一文读懂可解释机器学习简史,让你的模型再也不是「Black Box」
转载新智元
转载新智元
来源:arXiv
编辑:QJP
近年来,可解释机器学习(IML) 的相关研究蓬勃发展。尽管这个领域才刚刚起步,但是它在回归建模和基于规则的机器学习方面的相关工作却始于20世纪60年代。最近,arXiv上的一篇论文简要介绍了解释机器学习(IML)领域的历史,给出了最先进的可解释方法的概述,并讨论了遇到的挑战。
可解释机器学习(IML)简史
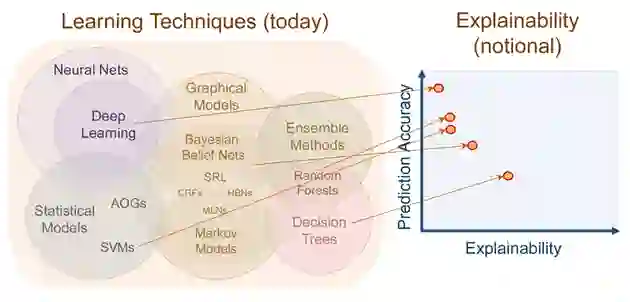 而在机器学习中,使用的建模方法略有不同。
而在机器学习中,使用的建模方法略有不同。
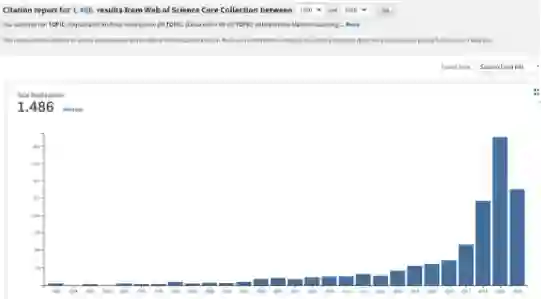
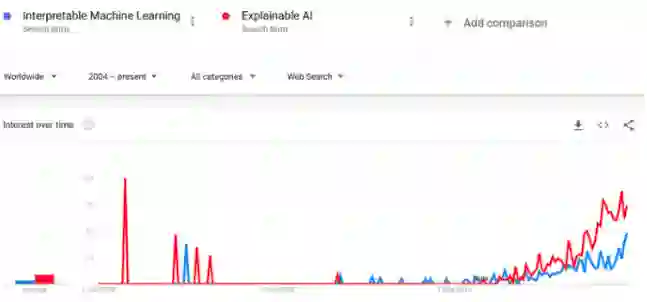
IML中的常见方法
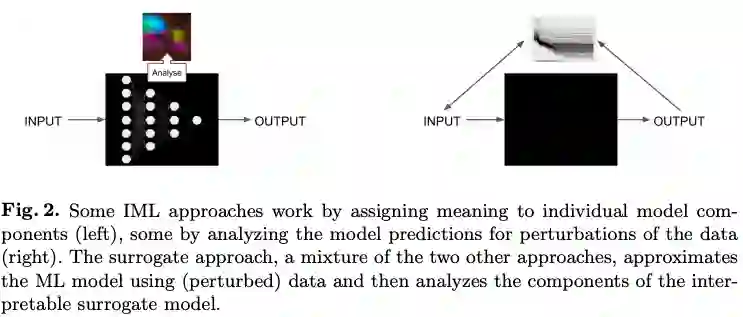
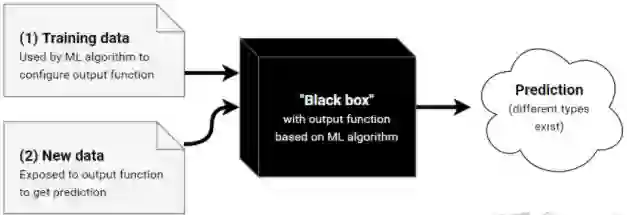
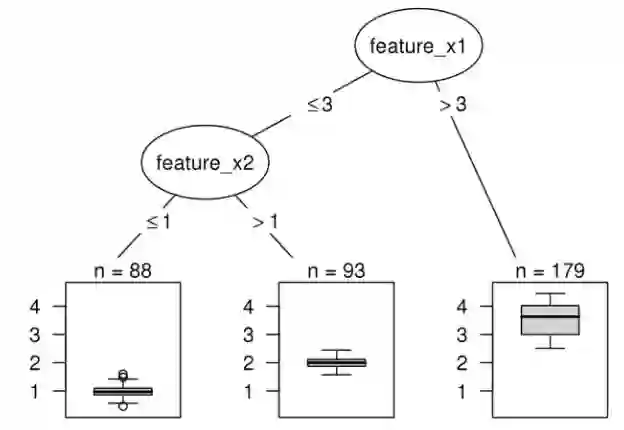
IML发展中遇到的挑战
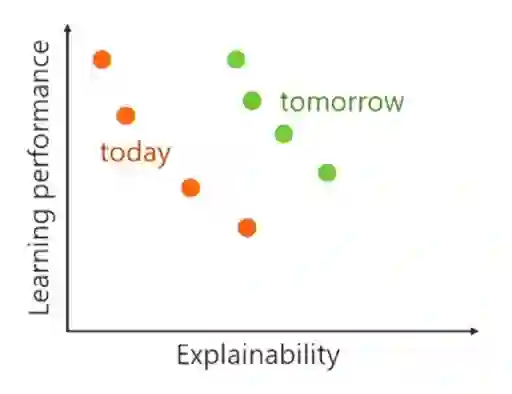 不幸的是,预测性能和因果关系可能是一种相互矛盾的目标。
不幸的是,预测性能和因果关系可能是一种相互矛盾的目标。
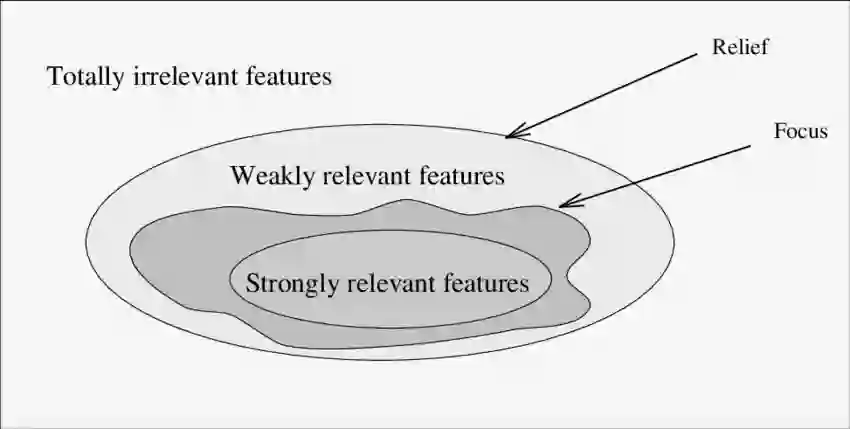
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“EML15” 可以获取《一文读懂可解释机器学习简史,让你的模型再也不是「Black Box」》专知下载链接索引



登录查看更多
相关内容

Arxiv
0+阅读 · 2021年1月30日
Arxiv
4+阅读 · 2018年5月18日





相关VIP内容
相关资讯