查询性能显著提升,Apache Doris 向量化版本在小米 A/B 实验场景的调优实践

导读:长期以来,Apache Doris 在小米集团都有着广泛的应用。随着小米互联网业务的快速发展,用户对 Apache Doris 的查询性能提出了更高的要求,Doris 向量化版本在小米内部上线已经迫在眉睫。在 SelectDB 公司和 Apache Doris 社区的鼎力支持下,我们在小米 A/B实验场景对 Doris 1.1.2 向量化版本进行了一系列的调优操作,使得查询性能和稳定性有了显著地提升。
2019 年 9 月,为了满足小米互联网增长分析业务中近实时、多维分析查询的需求,小米集团首次引入了Apache Doris。在过去的三年时间里,Apache Doris 已经在小米内部得到了广泛的应用,支持了集团数据看板、广告投放、广告BI、新零售、用户行为分析、A/B实验平台、天星数科、小米有品、用户画像、小米造车等小米内部数十个业务,并且在小米内部形成了一套以 Apache Doris 为核心的数据生态 。小米集团作为 Apache Doris 最早期的用户之一,一直深度参与社区建设,参与 Apache Doris 的稳定性打磨。
为了保证线上服务的稳定性,小米内部基于 Apache Doris 社区的 0.13 版本进行迭代,为小米的业务提供稳定的报表分析和 BI看板服务,经过业务的长时间打磨,内部 Doris 0.13 版本已经非常稳定。但是,随着小米互联网业务的发展,用户对 Doris 的查询性能提出了更高的要求,Doris 0.13 版本在某些场景下逐渐难以满足业务需求了。与此同时,Apache Doris 社区在快速发展,社区发布的 1.1 版本已经在计算层和存储层全面支持了向量化,查询性能相比非向量化版本有了明显地提升,基于此,小米内部的 Apache Doris 集群进行向量化版本升级势在必行。

场景介绍
小米的 A/B实验平台对 Doris 查询性能的提升有着迫切的需求,因此我们选择优先在小米的 A/B实验平台上线 Apache Doris 向量化版本,也就是 1.1.2 版本。
小米的A/B实验平台是一款通过 A/B测试的方式,借助实验分组、流量拆分与科学评估等手段来辅助完成科学的业务决策,最终实现业务增长的一款运营工具产品。在实际业务中,为了验证一个新策略的效果,通常需要准备原策略A 和新策略B 两种方案。随后在总体用户中取出一小部分,将这部分用户完全随机地分在两个组中,使两组用户在统计角度无差别。将原策略A和新策略B分别展示给不同的用户组,一段时间后,结合统计方法分析数据,得到两种策略生效后指标的变化结果,并以此来判断新策略B 是否符合预期。
