论文导读 | 通过网络结构迁移学习提高图像识别任务的拓展性

更多干货文章请关注微信公众号"AI 前线",ID:"ai-front"
深度学习发展日新月异!几个月前 Zoph 和他的同事们刚刚发布了 Neural architecture search with reinforcement learning。证明了就像基于学习的特征选择比人工设计的效果更好一样,在神经网络结构设计上,学习算法效果也超过了人工。但通过学习获得网络结构美中不足在于,为每个实验训练一个模型的整体计算量非常大。
就在短短几个月后,他们又发布了新的工作成果,展示了如何将模型结构学习的搜索时间显著降低(比如,训练 CIFAR-10 数据集的时间从 4 周降到 4 天),以及在小的问题空间(比如 CIFAR-10)上应用的网络结构搜索是如何被迁移到更大的数据集(ImageNet)上的。以上两者的结合,为我们提供了在大规模问题上进行神经网络的卷积单元 / 网络结构学习的新思路。
别误会,我们所讨论的方法依然需要大量算力——从使用 450 块 GPU 支持的资源池中采样出 20,000 个子模型之后,通过完整地训练其中最优的 250 个子模型,来确定 CIFAR-10 数据集上的最优结构。但我仍旧认为这是一个巨大的进步,因为在模型构建任务中,我们永远无法绕过如何更好地构建子模块这个问题。
以 CIFAR-10 上习得的最优的卷积单元设计为例, 作者将其移植到了 ImageNet 上,并取得了最高水平的准确率——82.3% 的准确率和 96.0% 的前 5 召回率。比人工设计模型的结果好了 0.8 个百分点,但选择模型的过程至少需要九百万次浮点运算!
而且,在模型的计算量数量级相同的情况下(都为三百万),一个资源限制下的移动平台版本,仅使用了三分之一的训练时间,就取得了最高水平结果。
这是否意味着人类专家的工作边界将从设计具体任务学习系统,退到设计元任务学习系统呢?
我们的研究成果会为迁移学习和元知识学习领域带来重大影响,这是第一次将元知识学习应用于大规模问题,并获得最优水平结果的尝试。这项工作同时也表明,不仅仅模型参数,网络结构也可以作为跨模型迁移的客体。
这篇文章中描述的方法基于神经网络结构搜索(Neural Architecture Search),可以回顾下 作者之前的文章,下文中会提到其中几个要点。
在神经网络体系结构搜索(NAS)中,如下图,RNN 控制器(The Controller)会从搜索空间(S)中采样网络结构(A),训练该模型直到收敛,并使用结果(R)更新控制器以优化搜索。
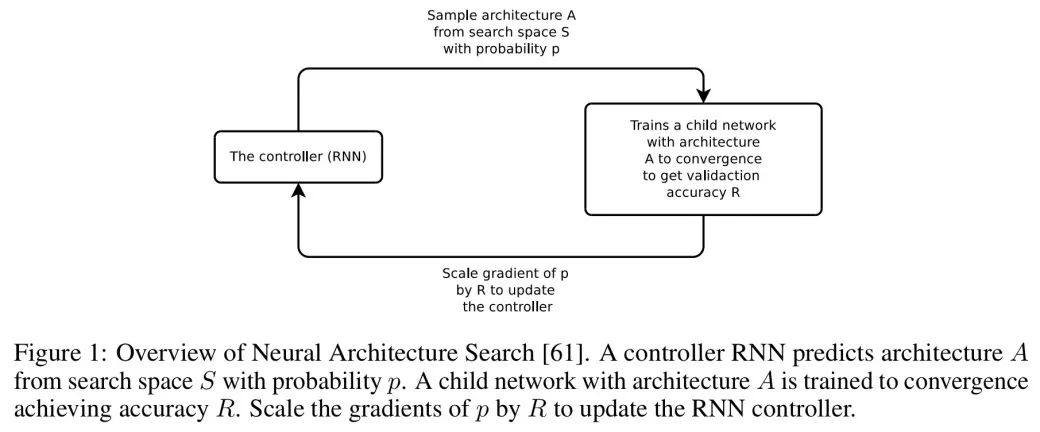
网络结构搜索的关键概念是设计模型搜索空间 S,从而针对不同问题,生成复杂度和空间尺度不同的模型。我们观察到,直接在 ImageNet 模型上应用 NAS 完成计算需要月余,代价昂贵。然而,如果妥善设计搜索空间,结构要素就可在数据集间迁移。
作者观察到,成功的卷积神经网络设计,总是将基本组件重复组合,并精心设计连接。(当然,如果你读过足够多的论文,你也会有同感的)那么,如果我们对搜索空间加以限制,只寻找好的卷积单元设计,并通过其简单叠加,使之能够处理任意空间维度和滤波器深度的输入,效果会如何呢?
