全球首次!AI画作将于周四在纽约被拍卖,估价超7000美元
在“阿尔法狗”之前,围棋一直是人工智能无法攻克的壁垒,直到李世石、柯洁等最优秀的人类棋手在它面前投子认负。在那之后,“艺术”成了人类坚守的下一个“倔强”:人工智能总不能不懂创作和审美吧?可挑战这么快就来了:今年10月,由人工智能创作的一幅肖像画将在纽约佳士得拍卖会上出售,这是AI艺术品第一次参加拍卖会,估价为7000美元至1万美元之间。人类会愿意为人工智能创作的艺术品买单吗?艺术家会逐渐失业吗?技术迭代太快,人类需要思考和忧虑的太多,文化艺术,这个领域人类还守得住吗?
据悉,这场“历史性一拍”将在10月23日至25日举行,佳士得也将成为首个出售AI艺术品的大型拍卖行。这次拍卖的是一幅人物肖像作品,而画中的主角是由人工智能系统虚构出来的。画作右下角还有一个神奇的签名,那也可以看成是作品的真正作者:一串算法公式。据悉,这幅作品由法国艺术团体Obvious通过精密算法、基于GAN(生成式对抗网络,GenerativeAdversarial Network)模型开发完成。至于这个“算法”,是由艺术家们首先输入了14—20世纪之间的15000张肖像画,在学习这些初始训练集之后,最终生成能“以假乱真”的作品。

将被拍卖的AI画作
一些人面带微笑地端详这幅作品,而另一些表示无法认同地皱起了眉头。这个被成为“下一场伟大艺术运动初期阶段作品”的到来,在这家全球领先的拍卖行受到了冷淡的欢迎。
据《纽约时报》报道,佳士得拍卖行希望周四能得到更热烈的反馈。届时,来自La Famille de Belamy的爱德蒙·德·贝拉米(Edmond de Belamy)将呈现在众人面前,而这意味着,艺术市场对人工智能艺术的兴趣考验,正式开始。
据悉,这是全球首幅被拍卖的AI画作,而佳士得给这幅作品的估价在7000到10000美元之间。不同于其他人物肖像画,这幅作品中没有使用颜料,也没有使用画笔。法国艺术团体“显而易见”创建了一种算法,可以模仿人类提供的一系列图像,并将14世纪至20世纪的数千幅肖像录入,让AI系统自己学习。这个人工智能系统就会开始尝试模仿创作,然后将自己创作的肖像与人类的肖像进行比较研究,直到无法区分两者为止。
然而,由AI创作的画像,真的能被称为艺术吗?哥伦比亚大学艺术史学家弗雷德里克·鲍姆加特纳表示,人工智能作品势必将引发人们对意图和作者身份的质疑。
对此,引进这幅拍卖画作的佳士得Prints & Multiples负责人理查德·劳埃德表示,引进这幅作品拍卖,一是因为自己多年来的兴趣。另外则是因为,今年早些时候便有报道,法国收藏家尼古拉斯·劳热罗·拉瑟雷,私下以约1万欧元的价格,从“显而易见”那里购买了一幅AI肖像画。而让他最感兴趣的是这件作品与天价欧洲肖像画的相似之处,他解释说:“看起来就像佳士得拍卖出去的东西一样。”
那么,能理解文化艺术的AI算法GAN是什么?
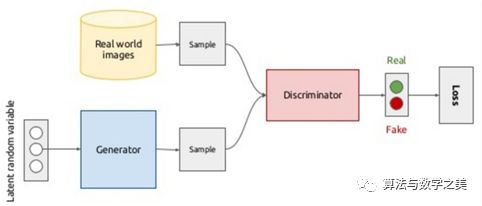
GAN就是这个样子!
GAN从出生就是别人家的算法!
2014年Ian Goodfellow提出生成对抗网络(GAN)的概念后,GAN变成为了学术界的一个火热的研究热点, Yann LeCun更是称之为”过去十年间机器学习领域最让人激动的点子”!

生成式对抗网络(GANs)之父,《麻省理工科技评论》(MIT Technology Review)“35 名 35 岁以下科技创新者”得主

Yann LeCun,将CNNs应用最成功的人,获得由IEEE计算机学会给他颁发了著名的“神经网络先锋奖”
先给大家讲一个故事,
男:哎,你看我给你拍的好不好?
女:这是什么鬼,你不能学学XXX的构图吗?
男:哦
……
男:这次你看我拍的行不行?
