剑指TensorFlow,PyTorch Hub官方模型库一行代码复现主流模型
选自PyTorch
机器之心编译
参与:思源、一鸣
经典预训练模型、新型前沿研究模型是不是比较难调用?PyTorch 团队今天发布了模型调用神器 PyTorch Hub,只需一行代码,BERT、GPT、PGAN 等最新模型都能玩起来。
项目地址:https://pytorch.org/hub
机器学习领域,可复现性是一项重要的需求。但是,许多机器学习出版成果难以复现,甚至无法复现。随着数量上逐年增长的出版成果,包括数以万计的 arXiv 文章和大会投稿,对于研究的可复现性比以往更加重要了。虽然许多研究都附带了代码和训练模型,尽管他们对使用者有所帮助,但仍然需要使用者自己去研究如何使用。
今天,PyTorch 团队发布了 PyTorch Hub,一个简单的 API 和工作流代码库,它为机器学习研究的复现提供了基础构建单元。PyTorch Hub 包括预训练模型库,专门用来帮助研究的复现、协助新研究的开展。它同时内置支持 Colab,集成 Papers With Code 网站,并已经有广泛的一套预训练模型,包括分类器、分割器、生成器和 Transformer 等等。
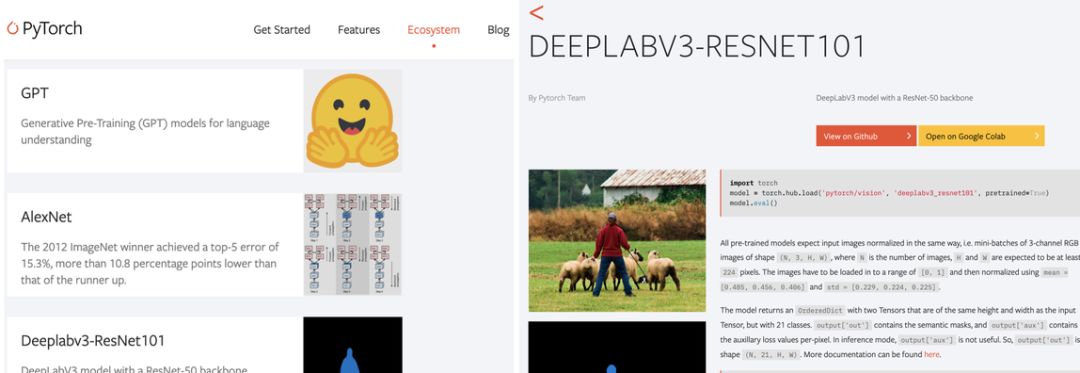
研究者发布模型
PyTorch Hub 支持在 GitHub 上发布预训练模型(定义模型结构和预训练权重),这只需要增加一个简单的 hubconf.py 文件。该文件会列举所支持的模型,以及模型需要的依赖项。
用户可以从以下代码仓库找到使用案例:
https://github.com/pytorch/vision/blob/master/hubconf.py
https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/hubconf.py
https://github.com/facebookresearch/pytorch_GAN_zoo
现在,我们可以看看最简单的案例,torchvision 的 hubconf.py:

在 torchvision,模型有以下几部分:
每个模型文件都可以独立的执行
这些模型不依赖 PyTorch 以外的包(在 hubconf.py 中以及集成了相关依赖:dependencies['torch'])
这些模型不需要单独的模型入口(entry-point),因为这些模型一经创建,就可以无缝地提取使用
减少包的依赖可以减少用户导入模型时出现的各种问题,而且这种导入可能只是临时的调用。一个直观的例子是 HuggingFace's BERT 模型。其 hubconf.py 文件如下:
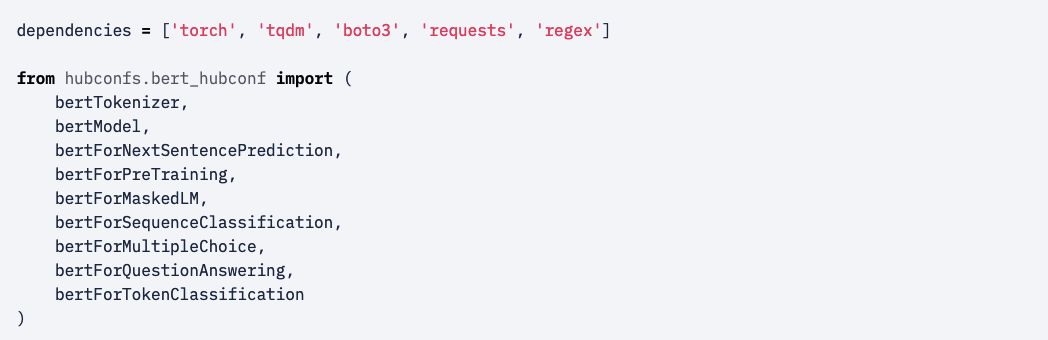
每个模型都需要创建一个模型入口,以下指定了 bertForMaskedLM 模型入口,并希望获得预训练模型权重:

这些入口可以作为复杂模型的包装器,我们能提供注释文档或额外的帮助函数。最后,有了 hubconf.py,研究者就能发送 pull 请求。当 PyTorch 接受了该请求后,研究者的模型就会出现在 PyTorch Hub 页面上。
用户工作流
PyTorch Hub 允许用户只用简单的几步就完成很多任务,例如 1)探索可用模型;2)加载预训练模型;3)理解加载模型的方法与运行参数。下面让我们通过一些案例体会体会 PyTorch Hub 的便捷吧。
探索可用模型
我们可以使用 torch.hub.list() API 查看仓库内所有可用的模型。

注意,PyTorch 还允许使用预训练模型之外的辅助模块,例如使用 bertTokenizer 来完成 BERT 模型的预处理过程,它们都会使工作流更加顺畅。
加载模型
现在我们已经知道有哪些预训练模型,下面就可以使用 torch.hub.load() API 加载这些模型了。使用 API 加载模型时,它只需要一行命令,而不需要额外安装 wheel。另外,torch.hub.help() API 也能提供一些有用的信息来帮助演示如何使用预训练模型。

其实这些预训练模型会经常更新,不论是修复 Bug 还是提升性能。而 PyTorch Hub 令用户可以极其简单地获取最后的更新版:

PyTorch 团队相信这个特性能帮助预训练模型的拥有者减轻负担,即重复发布包的成本会降低,他们也能更加专注于研究(预训练模型)本身。此外,该特性对用户也有很大优势,我们可以快速获得最新的预训练模型。
另一方面,稳定性对于用户而言非常重要。因此,模型提供者能以特定的分支或 Tag 为用户提供支持,而不直接在 master 分支上提供。这种方式能确保代码的稳定性,例如 pytorch_GAN_zoo 可以用 hub 分支来支持对其模型的使用。

注意传递到 hub.load() 中的 args 和 kwargs,它们都用于实例化模型。在上面的例子中,pretrained=True 和 useGPU=False 都被赋予不同的预训练模型。
探索已加载模型
当我们从 PyTorch Hub 中加载了模型时,我们能从以下工作流探索可用的方法,并更好地理解运行它们需要什么样的参数。
dir(model) 方法可以查看模型的所有方法,下面我们可以看看 bertForMaskedLM 模型的可用方法。