事实证明,我们只需要设计两种卷积单元: 一种标准单元(Normal Cell),它接受一定维度的输入,并输出相同维度的特征图,以及一种降维单元(Reduction Cell),它输出的特征图长宽都是输入的一半。
在 CIFAR-10 和 ImageNet 上,我们将把这些单元以如下方式叠加组合:
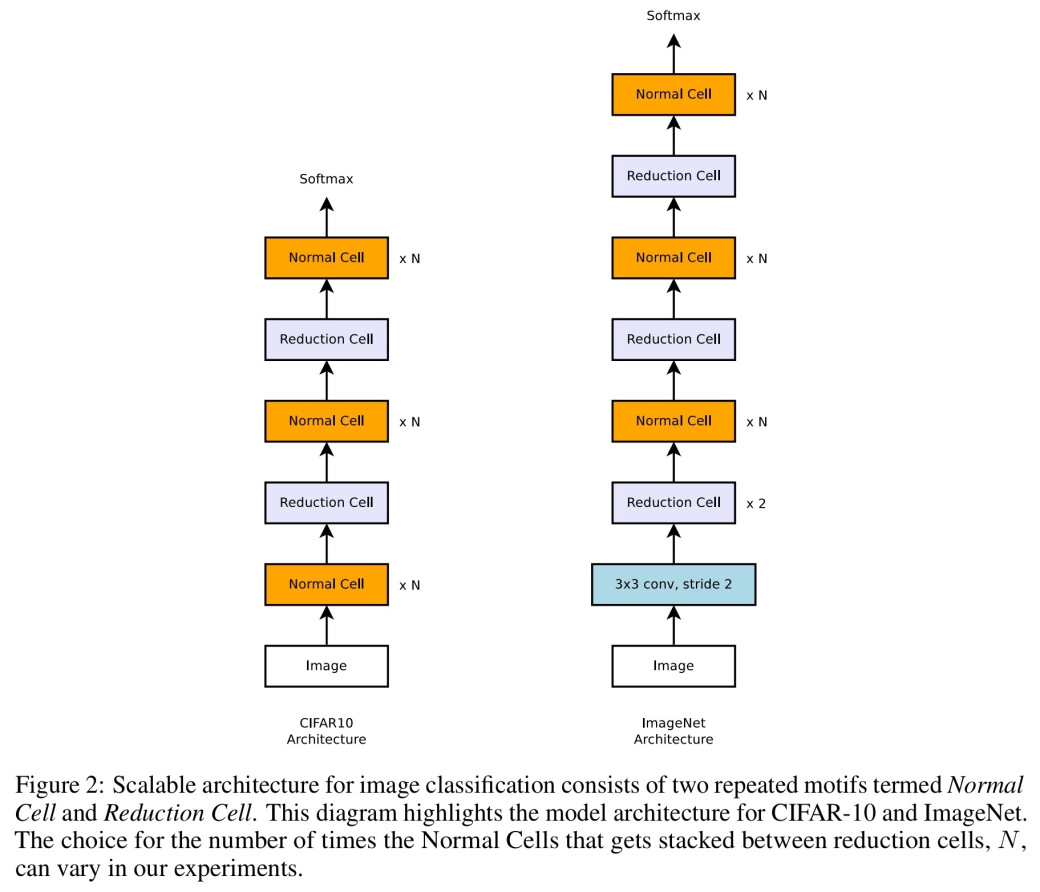
因此,相比于对整个网络结构进行预测的传统 NAS,我们设计了整个神经网络结构的上层建筑,只需通过搜索构造所需的两个基础模块。
如果这是芝麻街(译者注:Sesame Street,美国的一档儿童学前教育电视节目)的演播现场,卷积单元设计流程应该用数字“5”引出。
每个单元由B=5个模块构造,并接受前两个更低的层 / 图片的输出作为输入。在每个块中,控制器通过 5 个独立的 softmax 分类起进行了 5 步预测,这 5 个决策可以构造出单元的结构。B=5 是历次实验结果中最优的,并非穷尽所有检索项后的选择。
