CMU数据集 Tilt-Bot :让机器人识别动作、画面和声音三位一体 | 数据集装箱

想象一下你正在开香槟:这个场面不但有庆祝的视觉画面,而且会有开香槟时候的独特气流声。
真实的世界中总是有各种类型的信息丰富并满足我们五种感官的需求——视觉,触觉,气味,声音和味道。其中,视觉、触觉和声音更是在人类用身体去感受世界的活动中起着至关重要的作用。
一个真正的、具有智能的机器也需要捕捉所有三种感官的相互作用,以建立对世界的感官理解。
近年来,研究人员开发了越来越多的计算技术,以使机器人具备人类一样的能力。
卡内基梅隆大学(CMU)的研究小组最近进行了一项研究,探讨了用声音+动作+视觉(sound-action-vision)来开发具有更先进传感功能的机器人的可能性。
关于这项研究的论文由机器人学顶级会议 Robotics: Science and Systems 接收,其中还介绍了迄今为止创建的最大的声音+动作+视觉数据集——Tilt-Bot 数据集,由名为 Tilt-Bot 的机器人平台与各种对象进行交互收集而来。

Tilt-Bot的诞生
研究员 Lerrel Pinto 表示:“在机器人学习中,我们通常只用视觉输入来进行感知,但是人类具有的感知方式不仅限于视觉。”
“声音是学习和理解我们的物理环境的关键组成部分。因此,我们提出了这样一个问题:在机器人技术的探索中,声音究竟可以起到什么作用呢? 为了回答这个问题,我们创造了机器平台 Tilt-Bot,它不仅可以与对象互动,而且可以收集大规模的交互式视听数据集。”

Tilt-Bot 数据的收集过程是:一种自动托盘可以倾斜物体直到它们碰到石膏托盘的薄壁,Pinto 和他的同事在自动托盘四周的薄壁上放置了接触式麦克风,以记录物体撞击薄壁时产生的声音,并使用高架摄像头直观地捕捉每个物体的运动。
研究人员收集了来自 60 个物体和托盘之间超过 15000 次碰撞的视觉和声音数据。这样一来,便可以采集到新的图像和音频数据集,从而有助于训练机器人在动作、图像和声音之间建立关联。
Pinto 和他的同事在论文中使用此数据集来探索机器人应用中声音和动作之间的关系,收集了许多有趣的发现。
首先,他们发现分析物体移动和撞击表面的声音记录可以让机器区分不同的物体,例如区分金属螺丝刀和金属扳手。
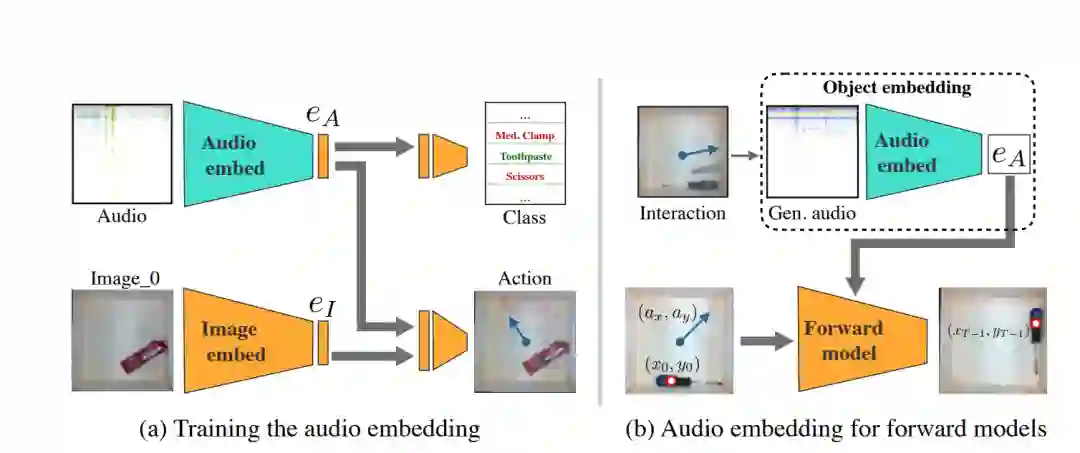
Pinto 解释到:“令人兴奋的是,我们的研究初步结果——仅凭声音就识别出物体类型的准确率接近 80%。”“我们还证明,机器可以学习基于声音的对象表示形式,有助于解决后续的机器人任务。例如,当识别空酒杯的声音时,机器人会明白操作空酒杯和操作满酒杯需要不同的动作。”
一个方兴未艾的研究方向
事实上,CMU 此次的研究与近年新出现的一个小众但又充满前景的领域息息相关,那就是视觉和声音的联合学习(Audio-Visual Learning)。
-
声音表明粒状物信息。这意味着仅仅从物体发出的声音,经过学习的模型可以从不同的物体中识别出该对象。 -
声音表明行动信息。这意味着从物体发出的声音,经过学习的模型可以知晓哪些操作被作用到该对象。 -
声音表明视觉上“隐身”了的信息。这意味着从物体发出的声音,经过学习的模型可以推断物理上隐形的信息。
References
[1]https://arxiv.org/pdf/2007.01851.pdf