help(model.forward) 方法将提供要令模型能正常跑,其所需要的参数。
下面提供了 BERT 和 DeepLabV3 两个例子,我们可以看看这些模型加载后都能怎样使用。
BERT:https://pytorch.org/hub/huggingface_pytorch-pretrained-bert_bert/
DeepLabV3:https://pytorch.org/hub/pytorch_vision_deeplabv3_resnet101/
PyTorch Hub 中的可用模型同样支持 Colab,它们都会连接到 Papers With Code 网站。
TensorFlow 和 PyTorch 你选谁?
此前 TensorFlow 也发布了 TensorFlow Hub,它同样用于发布、探索和使用机器学习模型中可复用的部分。最近关注便捷性的 TensorFlow 2.0 Beta 也已经发布,但很多读者还是倾向于使用 PyTorch。既然这两大框架越来越「相似」,那么我们到底该使用哪个?下面机器之心简要总结了这两个深度学习框架的发展历程,我们也相信,用哪个都能开发出想要的炫酷应用。
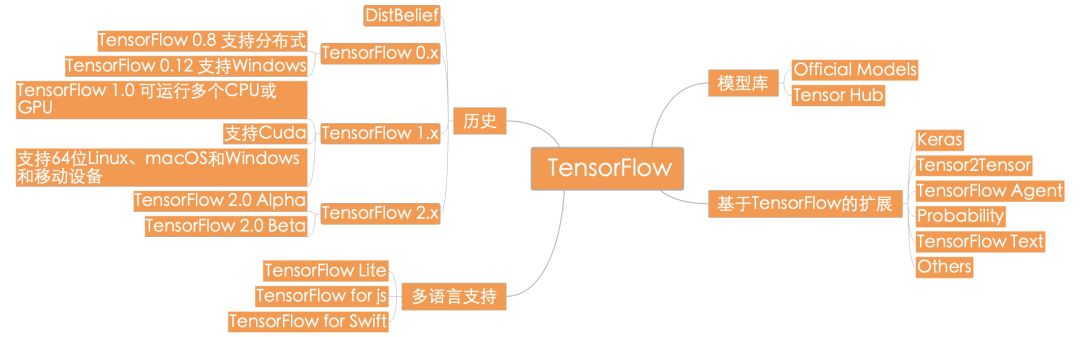
TensorFlow:
PyTorch:
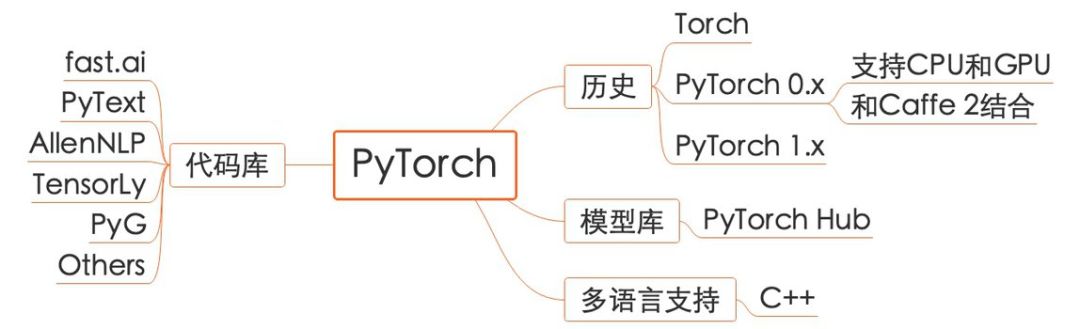
TensorFlow 和 PyTorch 都是经典的机器学习代码库。随着学界和工业界对机器学习的需求的增长,两者的社区也在不断发展壮大。虽然 TensorFlow 是老牌的机器学习代码库,但由于 1.x 及之前版本存在的诸多问题,许多用户逐渐转向对用户友好、学习门槛低、使用方便的 PyTorch。在 2018 年,TensorFlow 逐渐意识到这一问题,并在 2.x 版本逐渐提升了用户体验。
与此同时,基于两个经典机器学习代码库的进一步工具开发也是近年来的趋势。过去有部分基于 TensorFlow 的 Keras 和基于 PyTorch 的 fast.ai,最近一两年则有大量的模型库和方便用户快速训练和部署模型的代码库,如 Tensor2Tensor,以及针对特定领域的代码库,如基于 PyTorch 的 NLP 代码库 PyText 和图神经网络库 PyG。
目前来看,TensorFlow 的生态系统更为多样和完善,且具有多语言的支持,其广受诟病的难以使用的缺点也在逐渐改善。另一方面,由于 PyTorch 本身用户友好的特性,基于这一代码库的应用开发进度似乎也赶上了 TensorFlow,尽管在多语言支持等方面 PyTorch 依然有较大差距。这一机器学习生态之战究竟会走向何方,目前尚不明朗。未来的机器学习代码框架的发展趋势是,模型的训练、部署工作量将会越来越低,类似「搭积木」方式的应用部署方式将会越来越流行。研究者和开发者的精力将会完全转向模型结构的设计、部署和完善,而非纠结于框架的选择和其他底层工程问题上。
参考链接:https://pytorch.org/blog/towards-reproducible-research-with-pytorch-hub/

市北·GMIS 2019全球数据智能峰会于7月19日-20日在上海市静安区举行。本次峰会以「数据智能」为主题,聚焦最前沿研究方向,同时更加关注数据智能经济及其产业生态的发展情况,为技术从研究走向落地提供借鉴。
本次峰会设置主旨演讲、主题演讲、AI画展、「AI00」数据智能榜单发布、闭门晚宴等环节,已确认出席嘉宾如下:

大会早鸟票已开售,我们也为广大学生用户准备了最高优惠的学生票,点击阅读原文即刻报名。