下面是确定一个模块的图示,图中使用手绘箭头将预测步骤和网络结构一一对应:
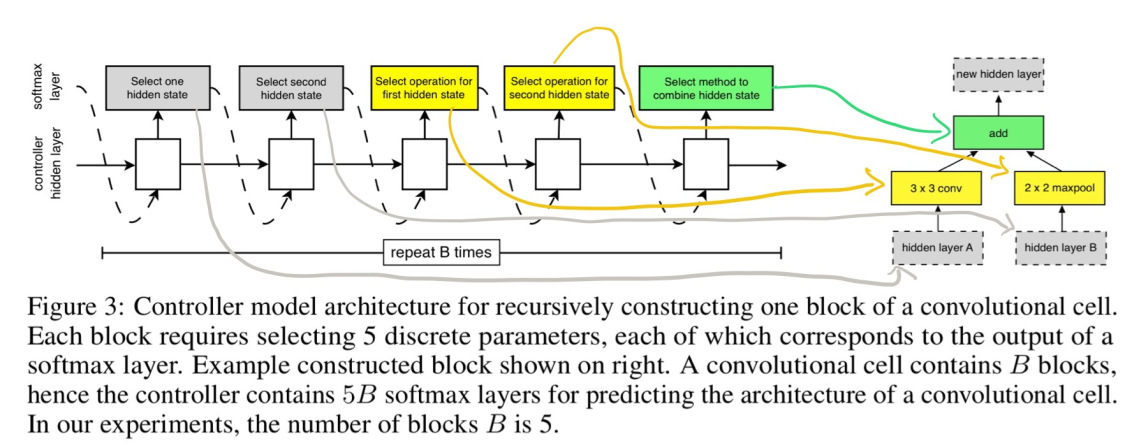
五个检索步骤如下:
从 H 或者先前卷积单元输出的隐层中选择第一个隐层。
从之前的所有隐层中,选择第二个隐层。
选择一个运算应用于第一步选择的隐层。
选择一个运算应用于第二步选择的隐层。
选择一种将第三四步运算的输出结合构建为一个新的隐层的方法。可以是逐元素加法,或沿滤波器方向拼接。所有未使用的单元生成的隐藏状态都会被拼接起来作为最终单元的输出。
第 3-4 步中运算的选择范围是一个按照 CNN 场景下各运算使用率高低决定的备选菜单,如下:
不变单元
1×3 和 3×1 卷积
1×7 和 7×1 卷积
3×3 平均池化
