开发 | 三年来,CNN在图像分割领域经历了怎样的技术变革?
AI科技评论按:卷积神经网络CNN是深度学习中最典型的算法之一,它可以将图片通过一系列的卷积、非线性、池(采样)、全连接层之后得到一个输出。这篇文章中,我们会一起来看在图像实例分割领域,CNN 的发展简史:它可被如何使用,以得到惊人的结果。
CNN 远远不止于处理分类问题。
据AI科技评论了解,在 2012 年,Alex Krizhevsky, Geoff Hinton, and Ilya Sutskever 赢得 ImageNet 挑战赛堪称是 CNN 发展史上的里程碑,自那之后,CNN 就成了图像分类的黄金标准,并且性能不断提升。现在,它已经在 ImageNet 挑战赛上有了超人类的表现。
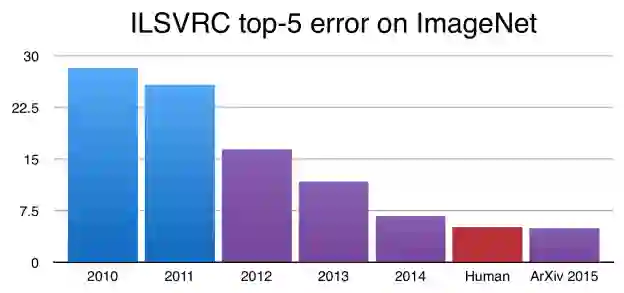
自 2015 年起,CNN 在 ImageNet 的错误率已低于人类
虽然这很令人激动,但相比人类高度复杂、多样化的视觉理解系统,图像识别要简单得多。
在图像识别任务中,一般图中央仅有一个需要识别的物体,而任务便是判断该图像是什么。但当我们用眼睛观察周围的世界时,我们进行的是远远更复杂的任务。

我们眼中的视野高度复杂,有许多个重叠、相互遮挡的物体,有不同的背景;我们的大脑不仅对这些物体进行分类,还会识别它们的边缘轮廓、差异、以及相互之间的关系。

问题来了:CNN 是否“ hold 住”这样复杂的任务?换句话说,给定一个十分复杂的图像,我们是否能用 CNN 来识别其中的不同物体、它们的边缘轮廓?正如 Ross Girshick 和他的同事最近几年的研究所展示:这是完全可以实现的。
内容简介
本文将讲述基于 CNN 的物体检测、分割主流技术背后的直觉性思路,并看看它们是如何从一种执行方式进化到另一种。其中,我们将覆盖 R-CNN (Regional CNN)、该类问题的最初 CNN 解决方案、 Fast R-CNN 以及 Faster R-CNN 等话题。文末将讨论 Facebook 研究团队最近搞出来的 Mask R-CNN,它把物体检测技术拓展到提供像素级别的分割。
这是本文涉及的论文:
R-CNN: https://arxiv.org/abs/1311.2524
Fast R-CNN: https://arxiv.org/abs/1504.08083
Faster R-CNN: https://arxiv.org/abs/1506.01497
Mask R-CNN: https://arxiv.org/abs/1703.06870
2014: R-CNN

R-CNN 是将 CNN 用于物体检测的早期应用。
受到深度学习之父 Geoffrey Hinton 实验室研究的启发,加州伯克利教授 Jitendra Malik 带领的一只小团队提出了一个今天看来无可回避的问题:
在什么程度上 Krizhevsky et. al 的研究结果可泛化到物体识别?
如同其名称,物体识别是在图像中找出不同物体、并对其分类的任务(如上图)。该团队包括 Ross Girshick、Jeff Donahue 和 Trevor Darrel,他们发现该问题可通过在 PASCAL VOC 挑战上进行测试,用 Krizhevsky 的结果来解决。PASCAL VOC 是一个类似于 ImageNet 的流行物体识别挑战。
他们写到:
该论文首次展示出,与更简单的、基于 HOG 特征的其他系统相比, CNN 在 PASCAL VOC 上有非常优越的物体识别表现。
现在,我们来看一看他们的架构,Regions With CNNs (R-CNN) ,是如何工作的。
理解 R-CNN
R-CNN 的目标是:导入一张图片,通过方框正确识别主要物体在图像的哪个地方。
输入:图像
输出:方框+每个物体的标签
但怎么知道这些方框应该在哪里呢?R-CNN 的处理方式,和我们直觉性的方式很像——在图像中搞出一大堆方框,看看是否有任何一个与某个物体重叠。