图1-小米的A/B实验简介
小米的A/B实验平台有几类典型的查询应用:用户去重、指标求和、实验协方差计算等,查询类型会涉及较多的 Count(distinct)、Bitmap计算、Like语句等。

上线前验证
我们基于 Doris 1.1.2 版本搭建了一个和小米线上 Doris 0.13 版本在机器配置和机器规模上完全相同的测试集群,用于向量化版本上线前的验证。验证测试分为两个方面:单 SQL 串行查询测试和批量 SQL 并发查询测试。在这两种测试中,我们在保证两个集群数据完全相同的条件下,分别在 Doris 1.1.2 测试集群和小米线上 Doris 0.13 集群执行相同的查询 SQL 来做性能对比。我们的目标是,Doris 1.1.2 版本在小米线上 Doris 0.13 版本的基础上有 1 倍的查询性能提升。
两个集群配置完全相同,具体配置信息如下:
集群规模:3 FE + 89 BE
BE节点CPU: Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz 16核 32线程 × 2
BE节点内存:256GB
BE节点磁盘:7.3TB × 12 HDD
单 SQL 串行查询测试
在该测试场景中,我们选取了小米 A/B 实验场景中 7 个典型的查询 Case,针对每一个查询 Case,我们将扫描的数据时间范围分别限制为 1 天、7 天和 20 天进行查询测试,其中单日分区数据量级大约为 31 亿(数据量大约 2 TB),测试结果如图所示:
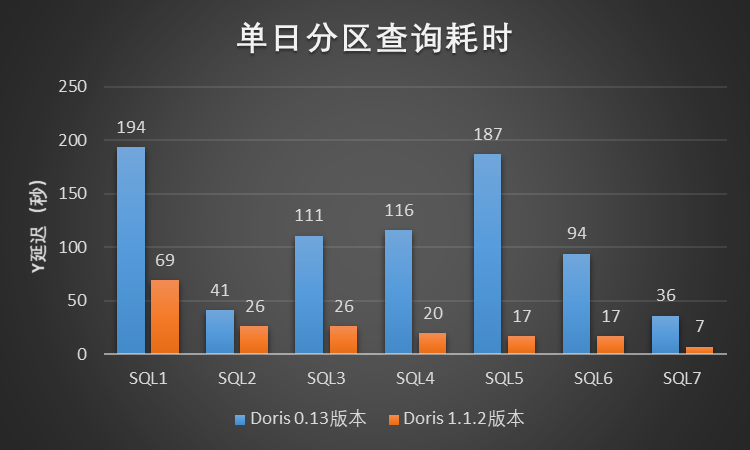
图2-单日分区查询耗时
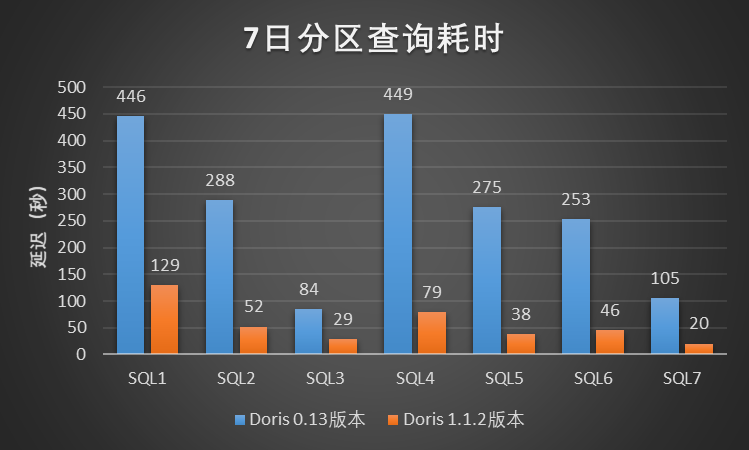
图3-7日分区查询耗时
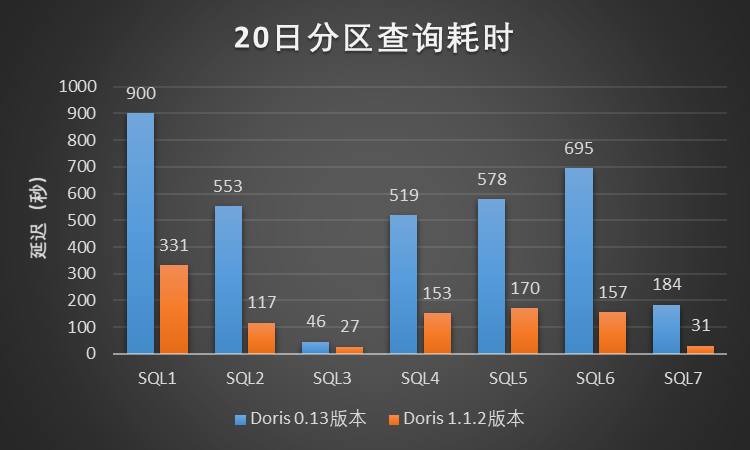
图4-20日分区查询耗时
根据以上小米A/B 实验场景下的单SQL串行查询测试结果所示,Doris 1.1.2 版本相比小米线上Doris 0.13版本至少有 3~5 倍的性能提升,效果显著,提升效果远高于预期。
批量 SQL 并发查询测试
在并发测试中,我们将小米 A/B 实验场景的查询 SQL 按照正常的业务并发分别提交到 Doris 1.1.2 测试集群和小米线上 Doris 0.13 集群,对比观察两个集群的状态和查询延迟。测试结果为,在完全相同的机器规模、机器配置和查询场景下,Doris 1.1.2 版本的查询延迟相比线上 Doris 0.13 版本整体上升了 1 倍,查询性能下降非常明显,另外,Doris 1.1.2 版本稳定性方面也存在比较严重的问题,查询过程中会有大量的查询报错。Doris 1.1.2 版本在小米A/B 实验场景并发查询测试的结果与我们的预期差别较大。并发查询测试过程中,我们遇到了几个比较严重的问题:
CPU 使用率上不去
查询下发到 Doris 1.1.2 版本所在的集群,CPU 使用率最多只能打到 50% 左右,但是完全相同的一批查询下发到线上 Doris 0.13 版本的集群,CPU使用率可以打到接近 100%。因此推测 Doris 1.1.2 版本在小米 A/B 实验场景中将机器的 CPU 利用不起来造成了查询性能大幅度降低。
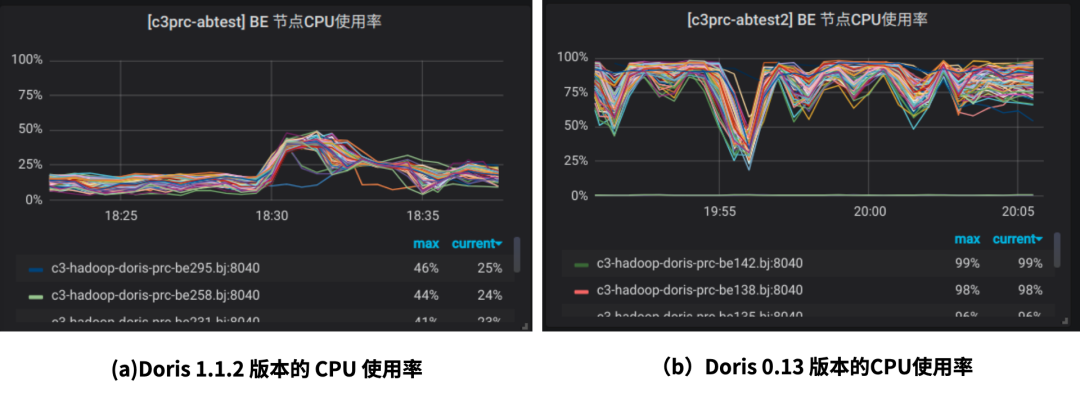
图5-Doris 1.1.2版本和Doris 0.13版本CPU使用率对比
查询持续报错
用户并发提交查询的时候会出现如下报错,后续的查询任务均无法执行,集群完全处于不可用的状态,只有重启 BE 节点才能恢复。
RpcException, msg: timeout when waiting for send fragments RPC. Wait(sec): 5, host: 10.142.86.26用户提交查询的时候也会频繁出现如下报错:
detailMessage = failed to initialize storage reader. tablet=440712.1030396814.29476aaa20a4795e-b4dbf9ac52ee56be, res=-214, backend=10.118.49.24Like 语句查询较慢
在小米 A/B实验场景有较多的使用 Like 语句进行字符串模糊匹配的查询,在并发测试过程中,该类查询普遍性能较低。
内存拷贝耗时较长
并发查询测试过程中,SQL 整体执行较慢,通过抓取查询过程中的 CPU 火焰图,发现读取字符串类型数据的时候内存拷贝会占用较多时间。
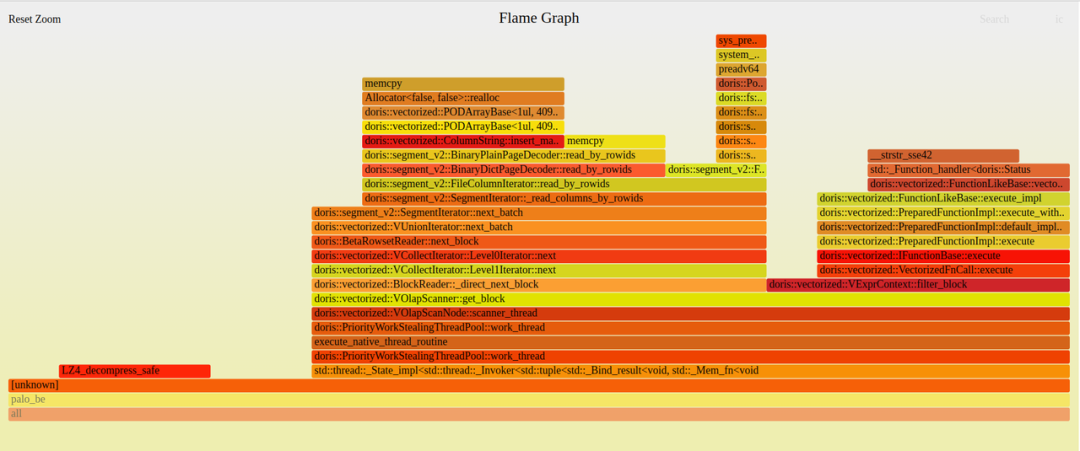
图6-CPU火焰图

调优实践
为了解决 Doris 1.1.2 版本在小米 A/B实验场景并发测试过程中暴露出的性能和稳定性问题,推动 Doris 向量化版本尽快在小米 A/B实验平台上线,我们和 SelectDB 公司以及 Apache Doris 社区一起对 Doris 1.1.2 版本进行了一系列的调优工作。
提升 CPU 使用率
针对并发查询时 CPU 使用率上不去的问题,我们截取了查询过程中BE进程的函数调用栈,通过分析发现,有较多的内存分配和释放操作在等锁,这可能会造成 CPU 使用率上不去。
函数调用栈
...
