资源 | 深度学习自动前端开发:从草图到HTML只需5秒(附代码)
选自InsightDataScience
作者:Ashwin Kumar
机器之心编译
参与:乾树、李泽南
在人们的不断探索下,「使用人工智能自动生成网页」的方法已经变得越来越接近实用化了。本文介绍的这种名为 SketchCode 的卷积神经网络能够把网站图形用户界面的设计草图直接转译成代码行,为前端开发者们分担部分设计流程。目前,该模型在训练后的 BLEU 得分已达 0.76。
你可以在 GitHub 上找到这个项目的代码:https://github.com/ashnkumar/sketch-code
为用户创造直观、富有吸引力的网站是各家公司的重要目标,而且这是个快速进行原型、设计、用户测试循环的过程。像 Facebook 这样的大公司有着让整个团队专注于设计流程的人力,改动可能需要几周的时间,并涉及到多种利益相关者;而小型企业就没有这样的资源,因此其用户界面可能受到一些影响。
我在 Insight 当中的目标是使用现代深度学习算法大大简化设计工作流程,并使得任何规模的公司都能快速地创造并测试网页。
现有的设计工作流程
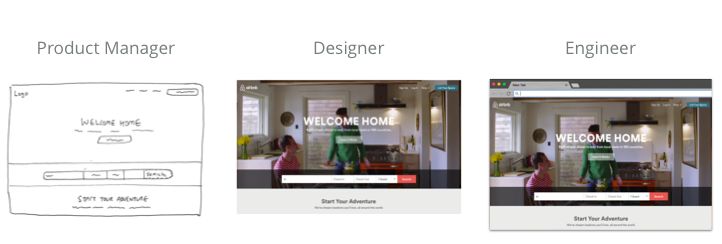
现有工作流程涉及多个利益相关者
一个典型的设计工作流程如下所示:
产品经理进行用户研究,从而制定技术参数表
设计人员将接受这些要求并尝试创建低保真原型,最终创建高保真原型
工程师将这些设计转化为代码并最终将产品交付给用户
开发周期的时间长度很快就会变成瓶颈,像 Airbnb 这样的公司已经开始使用机器学习来提高这个过程的效率了。(参见:https://airbnb.design/sketching-interfaces/)
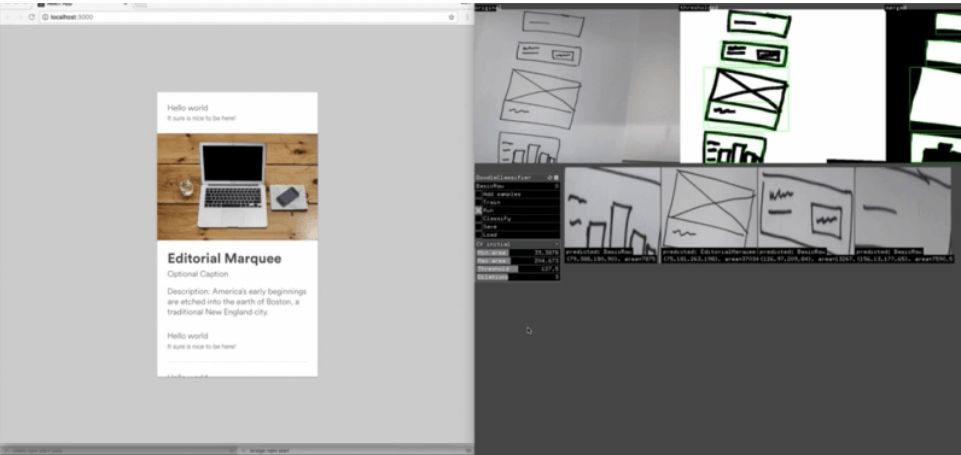
Airbnb 内部 AI 工具演示:从草图到代码