生成这些边框、或者说是推荐局域,R-CNN 采用的是一项名为 Selective Search 的流程。在高层级,Selective Search(如上图)通过不同尺寸的窗口来查看图像。对于每一个尺寸,它通过纹理、色彩或密度把相邻像素划为一组,来进行物体识别。
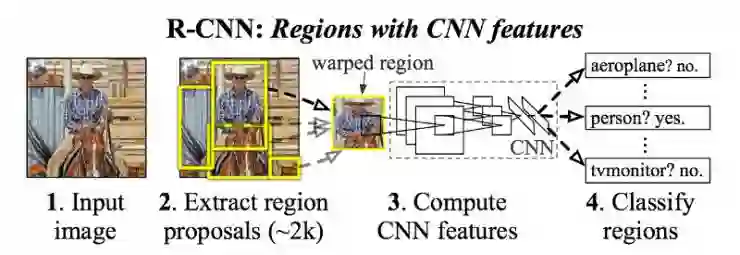
如上图,当边框方案生成之后,R-CNN 把选取区域变形为标准的方形,并将之喂给改良版的 AlexNet(ImageNet 2012 的冠军方案,它启发了R-CNN )。
在 CNN 的最后一层,R-CNN 加入了一个支持向量机,它要做的事很简单:对这是否是一个物体进行分类,如果是,是什么物体。这便是上图中的第四步。
对边框进行改进
现在,既然已经找到了方框中的物体,我们是否能缩小边框,让它更符合物体的三维尺寸?答案是肯定的,这是 R-CNN 的最后一步。R-CNN 在推荐区域上运行一个简单的线性回归,生成更紧的边框坐标以得到最终结果。
这是该回归模型的输入和输出:
输入:对应物体的图像子区域
输出:针对该物体的新边框系统
概括下来,R-CNN 只是以下这几个步骤:
生成对边框的推荐
在预训练的 AlexNet 上运行方框里的物体。用支持向量机来看边框里的物体是什么。
在线性回归模型上跑该边框,在物体分类之后输出更紧的边框的坐标。
2015: Fast R-CNN
它加速、简化了 R-CNN。
R-CNN 的效果非常好,但出于以下几个原因,它运行起来特别慢:
对于每一个图像的每一个推荐区域,它都需要一个 CNN (AlexNet) 的 forward pass。这意味着每个图像就需要约 2000 个 forward pass。
它必须分来训练三个不同的模型——生成图像特征的 CNN,预测类别的分类器以及收紧边框的回归模型。这使得训练流水线变得特别困难。
在 2015 年,R-CNN 的第一作者 Ross Girshick 解决了上述两个问题,导致了本简史中第二个算法的诞生: Fast R-CNN

Ross Girshick
Fast R-CNN 特性
1. RoI (Region of Interest) Pooling
对于 CNN 的 forward pass,Girshick 意识到对于每个图像,许多推荐区域会不可避免的重叠,同样的 CNN 运算会一遍遍重复 (~2000 次)。他的思路很简单:为什么不能在每一个图像上只运行一次 CNN,并找到一种在 ~2000 个推荐里共享计算的方式?
借助名为 RoIPool 的技术,Fast R-CNN 实现了该思路。在其核心,RoIPool 会对图像的所有子区域共享 CNN 的forward pass。上图便是示例,注意每个区域的 CNN 特征,是怎么通过选择 CNN 特征图的相应区域来获取的。然后,每个区域的特征被池化(“pooled”,通常使用 max pooling)。因此原始图像只需要计算一遍,而不是 2000 遍。
2. 把不同模型整合为一个网络