...
Doris 内存管理机制
Doris 中使用 TCMalloc 进行内存管理。根据所分配和释放内存的大小,TCMalloc 将内存分配策略分为小内存管理和大内存管理两类。
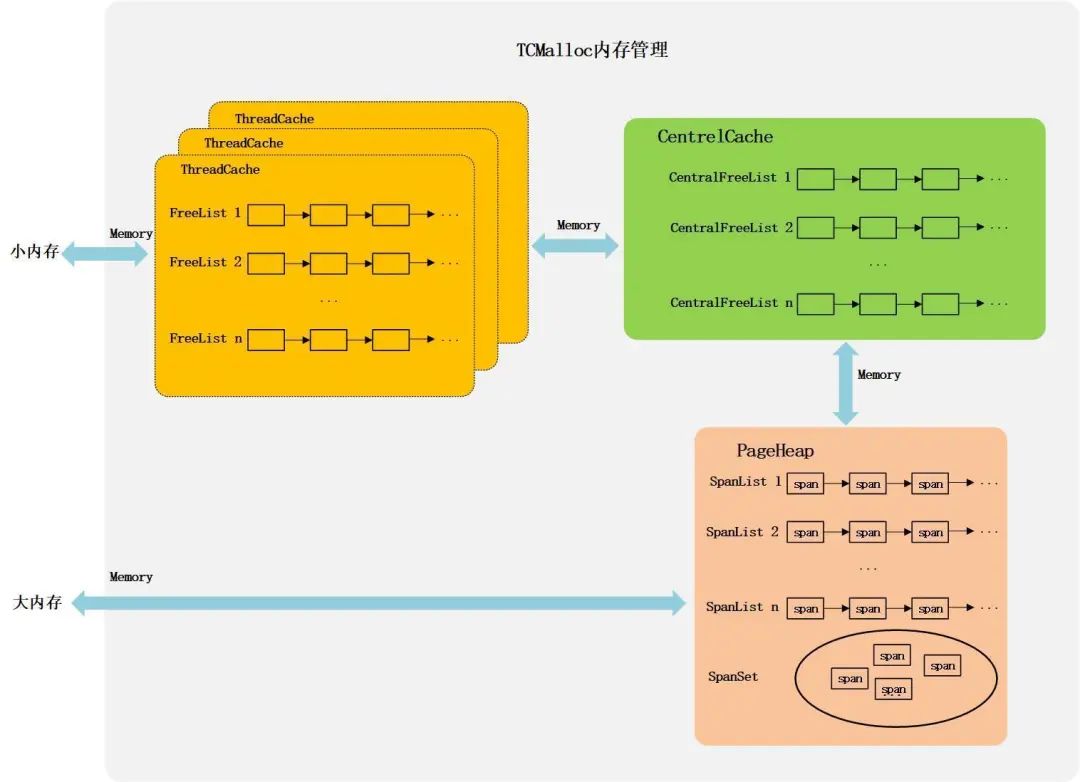
图7-TCMalloc内存管理机制
(1)小内存管理
TCMalloc 使用了 ThreadCache、CentralCache 和 PageHeap 三层缓存来管理小内存的分配和释放。
对于每个线程,TCMalloc 都为其单独维护了一个 ThreadCache,每个 ThreadCache 中包含了多个单独的 FreeList,每个 FreeList 中缓存了 N 个固定大小的可供分配的内存单元。进行小内存分配时,会直接从 ThreadCache 中进行内存分配,相应地,小内存的回收也是将空闲内存重新放回 ThreadCache 中对应的 FreeList 中。由于每个线程都有自己独立的 ThreadCache,因此从 ThreadCache 中分配或回收内存是不需要加锁的,可以提升内存管理效率。
内存分配时,如果 ThreadCache 中对应的 FreeList 为空,则需要从 CertralCache 中获取内存来补充自身的 FreeList。CentralCache 中维护了多个 CentralFreeList 链表来缓存不同大小的空闲内存,供各线程的 ThreadCache 取用。由于 CentralCache 是所有线程共用的,因此 ThreadCache 从 CentralCache 中取用或放回内存时是需要加锁的。为了减小锁操作的开销,ThreadCache 一般从 CentralCache 中一次性申请或放回多个空闲内存单元。
当 CentralCache 中对应的 CentralFreeList 为空时,CentralCache 会向 PageHeap 申请一块内存,并将其拆分成一系列小的内存单元,添加到对应的 CentralFreeList 中。PageHeap 用来处理向操作系统申请或释放内存相关的操作,并提供了一层缓存。PageHeap 中的缓存部分会以 Page 为单位、并将不同数量的 Page 组合成不同大小的 Span,分别存储在不同的 SpanList 中,过大的 Span 会存储在一个 SpanSet 中。CentralCache 从 PageHeap 中获取的内存可能来自 PageHeap 的缓存,也可能是来自 PageHeap 向系统申请的新内存。
(2)大内存管理
大内存的分配和释放直接通过 PageHeap 来实现,分配的内存可能来自 PageHeap 的缓存,也可能来自 PageHeap 向系统申请的新内存。PageHeap 向系统申请或释放内存时需要加锁。