3×3,5×5 和 7×7 最大值池化
1×1 和 3×3 卷积
3×3 空洞 (扩张) 卷积
3×3,5×5 和 7×7 可分离卷积
为了使 rnn 控制器同时预测标准单元和降维单元,我们直接将控制器的预测步骤设置为
B=2*5,前 5 步预测标准单元,后 5 步预测降维单元。
使用 RNN 控制器按照近似策略优化 20,000 个模块后,表现最优的模块是这样的:
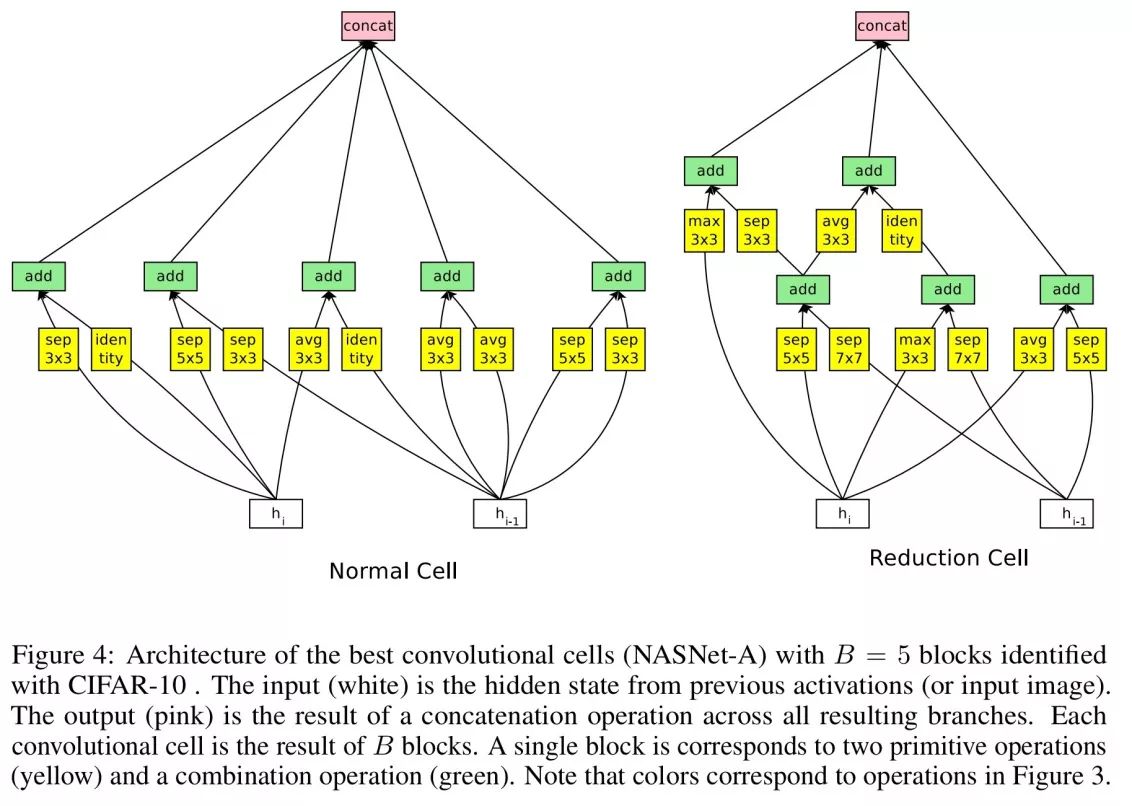
注意,这个设计中 可分离卷积 运算数目远超过常见模型。
在完成模块选择后,为最终构建用于任务的网络,还有几个参数需要考虑:(1) 单元重复的次数 N,(2) 初始化卷积单元的滤波器数目。当步长为 2 时,我们用一个常见方法启发式地加倍滤波器数目。