女:你看看你的后期,再看看YYY的后期吧,呵呵
男:哦
……
男:这次好点了吧?
女:呵呵,我看你这辈子是学不会摄影了
……
男:这次呢?
女:嗯,我拿去当头像了
上面这段对话讲述了一位“男朋友摄影师”的成长历程。很多人可能会问:这个故事和GAN有什么关系?其实,只要你能理解这段故事,就可以了解生成式对抗网络的工作原理。
首先,先介绍一下生成模型(generative model),它在机器学习的历史上一直占有举足轻重的地位。当我们拥有大量的数据,例如图像、语音、文本等,如果生成模型可以帮助我们模拟这些高维数据的分布,那么对很多应用将大有裨益。
针对数据量缺乏的场景,生成模型则可以帮助生成数据,提高数据数量,从而利用半监督学习提升学习效率。语言模型(language model)是生成模型被广泛使用的例子之一,通过合理建模,语言模型不仅可以帮助生成语言通顺的句子,还在机器翻译、聊天对话等研究领域有着广泛的辅助应用。
那么,如果有数据集S={x1,…xn},如何建立一个关于这个类型数据的生成模型呢?最简单的方法就是:假设这些数据的分布P{X}服从g(x;θ),在观测数据上通过最大化似然函数得到θ的值,即最大似然法:
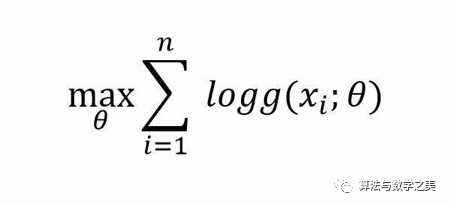
GAN的工作原理
文章开头描述的场景中有两个参与者,一个是摄影师(男生),一个是摄影师的女朋友(女生)。男生一直试图拍出像众多优秀摄影师一样的好照片,而女生一直以挑剔的眼光找出“自己男朋友”拍的照片和“别人家的男朋友”拍的照片的区别。于是两者的交流过程类似于:男生拍一些照片 ->女生分辨男生拍的照片和自己喜欢的照片的区别->男生根据反馈改进自己的技术,拍新的照片->女生根据新的照片继续提出改进意见->……,这个过程直到均衡出现:即女生不能再分辨出“自己男朋友”拍的照片和“别人家的男朋友”拍的照片的区别。
我们将视线回看到生成模型,以图像生成模型举例。假设我们有一个图片生成模型(generator),它的目标是生成一张真实的图片。与此同时我们有一个图像判别模型(discriminator),它的目标是能够正确判别一张图片是生成出来的还是真实存在的。那么如果我们把刚才的场景映射成图片生成模型和判别模型之间的博弈,就变成了如下模式:生成模型生成一些图片->判别模型学习区分生成的图片和真实图片->生成模型根据判别模型改进自己,生成新的图片->····
这个场景直至生成模型与判别模型无法提高自己——即判别模型无法判断一张图片是生成出来的还是真实的而结束,此时生成模型就会成为一个完美的模型。这种相互学习的过程听起来是不是很有趣?
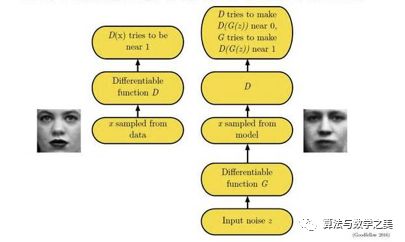
上述这种博弈式的训练过程,如果采用神经网络作为模型类型,则被称为生成式对抗网络(GAN)。用数学语言描述整个博弈过程的话,就是:假设我们的生成模型是g(z),其中z是一个随机噪声,而g将这个随机噪声转化为数据类型x,仍拿图片问题举例,这里g的输出就是一张图片。D是一个判别模型,对任何输入x,D(x)的输出是0-1范围内的一个实数,用来判断这个图片是一个真实图片的概率是多大。令Pr和Pg分别代表真实图像的分布与生成图像的分布,我们判别模型的目标函数如下:
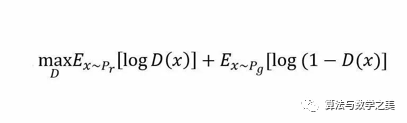
类似的生成模型的目标是让判别模型无法区分真实图片与生成图片,那么整个的优化目标函数如下:
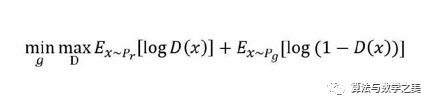
这个最大最小化目标函数如何进行优化呢?最直观的处理办法就是分别对D和g进行交互迭代,固定g,优化D,一段时间后,固定D再优化g,直到过程收敛。