虽然这种工具很有希望成为机器辅助设计的例子,但是尚不清楚这种模型在端到端的情况下能完全训练到什么程度,也不清楚它在多大程度上依赖于手工制作的图像特征。这肯定是无法知道的,因为它目前还是 Airbnb 专有的非开源方案。我想创造一个「从绘图到代码」技术的开源版本,可供更多开发者和设计者使用。
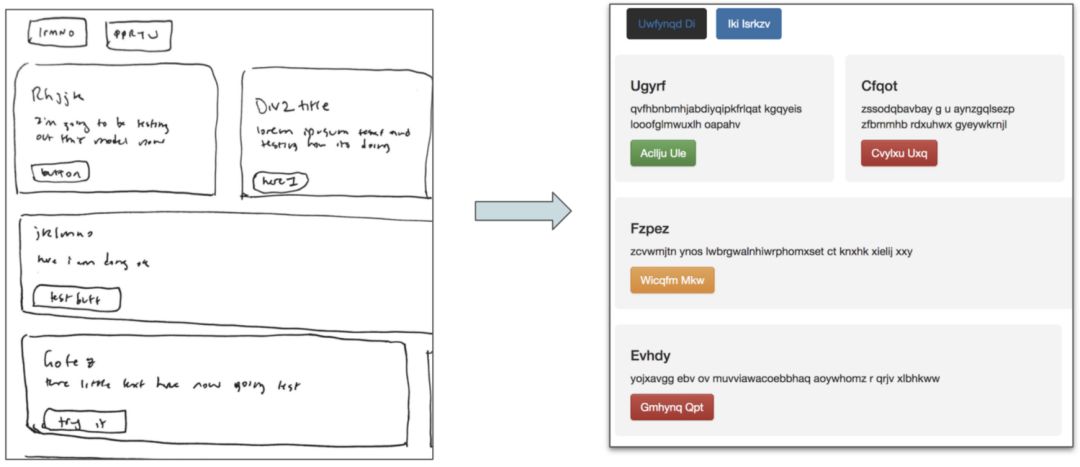
理想情况下,我的模型可以采用简单的网站设计手绘原型,并立即从该图像生成一个可用的 HTML 网站:
SketchCode 模型需要绘制好的网站线框图并能生成 HTML 代码
实际上,上面的例子是一个从我模型测试集图像生成的实际网站!你可以在我的 Github 页面中查看它:https://github.com/ashnkumar/sketch-code
从图像标注中获取灵感
我正在解决的问题属于程序综合(https://en.wikipedia.org/wiki/Program_synthesis)这个广义任务范畴,即工作源代码的自动生成。尽管很多程序综合能处理从自然语言要求或执行轨迹所生成的代码,但在我这个案例中,我可以从一个源图像(手绘线框图)开始,自动获得想要的代码。
机器学习领域中,有一个名为图像字幕生成的领域(https://cs.stanford.edu/people/karpathy/deepimagesent/),该领域有着充分的研究,旨在学习将图像和文本相连的模型,特别是生成关于源图片内容的描述。

图像标注模型生成源图片的描述
我从最近一篇名为 pix2code 的论文和 Emil Wallner 使用该方法的一个相关项目获得了灵感(参见:前端慌不慌?用深度学习自动生成 HTML 代码),并决定将我的任务重构成图像字幕生成问题的一部分,即将线框图作为输入图像,将对应的 HTML 代码作为输出文本。
获取正确的数据集