下表中给出了将 N 值(每层中单元重复次数)设为 4 或 6,并使用了习得的模块构建的模型,以及其对比模型,在 CIFAR-10 上训练 600 次迭代后的效果和单幅图片预测的模型运算量。其中效果最好是NASNet-A,只有Shake-Shake 26 2x96d能够在准确度上超过它,但参数多了一个数量级。
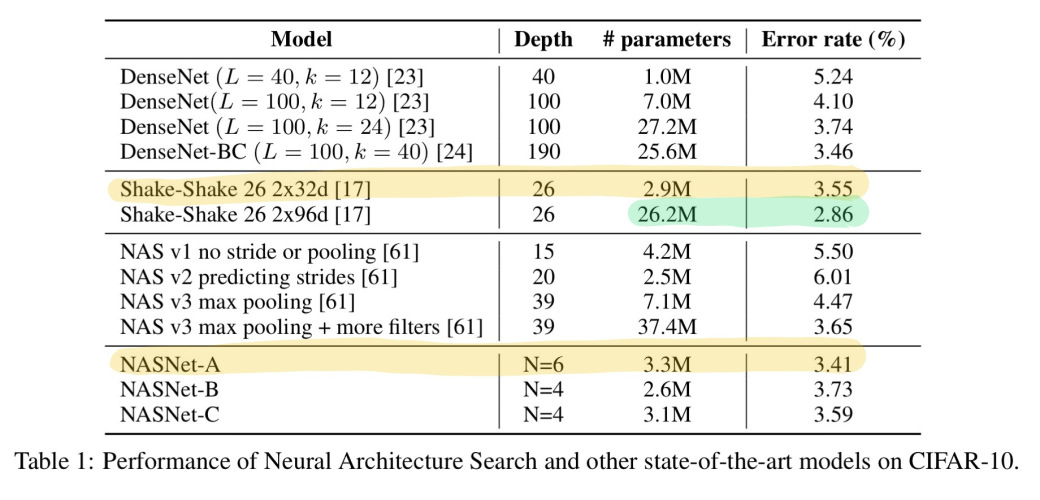
将在 CIFAR-10 上习得的模块迁移到 ImageNet 时,我们得到了非常有趣的结果。
每个基于卷积单元构建的模型都超过了同等参数量级的人工设计的模型.更重要的是,最大体量的模型更新了 ImageNet 上单一非集成预测的历史最高水平(达到 82.3%),超过历史记录 0.8 个百分点。
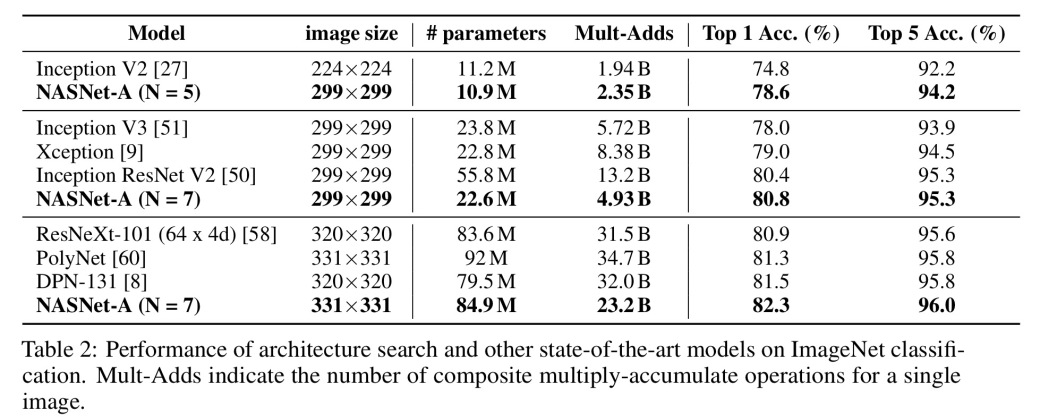
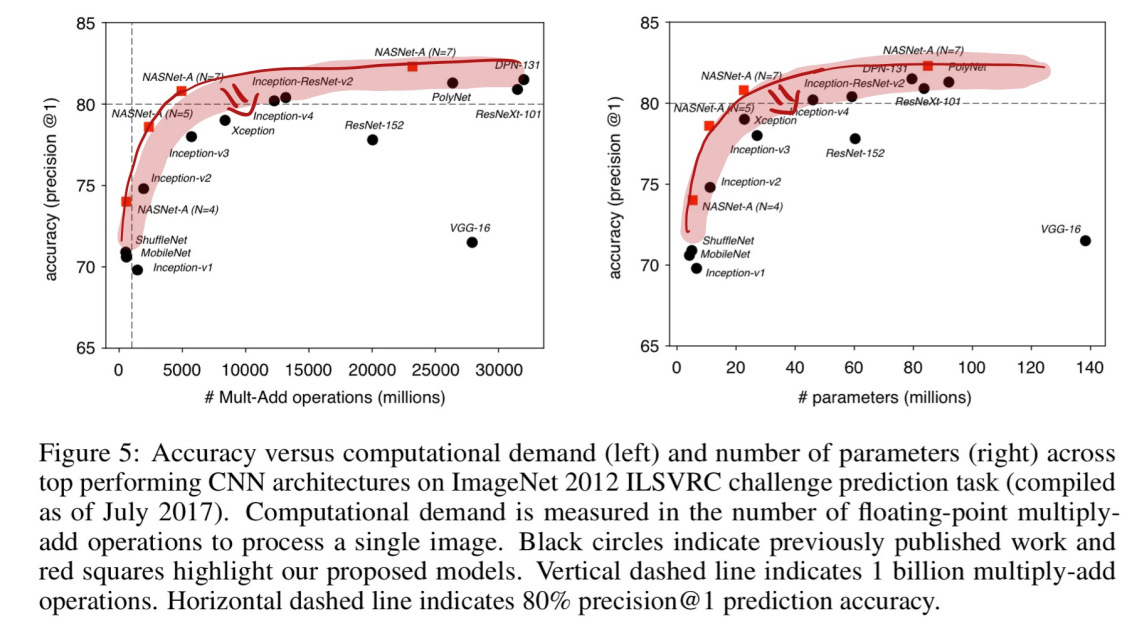