第二项特性是在一个模型里联合训练 CNN、分类器和边框回归量。而此前,提取图像特征要用 CNN,分类要用支持向量机,收紧边框要用回归。Fast R-CNN 用一个单个的网络完成这三项任务。
至于这是如何实现的,请看上图。Fast R-CNN 在 CNN 之上添加一个 softmax 层输出分类,来代替支持向量机。添加一个与 softmax 平行的线性回归层,来输出边框坐标。这种方式,所有需要输出都通过单个神经网络得到。这是模型整体的输入和输出:
输入:有区域推荐的图像
输出:每个区域的物体识别,收紧的边框
2016:Faster R-CNN
名字很直白,它加速了选区推荐。
即便有上文所提到的优点,Fast R-CNN 仍然有一个重大瓶颈:选区推荐器。正如我们看到的,检测物体位置的第一步,是生成一系列候选边框来进行测试。AI科技评论了解到,在 Fast R-CNN 里,这些推荐通过 Selective Search 生成。后者是一个相当慢的过程,成为系统整体的瓶颈。
在 2015 年,微软的孙剑、任少卿、何凯明、Ross Girshick 找到了一个让推荐步骤几乎不需要成本的办法,这通过被他们称之为 Faster R-CNN 的架构来实现。

孙剑
Faster R-CNN 背后的思路是:既然选区推荐取决于 CNN forward pass 已经计算出来的图像特征,那么,为什么不对区域推荐重复利用这些 CNN 结果,来代替运行一个单独的 selective search 算法?
这便是 Faster R-CNN 更快的原因。
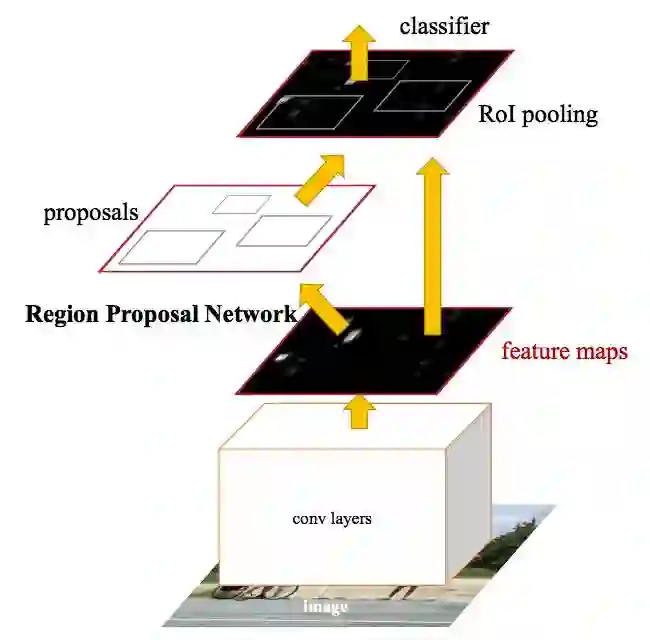
上图中,你可以看到单个 CNN 是如何同时进行选区推荐和分类。利用这种方式,只有一个 CNN 需要被训练,我们也几乎不费成本地得到了选区推荐。作者们写到:
“我们的观察是:基于区域的检测器所使用的卷积特征图,比如 Faster R-CNN,也能被用来生成选区推荐。”
这是模型的输入和输出:
输入:图像(选区推荐并不需要)
输出:分类、图中物体的边框坐标。
选区是如何生成的
我们一起多花几分钟,看看 Faster R-CNN 是如何从 CNN 特征里生成选区推荐的。Faster R-CNN 在 CNN 特征之上添加了完全卷积网络(Fully Convolutional Network ),以生成 Region Proposal Network。
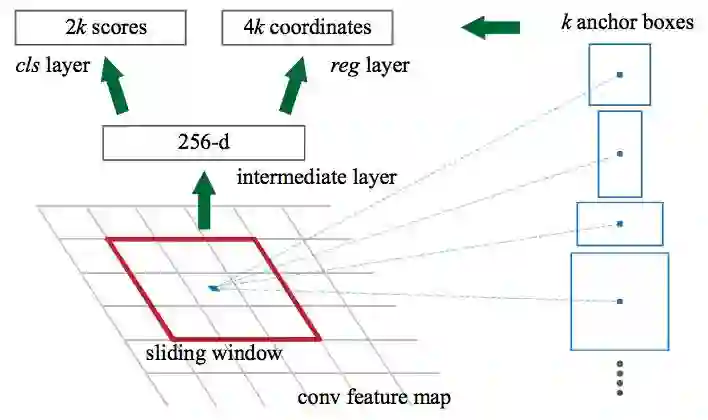
Region Proposal Network 通过在 CNN 特征图上传递滑窗(sliding window)来运作,在每个窗口输出 K 潜在边框和对每个边框的评估分值。这些 K 边框代表了什么呢?