考虑到图像标注的方法,我心中理想的训练数据集是成千上万对手绘线框图和它们 HTML 代码的等价物。不出所料,我无法找到这种数据集,因此我不得不为该任务创建自己的数据。
我从 pix2code 论文中提到的一个开源数据集(https://github.com/tonybeltramelli/pix2code)入手,它由 1750 张人工生成的网页截图和其对应源代码构成。
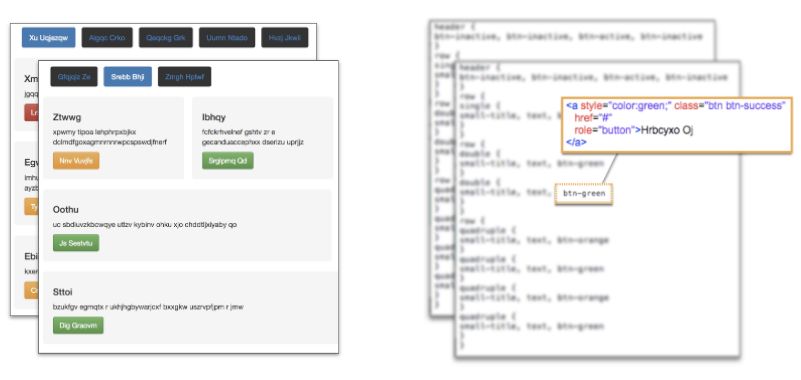
pix2code 中生成的网站图像及其源代码数据集
这个数据集对我而言是个很好的开始,其中有一些有趣的地方:
数据集中每个生成的网站都包含几个简单的 Bootstrap 元素例如按钮、文本框和 DIV。虽然这意味着我的模型将会因把这几个元素作为「词汇」(模型可选择用于生成网站的元素)而受限制,这种方法应该很容易推广到更大的元素词汇表中。
每个示例的源代码包含领域专用语言(DSL)的标记,这些符号是由论文作者创建的。每个标记对应于 HTML 和 CSS 的片段,且有一个编译器将 DSL 转化为工作使用的 HTML 代码。
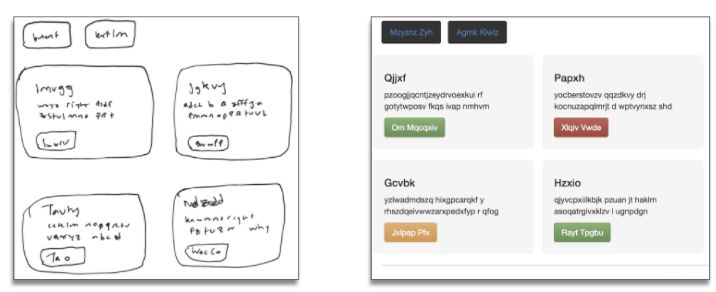
让图片更「手绘化」
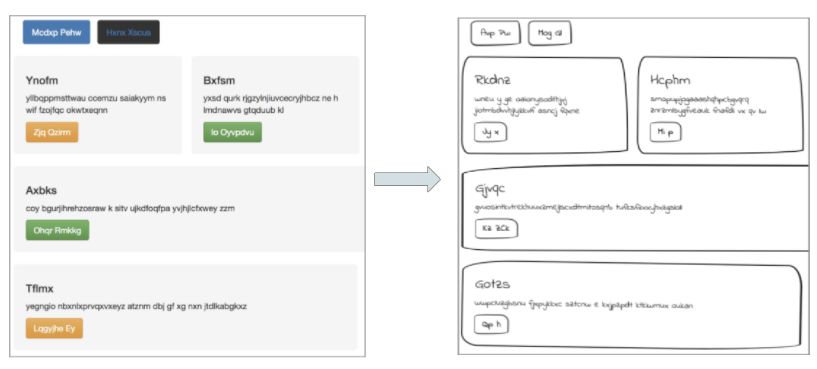
将网站的多彩主题切换成手写主题。
为了调整数据集以适应我的任务,我得把网站的图片弄得像是手绘的。对图片的手绘化都得益于 OpenCV 和 PIL library 的灰度转换和轮廓检测功能。
最终,我决定直接通过一系列操作来直接修改原网站的 CSS 样式表:
通过改变页面元素的边框半径实现按钮和 div 的圆润化
调整边框的粗细以模仿手绘素描,并添加阴影
将字体改为类手写字体
我的最终版本又增加了一个步骤,通过加入倾斜,偏移和旋转来进行数据增强,以模仿实际绘制的素描的不确定性。
使用图像标注模型架构
现在我已经准备好我的数据了,我可以把它输入模型进行训练了!