TCMalloc 中的 aggressive_memory_decommit 参数用来配置是否会积极释放内存给操作系统。当设置为 true 时,PageHeap 会积极地将空闲内存释放给操作系统,节约系统内存;当该配置设置为 false 时,PageHeap 会更多地将空闲内存进行缓存,可以提升内存分配效率,不过会占用更多的系统内存;在 Doris 中该参数默认为 true。
通过分析查询过程中的调用栈发现,有比较多的线程卡在 PageHeap 向系统申请或释放内存的等锁阶段,因此,我们尝试将 aggressive_memory_decommit 参数设为false,让 PageHeap 对空闲内存进行更多的缓存。果然,调整完成之后,CPU 使用率可以打到几乎 100%。在 Doris 1.1.2 版本,数据在内存中采用列式存储,因此,会相比于 Doris 0.13 版本行存的方式有更大的内存管理开销。
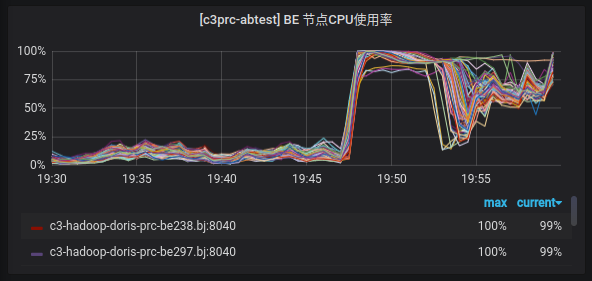
图8-调优后Doris 1.1.2测试集群的CPU使用率
社区相关的PR:https://github.com/apache/doris/pull/12427
缓解 FE 下发 Fragment 超时的问题
在 Doris 1.1.2 版本,如果一个查询任务的 Fragment 数量超过一个,查询计划就会采用两阶段执行(Two Phase Execution)策略。在第一阶段,FE 会下发所有的 Fragment 到 BE 节点,在 BE 上对 Fragment 执行相应的准备工作,确保 Fragment 已经准备好处理数据;当 Fragment 完成准备工作,线程就会进入休眠状态。在第二阶段,FE 会再次通过 RPC 向 BE 下发执行 Fragment 的指令,BE 收到执行 Fragment 的指令后,会唤醒正在休眠的的线程,正式执行查询计划。
RpcException, msg: timeout when waiting for send fragments RPC. Wait(sec): 5, host: 10.142.86.26在用户执行查询时,会持续有上面的报错,并导致任何查询无法执行。通过截取进程的调用栈,分析发现大量的线程均在休眠状态,均阻塞在 Fragment 完成准备工作并休眠等待被唤醒的状态。排查发现,查询计划的两阶段执行机制中存在 Bug,如果执行计划被FE取消,BE 上已经完成 Fragment 准备工作并休眠等待的线程就不会被唤醒,导致 BE 上的 Fragment 线程池被耗尽,后续所有查询任务的 Fragment 下发到 BE 节点之后,因为没有线程资源都会等待直到 RPC 超时。