直觉上,我们知道图像中的物体应该符合特定的常用长宽比例和尺寸,比如类似于人体形状的矩形选框。类似的,我们知道很窄的选框并不会太多。于是我们创造出 anchor boxes ——K 常用长宽比例,对于每一个 anchor boxe,我们输出选框以及图像中的每个位置的分值。
有了这些 anchor boxes,我们看看 Region Proposal Network 的输入、输出。
输入: CNN 特征图
输出:每个 anchor 对应一个选框。一个分值,用来表示选框内图像是否为物体。
之后把每个可能是物体的选框导入 Fast R-CNN,生成分类和收紧的选框。
2017: Mask R-CNN
把 Faster R-CNN 拓展到像素级的图像分割。

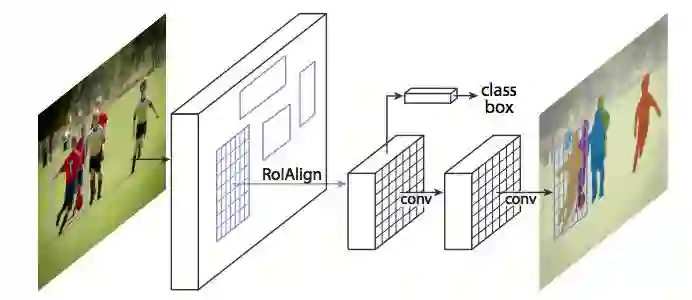
到现在,我们已经看到了多种利用 CNN 特征、利用选框来锁定图像中不同物体的有趣方式。我们是否能够将这些技术进一步,去定位物体的每一个像素呢?
该问题便是图像分割(image segmentation)。对此,Facebook AI 的何凯明、Girshick 等研究人员开发出了一个名为 Mask R-CNN 的架构。