我用的这个用于图像标注的模型包括三个主要部分:
一个卷积神经网路(CNN)视觉模型用于提取源图片特征
一种由编码源代码标记序列的门控循环单元(GRU)组成的语言模型
一个解码器模型(也是一个 GRU),它以前两个步的输出作为输入,预测序列中的下一个标记
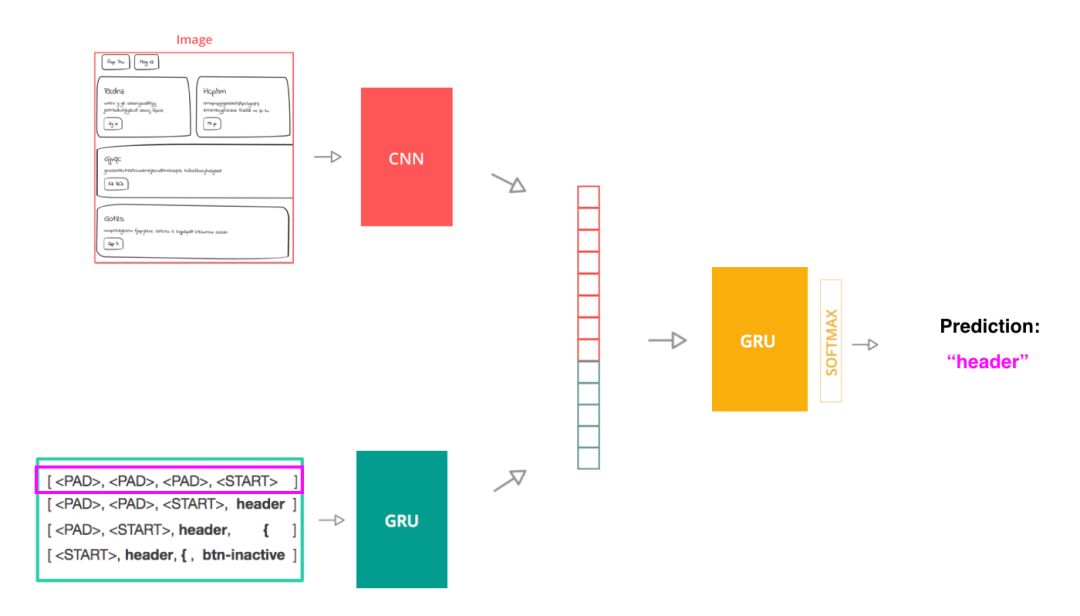
使用标记序列作为输入来训练模型
为了训练这个模型,我把源代码分成标记序列。其中一个序列及其源图像是模型的单个输入,其标签是文档中的下一个标记。该模型使用交叉熵成本(cross-entropy cost)作为其损失函数,将模型预测的下一个标记与实际的标记进行比较。
在模型从头开始生成代码的推理阶段,该过程稍有不同。该图像仍然通过 CNN 网络进行处理,但文本处理仅提供一个开始序列。在每一步中,模型对序列中下一个标记的预测将返回到当前输入序列,同时作为新的输入序列输入到模型中。重复此操作直到模型预测出 <END> 标记或进程达到每个文档的标记数的预定义上限。
一旦从模型中生成了一组预测标记,编译器就会将 DSL 标记转换为 HTML,这些 HTML 可以在任何浏览器中展示出来。
用 BLEU 得分评估模型
我决定用 BLEU 评分(https://machinelearningmastery.com/calculate-bleu-score-for-text-python/)来评估模型。这是机器翻译任务中经常会用到的评估标准,它试图在给定相同输入的情况下,评估机器生成的文本与人类可能写的文本的近似程度。
实质上,BLEU 通过比较生成文本和参考文本的 n-元 序列,生成精修改后的文本。它非常适合这个项目,因为它会影响生成的 HTML 中的实际元素,以及它们之间的相互关系。
然后这是最棒的——我完全可以通过检查生成的网站来理解 BLEU 得分!
