BMXNet:基于MXNet的二进制神经网络实现

近年来,深度学习在学术和行业领域取得突破性的进展,但深度学习需要耗费大量的计算和存储资源。与此同时,移动、可穿戴设备、自动机器人和物联网对深度学习的需求愈加旺盛,所以如何将深度学习模型应用在这些低配置的设备上成为了一个巨大的挑战。二进制神经网络(BNN)的出现解决了在低配置设备上应用深度学习模型的难题。
位于德国波茨坦的 Hasso Plattner Institute 近日开源了一个 BNN 库,叫作 BMXNet。它基于 Apache MXNet,使用 C 和 C++ 实现,支持将 BNN 层无缝地与其他标准库组件结合在一起,并支持 GPU 和 CPU 两种模式。
BMXNet 提供了激活层、卷积层和全连接层,并支持二进制的输入数据和权重。它们分别是 QActivation、QConvolution 和 QFullyConnected,分别与 MXNet 的三个层对应。它们提供了一个额外的参数 act_bit,用于控制位宽。
在传统的深度学习模型中,全连接和卷积层严重依赖矩阵的点积,导致出现大量的浮点数运算。而二进制权重和输入数据可以利用 CPU 的 xnor 和 popcount 指令,从而极大地提升矩阵乘法的性能。
在训练阶段,BMXNet 二进制化的层衔接 MXNet 内置的层,将权重和输入限制在 -1 和 +1 之间的离散值范围内。在计算出点积之后,将计算结果映射回 xnor 风格的点积值区间。
在使用 BMXNet 训练之后,权重以 32 位浮点变量的形式保存下来,使用 1 个 bit 位宽训练得到的网路也是如此。BMXNet 提供了 model_converter,用于读取训练过的二进制文件和打包 QConvolution 及 QFullyConnected 层的权重。经过转换之后,每个权重只占用一个 bit 的存储空间和内存。
以下是 BMXNet 在 MNIST(手写识别)和 CIFAR-10(图像分类)数据集上训练得出的一个实验结果。

从表中可以看出,二进制模型在大小方面有很大优势,在准确度方面虽然有一点下降,但相差不远,仍然有很大的竞争力。
下图是一组性能方面的实验数据。使用了不同的 GEMM 方法和一组固定的参数:过滤值为 64,内核大小为 5x5,批次大小为 200,矩阵的 M、N、K 分别为 64、12800 和内核宽度 x 内核高度 x 输入通道大小。
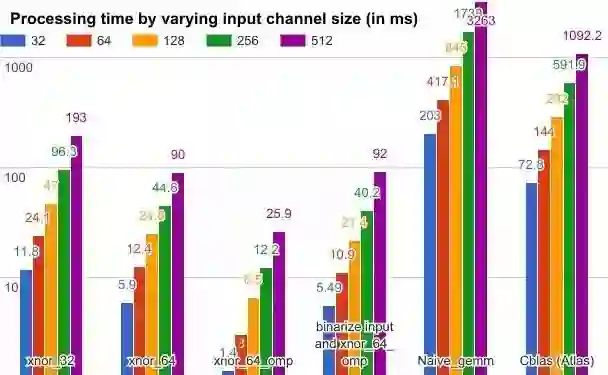
图中有颜色的长方形表示处理时间,xnor_32 和 xnor_64 分别表示 32 位和 64 位的 xnor gemm 操作符,xnor_64_omp 表示使用了 OpenMP 并行编程库的 64 位 xnor gemm 加速。二进制化输入和 xnor_64_omp 又将二进制化的处理时间也累积起来。尽管输入数据的二进制化也耗费了一些时间,但仍然得到比 Cblas 方法更好的结果。
从目前的实验的结果来看,它的模型大小只有传统模型的二十九分之一,而且在 gemm 计算方面具有更高的效率。BMXNet 的源代码、文档以及一些应用示例的代码和预训练模型可以在 GitHub(https://github.com/hpi-xnor)上找到。下一步,该项目将会在准确度和效率方面做更多的改进,并在 Q_Conv 层重新实现 unpack_patch2col 方法,以便改进 CPU 模式下的推理速度。