大数据文摘喜马拉雅专栏音频《生活中的算法》专辑。
点击收听前两章内容:
Reading Club | 算法和人生抉择:午饭到底吃什么?
大数据文摘读书会正在进行中,点击这里加入我们~
【今日机器学习概念】
Have a Great Definition
公开课推荐
稀牛学院+网易云课堂
隆重推出【人工智能系列公开课】
一线大咖讲师直播互动
解密人工智能热点话题
给你最贴心的AI学习指南!
扫码可领取独家学习资料

志愿者介绍