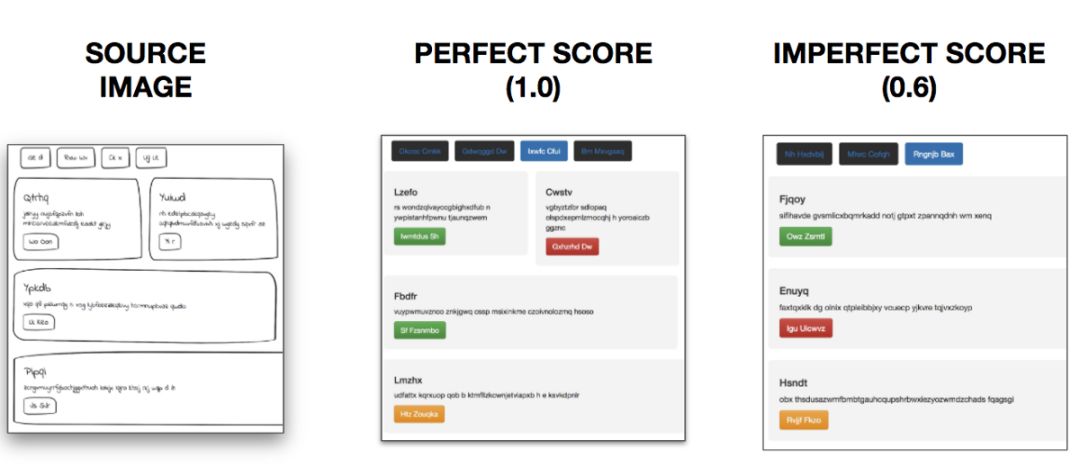
BLEU 得分可视化
一个完美的 1.0 的 BLEU 分数将在正确的位置生成源图像的正确元素,而较低的得分可以预测错误的元素和/或将它们放在相对于彼此错误的位置。最终我的模型能够在测试集上得到 0.76 的 BLEU 分数。
福利 - 定制样式
我觉察到的一个额外福利是,由于模型只生成页面的骨架(文档的标记),我可以在编译过程中添加一个自定义的 CSS 层,并且可以即时看到网站的不同风格。
一次转换 => 同时生成多种样式
将样式与模型生成过程分离,给使用模型带来了很多好处:
想要将 SketchCode 模型应用到自己公司产品中的前端工程师可以按原样使用该模型,只需更改一个 CSS 文件以符合其公司的样式要求
可扩展性已内置 - 使用一张源图像,模型输出可立即编译为 5、10 或 50 种不同的预定义样式,因此用户可以看到他们网站的多个版本,并在浏览器中浏览这些网站
总结与展望
通过利用图像标注的研究成果,SketchCode 能够在几秒钟内将手绘网站线框图转换为可用的 HTML 网站。
该模型有些局限性,大概包括以下几点:
由于这个模型是用一个只有 16 个元素的词汇进行训练的,它不能预测训练数据之外的标记。下一步可能是使用更多元素(如图像,下拉菜单和表单)生成其他样例网站——Bootstrap components 是个练手的好网站:https://getbootstrap.com/docs/4.0/components/buttons/
实际生产环境中,网站有很多变化。创建一个更能反映这种变化的训练数据集的好方法是去爬取实际的网站,捕获他们的 HTML / CSS 代码以及网站内容的截图
手绘素描也有很多变化,CSS 修改技巧没有被模型完全学会。在手绘素描上生成更多变化的一种好方法是使用生成对抗网络来创建逼真的绘制网站图像
我很期待看到项目的进一步发展!

原文链接:https://blog.insightdatascience.com/automated-front-end-development-using-deep-learning-3169dd086e82
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