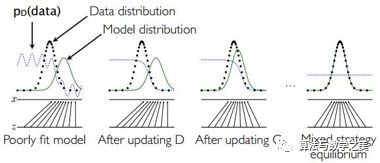
一个简单的例子如下图所示:假设在训练开始时,真实样本分布、生成样本分布以及判别模型分别是图中的黑线、绿线和蓝线。可以看出,在训练开始时,判别模型是无法很好地区分真实样本和生成样本的。接下来当我们固定生成模型,而优化判别模型时,优化结果如第二幅图所示,可以看出,这个时候判别模型已经可以较好的区分生成数据和真实数据了。第三步是固定判别模型,改进生成模型,试图让判别模型无法区分生成图片与真实图片,在这个过程中,可以看出由模型生成的图片分布与真实图片分布更加接近,这样的迭代不断进行,直到最终收敛,生成分布和真实分布重合。
GAN在图像中的应用——DCGAN
为了方便大家更好地理解生成式对抗网络的工作过程,下面介绍一个GAN的使用场景——在图片中的生成模型DCGAN。
在图像生成过程中,如何设计生成模型和判别模型呢?深度学习里,对图像分类建模,刻画图像不同层次,抽象信息表达的最有效的模型是:CNN (convolutional neural network,卷积神经网络)。
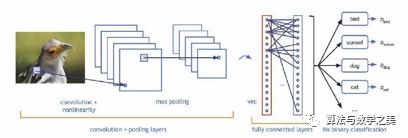
CNN是深度神经网络的一种,可以通过卷积层(convolutional layer)提取不同层级的信息,如上图所示。CNN模型以图片作为输入,以图片、类别抽象表达作为输出,如:纹理、形状等等,其实这与人类对图像的认知有相似之处,即:我们对一张照片的理解也是多层次逐渐深入的。
那么生成图像的模型应该是什么样子的呢?想想小时候上美术课,我们会先考虑构图,再勾画轮廓,然后再画细节,最后填充颜色,这事实上也是一个多层级的过程,就像是把图像理解的过程反过来,于是,人们为图像生成设计了一种类似反卷积的结构:Deep convolutional NN for GAN(DCGAN)
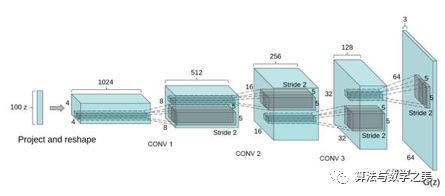
DCGAN采用一个随机噪声向量作为输入,如高斯噪声。输入通过与CNN类似但是相反的结构,将输入放大成二维数据。通过采用这种结构的生成模型和CNN结构的判别模型,DCGAN在图片生成上可以达到相当可观的效果。如下是一些生成的案例照片。
虽然画出这个价值超过7000美元的AI算法没有官宣,但是可以猜测,其使用的算法思想和图片中的生成模型DCGAN是相似的!
人工智能对围棋的攻破速度远远超出了人类的想象,它们的学习速度和效率简直惊人。仅就我们原以为AI很难理解的文化艺术领域来说,不仅仅是绘画,文学、音乐等也没有逃过AI的“技术阴影”。之前“计算机写稿”“AI随机生成歌词”等还像是小打小闹的小游戏,不过它们的进步真的远超想象。比如最近“AI算法胡言乱语写成诗”火爆社交网络,输入关键词可以随机生成诗作,居然“诗意”满满,比如“喜欢是什么做成的?太阳、花粉和所有苦涩的回忆”“我是什么做成的?孤独、惊喜和所有幸福快乐的结局”……网友感慨“成精了”“输给AI”“冰冷的机器也有温情的浪漫”!而AI作曲也不是新鲜事儿了,2016年作曲机器人Aiva就“学会了”人类高级技能的作曲。它可以从莫扎特、巴赫、贝多芬等作曲家的15000多首乐曲中学习,提取音乐特征并建立音乐理论的直觉。在视频游戏、广告、纪录片、短片和电影等领域,AI作曲已经开始运用于商业。
∑编辑 | Gemini
算数君整理
更多精彩:
☞ 曲面论

算法数学之美微信公众号欢迎赐稿
稿件涉及数学、物理、算法、计算机、编程等相关领域,经采用我们将奉上稿酬。
投稿邮箱:math_alg@163.com