与 Fast R-CNN、Faster R-CNN 一样,Mask R-CNN 的底层逻辑也很直接:Faster R-CNN 对物体识别效果这么好,我们能够将之扩展到像素级别的分割?
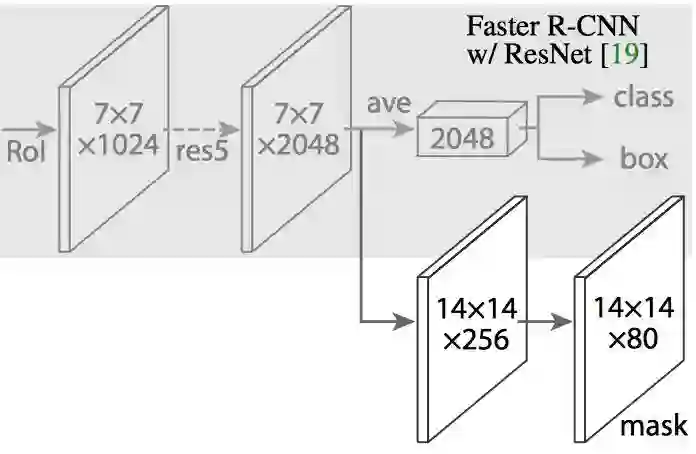
Mask R-CNN 通过向 Faster R-CNN 加入一个分支来实现这一点,该分支输出一个二元的 mask,指示某像素是否是物体的一部分。这分支(图中白色部分)说白了就是一个 CNN 特征图上的全卷积网络。这是它的输入、输出:
输入:CNN 特征图
输出:矩阵,属于物体的像素在矩阵内用 1 表示,否则用 0 表示(这就是二元 Mask)。
为使 Mask R-CNN 如预期的运行,作者们做了一个小改变:RoiAlign,或者说 Realigning RoIPool。
RoiAlign
当不加修改地运行于原始版本的 Faster R-CNN,RoIPool 选择的特征图区域,会与原图中的区域有轻微排列出入。而图像分割需要像素级别的精确度。于是,作者们巧妙地对 RoIPool 进行调整,使之更精确得排列对齐,这便是 RoIAlign。
假设我们有一个 128x128 的图像,25x25 的特征图,想要找出与原始图像左上角 15x15 位置对应的特征区域,怎么在特征图上选取像素?
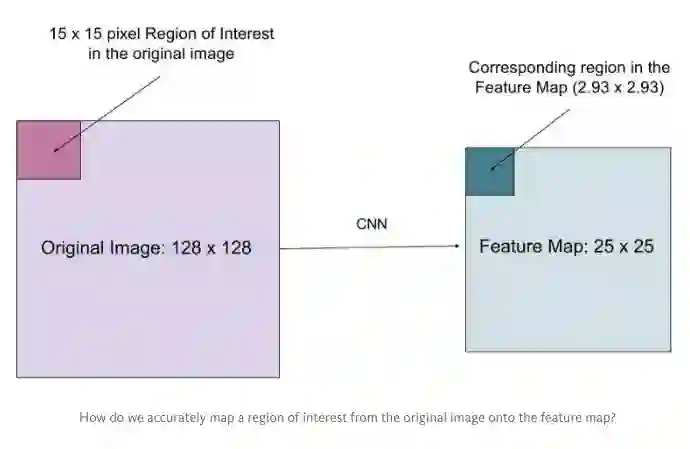
我们知道原始图像的每一个像素与特征图上的 25/128 个像素对应。为了在原始图像选取 15 个像素,在特征图上我们需要选择 15 * 25/128 ~= 2.93 个像素。
对于这种情形,RoIPool 会舍去零头选择两个像素,导致排列问题。但在 RoIAlign,这种去掉小数点之后数字的方式被避免,而是使用双线性插值(bilinear interpolation)准确获得 2.93 像素位置的信息。在高层级,这避免了排列错误。
在 mask 生成之后,Mask R-CNN 把它们与 Faster R-CNN 的分类、选框结合起来,生成相当精确的分割:

后话
短短三年的时间,我们就看到了机器学习社区从 Krizhevsky et. al 的原始结果进步到 R-CNN,并最终开发出 Mask R-CNN 这样的强大方案。若单独来看,Mask R-CNN 像是一步巨大的技术飞跃,令人难以望其项背。但在这篇简史中,我希望大家看到,这样的进步是一系列直觉性、渐进式进步的总和,是多年苦心合作研究的成果。
但从 R-CNN 到 Mask R-CNN 毕竟只用了三年。在接下来的三年,计算机视觉又会进步多少呢?
via athelas,AI科技评论编译
报名 |【2017 AI 最佳雇主】榜单

在人工智能爆发初期的时代背景下,雷锋网联合旗下人工智能频道AI科技评论,携手《环球科学》和 BOSS 直聘,重磅推出【2017 AI 最佳雇主】榜单。
从“公司概况”、“创新能力”、“员工福利”三个维度切入,依据 20 多项评分标准,做到公平、公正、公开,全面评估和推动中国人工智能企业发展。
本次【2017 AI 最佳雇主】榜单活动主要经历三个重要时段:
2017.4.11-6.1 报名阶段
2017.6.1-7.1 评选阶段
2017.7.7 颁奖晚宴
最终榜单名单由雷锋网、AI科技评论、《环球科学》、BOSS 直聘以及 AI 学术大咖组成的评审团共同选出,并于7月份举行的 CCF-GAIR 2017大会期间公布。报名期间欢迎大家踊跃自荐或推荐心目中的最佳 AI 企业公司。
报名方式
如果您有意参加我们的评选活动,可以点击【阅读原文】,进入企业报名通道。提交相关审核材料之后,我们的工作人员会第一时间与您取得联系。
【2017 AI 最佳雇主】榜单与您一起,领跑人工智能时代。