为了解决这个问题,我们从社区引入了相关的修复 Patch,为休眠的线程增加了超时唤醒机制,如果线程被超时唤醒,Fragment 会被取消,进而释放线程资源,极大地缓解了 FE 下发执行计划时 RPC 超时的问题。
该问题还未完全解决,当查询并发很大时还会偶发地出现。另外,我们还引入了 Doris 社区相关的其他 Patch 来缓解该问题,比如:减小执行计划的 Thrift Size,以及使用池化的 RPC Stub 替换单一的 RPC Stub 。
社区相关的PR如下:
https://github.com/apache/doris/pull/12392
https://github.com/apache/doris/pull/12495
https://github.com/apache/doris/pull/12459
修复 Tablet 元数据汇报的 Bug
在 Doris 中,BE 会周期性地检查当前节点上所有 Tablet 是否存在版本缺失,并向 FE 汇报所有 Tablet 的状态和元信息,由 FE 对每一个 Tablet 的三副本进行对比,确认其中的异常副本,并下发 Clone 任务,通过 Clone 正常副本的数据文件来恢复异常副本缺失的版本。
detailMessage = failed to initialize storage reader. tablet=440712.1030396814.29476aaa20a4795e-b4dbf9ac52ee56be, res=-214, backend=10.118.49.24在该报错信息中,错误代码res=-214 (OLAP_ERR_VERSION_NOT_EXIST)表示查询计划执行过程中在 BE 上初始化 Rowset Reader 的时候出现异常,对应的数据版本不存在。在正常情况下,如果 Tablet 的某一个副本存在版本缺失,FE 生成执行计划的时候就不会让查询落在该副本上,然而,查询计划在 BE 上执行的过程中却发现版本不存在,则说明 FE 并没有检测到该副本存在版本缺失。
通过排查代码发现,BE 的 Tablet 汇报机制存在 Bug,当某一个副本存在版本缺失时,BE 并没有将这种情况正常汇报给 FE,导致这些存在版本缺失的异常副本并没有被 FE 检测到,因此不会下发副本修复任务,最终导致查询过程中会发生res=-214的报错。
社区相关的 PR 如下:
https://github.com/apache/doris/pull/12415
优化 Like 语句性能
在 Doris 1.1.2 版本中使用 Like 语句进行字符串模糊匹配查询时,Doris 底层其实是使用了标准库中的std::search()函数对存储层读出的数据进行逐行匹配,过滤掉不满足要求的数据行,完成 Like 语句的模糊匹配。通过调研和对比测试发现,GLIBC 库中的std::strstr()函数针对字符串匹配比std::search()函数有 1 倍以上的性能提升。最终我们使用std::strstr()函数作为 Doris 底层的字符串匹配算法,将 Doris 底层字符串匹配的性能可以提升 1 倍。
