高并发的常用策略
高并发问题可以分为2类:
侧重于"读"
例如电商的商品详情,商品的查看请求远远高于商品的发布、修改。
侧重于"写"
例如广告扣费系统,广告主向自己的账号充钱、设置自己的广告,用户浏览或者点击广告后就需要扣费,这个扣费操作的数量是极大的。
所以,对于高并发的应对策略也可以从"读"、"写"这2个方面来梳理。
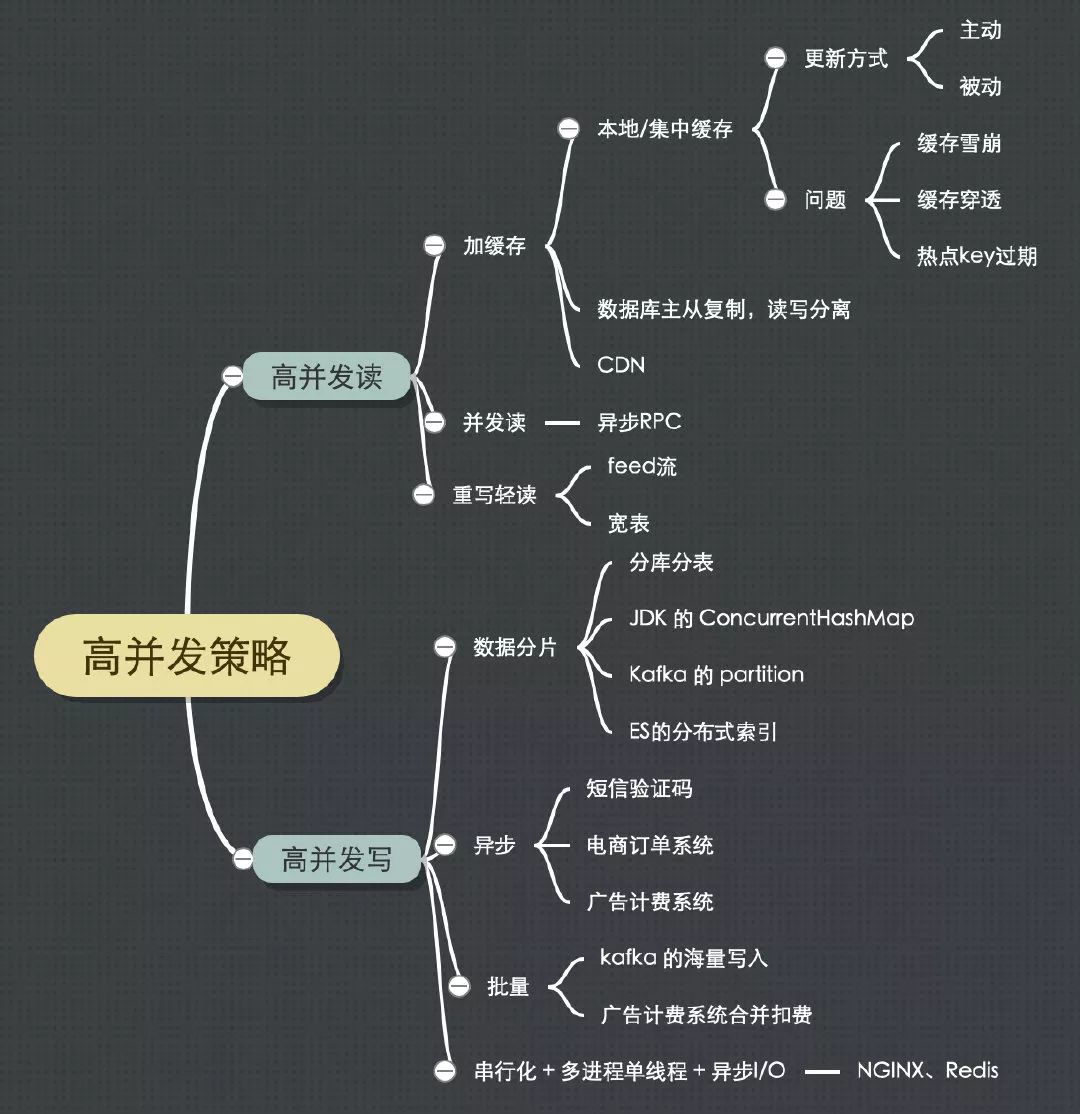
一、高并发读
策略1:加缓存
示例1:本地缓存或集中式缓存
缓存可以有效的保护数据库,提高读性能,分为本地缓存,或者集中式的 memcached/redis 缓存。
缓存的更新方式有2种:
主动更新,数据库记录发生变化时,主动更新缓存数据。
被动更新,读缓存时,如果缓存过期,就更新缓存。
缓存需要注意的3个问题:
缓存雪崩。如果缓存宕机,数据库可能会被压垮,这是缓存高可用的问题。
缓存穿透。缓存没宕机,但短时间内大量被查询的key没在缓存中,直接访问数据库,有压垮的风险。
大量的热点key过期。和缓存穿透类似,因为key过期,短时间内大量请求数据库。
这些问题和缓存回源策略有关:
不回源。只查询缓存,如果缓存中没有,直接返回空,这种方式肯定是主动更新方式,并且不设置过期时间,不会有上面的几个问题。
回源。如果缓存中没有,就查询数据库然后更新缓存,这种方式就要考虑上面的几个问题。
示例2:MySQL 主从
把数据库部署成主从模式,并做好读写分离,这也是一种缓存的方式。
master处理写请求,数据同步更新到slave上,slave就相当于master的缓存,所有读请求都访问slave,分担了master的压力,slave的数量还可以扩展,提升处理能力。
示例3:CDN 静态文件加速
例如 HTML、CSS、JS、图片这些静态资源非常适合放到CDN上进行缓存。
CDN服务商的节点是全国各地的,你的一份静态文件会被缓存到各个节点,用户访问时,会自动读取最近的节点。
CDN是静态内容的常用缓存策略。
策略2:并发读
串行改并行是一个常用策略。
示例:异步RPC
例如需要调用3个RPC接口,耗时分别为 t1 t2 t3。
如果同步调用,总耗时 =t1 + t2 + t3。
如果是异步调用,总耗时 = max(t1,t2,t3)。
所以,如果接口之间没有耦合关系时,就可以考虑并行。
策略3:重写轻读
基本思路就是写入数据时多写点(冗余写),降低读的压力。
示例1:社交feed流
社交平台中用户可以互相关注,查看关注用户的最新消息,形成feed流。
用户查看feed流时,系统需要查出此用户关注了哪些用户,再查询这些用户所发的消息,按时间排序。
为了满足高并发的查询请求,可以采用重写轻读,提前为每个用户准备一个收件箱。
每个用户都有一个收件箱和一个发件箱。比如一个用户有1000个粉丝,他发布一条消息时,写入自己的发件箱即可,后台异步的把这条消息放到那1000个粉丝的收件箱中。
这样,用户读取feed流时就不需要实时查询聚合了,直接读自己的收件箱就行了。把计算逻辑从"读"移到了"写"一端,因为读的压力要远远大于写的压力,所以可以让"写"帮忙干点活儿,提升整体效率。
示例2:宽表
例如分库以后的跨库查询,需要从多个库中查询聚合,效率不高,这时也可以采用重写轻读的策略:提前把关联数据计算好,读的时候直接读聚合好的数据,不用每次从多个库中聚合数据。