如果将自 2012 年以来 ImageNet 上的冠军算法,以及这篇论文中模型的预测精确度,按计算量整理并展示在折线图中,就能发现在同等计算量下,使用所习得模块的模型效果总是更好。
在资源限制(比如,移动平台计算)情况下的 ImageNet 分类问题上,习得模块在相同计算量下,精确率也超过了历史最高水平.
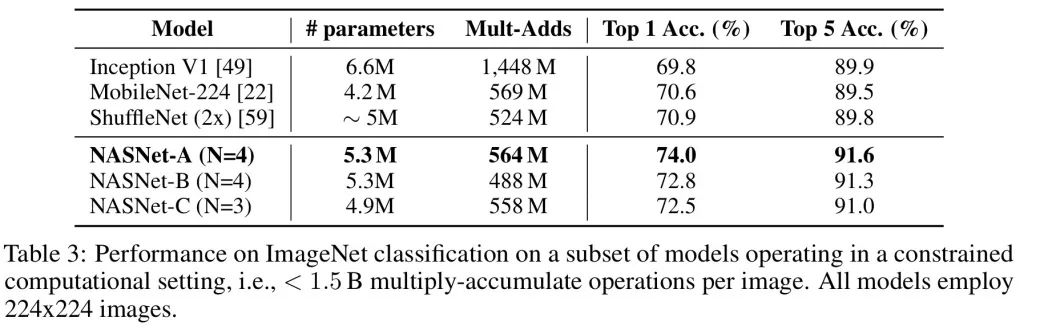
总之,我们发现习得的卷积单元适用于不同体量的模型,并且在计算量提高两个数量级时,由习得模块组成的模型能够创造最高水平结果.
阅读英文原文:
https://blog.acolyer.org/2017/09/11/learning-transferable-architectures-for-scalable-image-recognition/
论文原文地址:
https://arxiv.org/abs/1707.07012