优化内存拷贝
在小米的场景中有很多字符串类型的查询字段,Doris 1.1.2 版本使用 ColumnString 对象来存储内存中的一列字符串数据,底层使用了 PODArray 结构来实际存储字符串。执行查询时,需要从存储层逐行读取字符串数据,在这个过程中需要多次对 PODArray 执行 Resize 操作来为列数据申请更大的存储空间,执行 Resize 操作会引起对已经读取的字符串数据执行内存拷贝,而查询过程中的内存拷贝非常耗时,对查询性能影响极大。
为了降低字符串查询过程中内存拷贝的开销,我们需要尽量减少对 PODArray 执行 Resize 操作的次数。鉴于小米 A/B实验场景中同一列不同行的字符串长度相对比较均匀,我们尝试预先为需要读取的字符串申请足够的内存来减少 Resize 的次数,进而降低内存拷贝的开销。在数据扫描时,每个 Batch 需要读取的数据行数是确定的(假设为 n),当字符串数据读取完指定的前 m(在小米的场景中,该值配置为100,m < n)行时,我们根据前 m 行的 PODArray 大小预估所有 n 行字符串数据需要的 PODArray 大小,并为其提前申请内存,避免后面逐行读取时多次执行内存申请和内存拷贝。
内存预估公式为:
所需PODArray总大小 = (当前PODArray总大小 / m)* n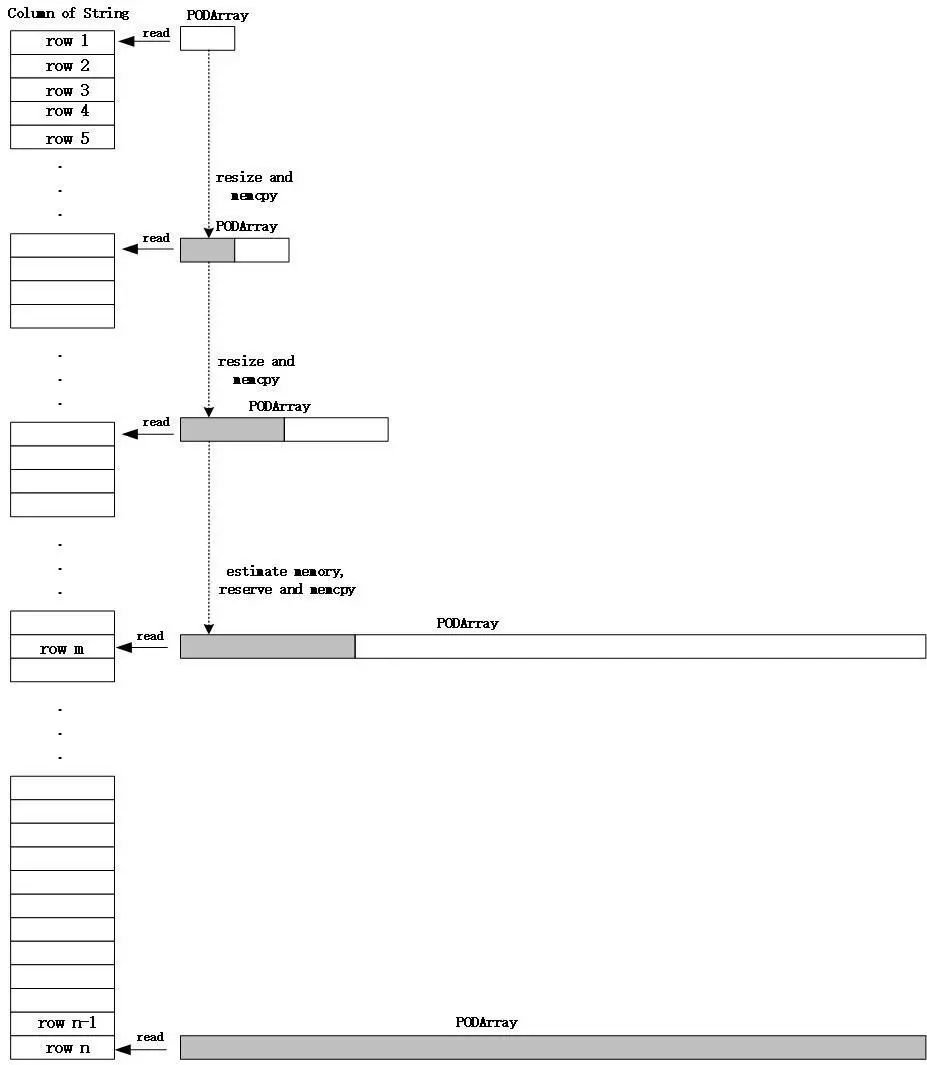
图9-优化内存拷贝开销
当然,该方法只是对所需的内存进行了预估,根据预估的大小提前申请了内存,减少了后面逐行读取字符串时大量的 Resize 操作,减少了内存申请和内存拷贝的次数,并不能完全消除字符串读取过程中的内存拷贝。该优化方案只对一列中字符串长度比较均匀的情况有效,内存的预估相对会比较接近实际内存。如果一列中字符串长度差别较大,该方法的效果可能不甚明显,甚至可能会造成内存浪费。

调优测试结果
我们基于小米的 A/B实验场景对 Doris 1.1.2 版本进行了一系列调优,并将调优后的 Doris 1.1.2 版本与小米线上 Doris 0.13 版本分别进行了并发查询测试。测试情况如下:
测试1
我们选择了 A/B 实验场景中一批典型的用户去重、指标求和以及协方差计算的查询 Case(SQL 总数量为 3245)对两个版本进行并发查询测试,测试表的单日分区数据大约为 31 亿(数据量大约 2 TB),查询的数据范围会覆盖最近一周的分区。测试结果如图所示,Doris 1.1.2 版本相比 Doris0.13版本,总体的平均延迟降低了大约 48%,P95 延迟降低了大约 49%。在该测试中,Doris 1.1.2 版本相比 Doris0.13 版本的查询性能提升了接近 1 倍。