可以准备一个宽表,把要关联的数据计算好后保存在宽表里。根据实际情况,可以定时计算、数据变更触发等。
也可以使用ES,把多表的关联结果做成一个个文档,以便于快速查询。
二、高并发写
策略1:数据分片
示例1:数据库分库分表
数据库应对读压力可以加缓存、加slave,应对高并发写时,可以分库分表,可以更充分的利用系统资源,将访问压力均匀分布。
示例2:JDK 的 ConcurrentHashMap
ConcurrentHashMap 内部分成了若干槽,也就是若干个子 HashMap,这些槽可以并发的读写,互相独立,不会发生数据互斥。
示例3:Kafka 的 partition
topic 可以被分成多个 partition,partition 之间是独立的,可以并发读写,提高了 topic 的并发处理能力。
示例4:ES的分布式索引
搜索引擎里有分布式索引的策略,比如有10亿个商品,如果建在一个倒排索引里面,则索引很大,不能并发查询。
可以分成 n 份,建立 n 个小的索引,查询请求来了以后,并行在 n 个索引上查询,再把查询结果合并。
策略2:异步
示例1:短信验证码
调用短信平台发送一条短信大概需要2、3秒,如果同步调用的话,应用服务器会被阻塞,并发高时就崩溃了。
可以采用异步方式,应用服务器收到发短信的请求后,放到消息队列,立即返回。后台程序从队列读取消息,去调用第三方短信平台发送验证码。
示例2:电商订单系统
例如我们一次买了3个商品,来自3个卖家,我们只下了一个订单、付了一次款,但在我的订单页面会看到3个订单,这个1变3的过程是”拆单“,此环节就是异步的。
示例3:广告计费系统
广告主向账号里充钱,用户每次浏览点击后,从广告主账号里扣钱。如果每次点击都同步从数据库里扣钱,肯定支撑不住。
可以异步处理,用户点击请求被放到消息队列,后台的处理模块会消费消息,进行扣费的相关处理,这是一个典型的流式计算模型。
策略3:批量
示例1:kafka 的海量写入
kafka 写入速度非常快,为什么呢?一是因为 partition 分片策略,还有磁盘顺序写入策略,再有一个就是“批量”。
kafka 客户端在内存中为每个 partition 准备了一个队列,producer 线程一条条的发消息,这些消息进入内存队列,sender 线程从队列中批量提取消息发给 kafka 集群。
如果是同步发送,producer 向队列中放入消息后阻塞,sender 发出去之后 producer 才返回,没有批量操作。
如果是异步发送,producer 把消息放到内存队列后就返回了,sender 会把队列中的消息打包,一次批量发出去多个。
示例2:广告计费系统合并扣费
上面提到了广告计费系统的异步策略,在异步基础上,还可以实现合并扣费。
例如10个用户都点了1次某广告,意味着要扣10次钱,可以改为合并扣费,1次扣10次点击的钱,减少数据库写操作。
策略4:串行化 + 多进程单线程 + 异步I/O
多线程可以提高并发度,提升处理能力,但多线程存在锁竞争、线程切换开销大的问题。
NGINX、Redis 都是单线程模型,因为有了异步I/O,可以把请求串行化处理,没有了锁的竞争,也没有了I/O的阻塞,所以非常高效,如果想利用多核优势,可以开多个实例,采用多进程单线程的方式。
三、小结
内容整理自《软件架构设计:大型网站技术架构与业务架构融合之道》