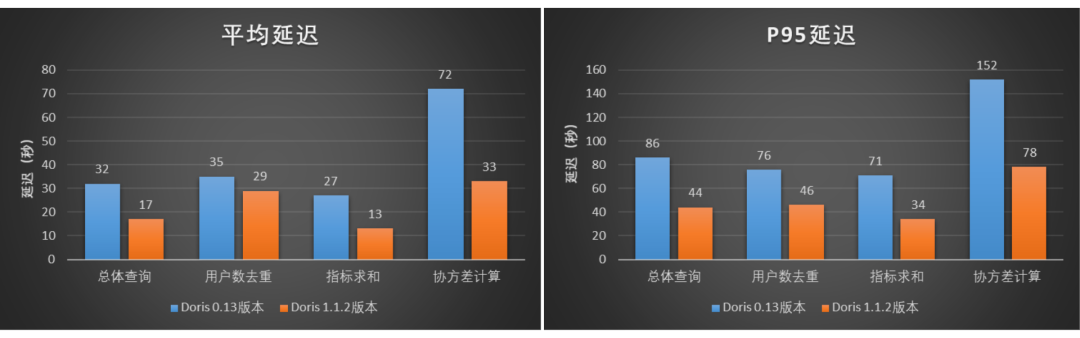
图10-查询平均延迟和P95延迟
测试2
我们选择了 A/B实验场景下的 7 份 A/B 实验报告对两个版本进行测试,每份 A/B 实验报告对应小米 A/B实验平台页面的两个模块,每个模块对应数百或数千条查询 SQL。每一份实验报告都以相同的并发向两个版本所在的集群提交查询任务。测试结果如图所示,Doris 1.1.2 版本相比 Doris 0.13 版本,总体的平均延迟降低了大约 52%。在该测试中,Doris 1.1.2 版本相比 Doris 0.13 版本的查询性能提升了超过 1 倍。
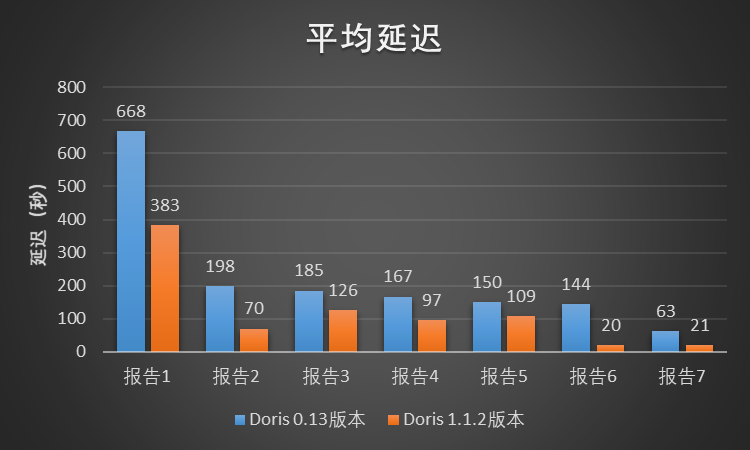
图11-查询平均延迟
测试3
为了验证调优后的 Doris 1.1.2 版本在小米 A/B 实验场景之外的性能表现,我们选取了小米用户行为分析场景进行了 Doris 1.1.2 版本和 Doris 0.13 版本的并发查询性能测试。我们选取了 2022年10月24日、25日、26日和 27日这 4 天的小米线上真实的行为分析查询 Case 进行对比查询,测试结果如图所示,Doris 1.1.2 版本相比 Doris 0.13 版本,总体的平均延迟降低了大约7 7%,P95 延迟降低了大约 83%。在该测试中,Doris 1.1.2 版本相比 Doris 0.13 版本的查询性能有 4~6 倍的提升。
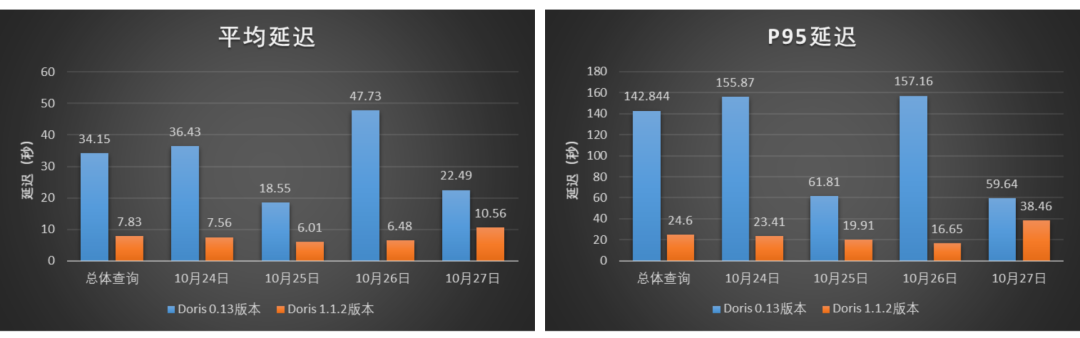
图12-查询平均延迟和P95延迟

结束语
经过一个多月的性能调优和测试,Apache Doris 1.1.2 版本在查询性能和稳定性方面已经达到了小米 A/B 实验平台的上线要求,在某些场景下的查询性能甚至超过了我们的预期,希望本次分享可以给有需要的朋友一些可借鉴的经验参考。
最后,感谢 SelectDB 公司和 Apache Doris 社区对我们的鼎力支持,感谢衣国垒老师在我们版本调优和测试过程中的全程参与和陪伴。Apache Doris 目前已经在小米集团内部得到了广泛地应用,并且业务还再持续增长,未来一段时间我们将逐步推动小米内部其他的 Apache Doris 业务上线向量化版本。
☞Meta否认扎克伯格明年辞任CEO;著名黑客成推特实习生;Windows 8.1明年1月10日停止支持|极客头条
☞
十年 Python 程序员,初次尝试 Rust:“非常优秀!”
☞刘强东发布京东全员信:2000+位高管降薪,公司出资 100 亿提升 54 万员工福利!




