公开课 | 微软Hackathon冠军队带你玩转新零售,堪比外挂的秘笈分享

今晚大数据文摘邀请到了【微软大中华区 零售解决方案新创业黑客松】大赛上海站冠军团队成员之一、观远数据合伙人周远(字节)。他将从赛题背景、数据探索、特征工程、模型调优等方面,为大家带来观远团队在刚结束的黑客松大赛上的第一手经验:
销量数据预测有哪些难点?
零售数据有哪些特征、需要怎样做预处理?
时间序列、树模型、深度学习模型之间应该怎样选择?
如何进一步优化模型?
大家扫码即可加入直播间👇
时间:2月5日(周一)18:00
形式:语音+PPT直播

↑可永久回听↑
黑客松比赛介绍
黑客松(Hackathon)是黑客+马拉松(Hack+Marathon)的组合词,又叫编程马拉松,最初是流行于黑客(Hacker)群体的一种叫法,指多名黑客聚集在一起,以马拉松(不间断)的形式进行黑客活动。后来黑客松逐渐演化成一种活动模式,指一群人,在某一段特定的时间内,相聚在一起,以他们共同商定的方式,紧密合作、持续工作,实现一个共同的目标。
本次黑客松大赛由微软联合百威英博、可口可乐等零售行业大佬一起举办,微软提供云计算平台资源和技术支持,零售业大佬提供世界级快消品牌运营中的真实数据问题,参赛队伍做出库存需求、销量预测等创新解决方案。
大赛涉及顶级level+真实场景,与当下火热的新零售概念不谋而合。参赛队伍均为已获得融资的初创企业,成绩通过创新性、商业前景、技术可行性、客户业务结合度、成果展示等指标加权得出。更重要的是,通过线下的密切合作方式,可以与数据技术同行、潜在客户以及投资方进行近距离的交流。
夺冠历程

比赛由百威命题,我们(观远算法团队)选择的题目是销售数量预测(POS forecasting)。
这题的数据是百威全国各个渠道门店一年来的POS销售数据,目标是预测下个月各个门店各个产品的销量。门店总数有430+,产品总数有820+,总的数据量有400多万条每日销量记录。

比赛现场百威啤酒随意畅饮~
比赛的数据只有门店、商品ID,所以很多诸如门店位置、天气情况、当地收入水平、各种体育赛事信息、搜索引擎的关键词趋势等等特征都无法加入,给比赛增加了一定的难度。
为此,我们首先查看并分析了数据的统计特征:
缺失值
数值分布
可视化
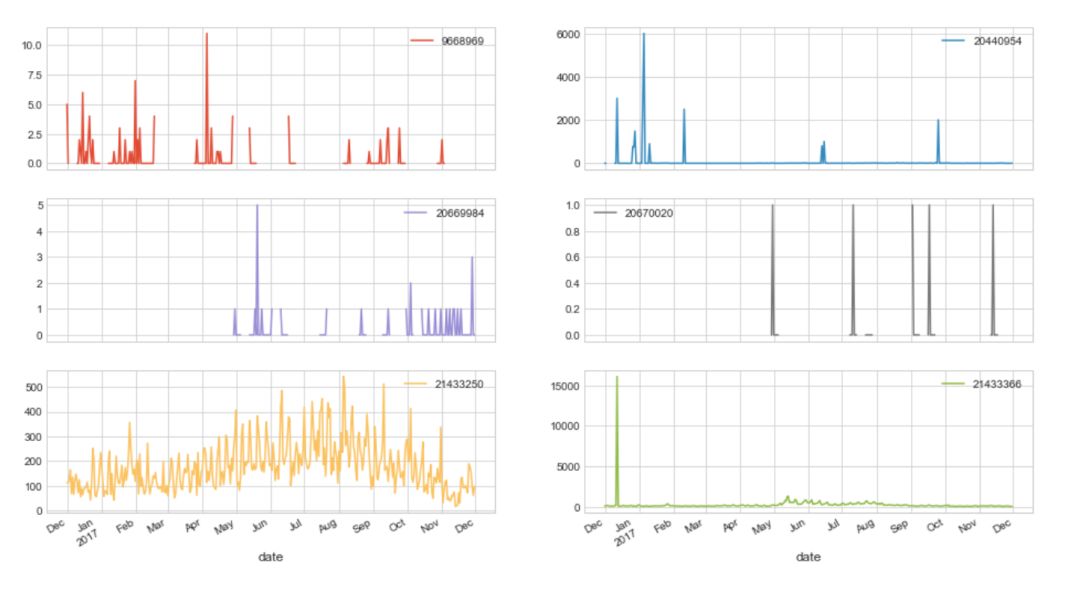
商品比较
初步分析后,我们对数据进行了预处理:
正则化:基于统计规则、基于模型预测、移动平均、对预测值做log处理
日期对齐
异常数据清理
接下来,就是特征选择了。在筛选了一些基础特征后,我们利用XGBoost叶子结点信息来生成新特征。但是用GBDT生成的特征进行数值回归效果一般。
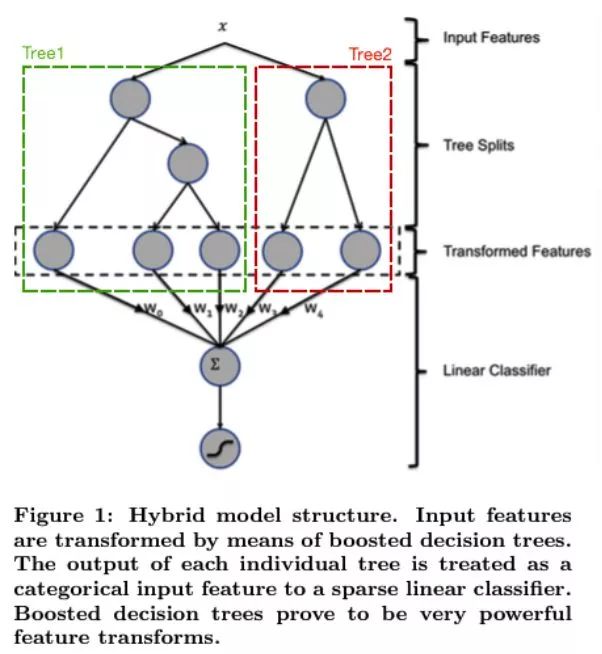
在此基础上,我们发现了一种更加高效地实现从高维稀疏特征来自动构建特征向量空间的embedding方法,其原理类似于著名的Word2vec在自然语言处理领域的应用。针对构建好的特征,用t-SNE进行降维处理,得到了各个月份,各个门店,各个商品的相关度。
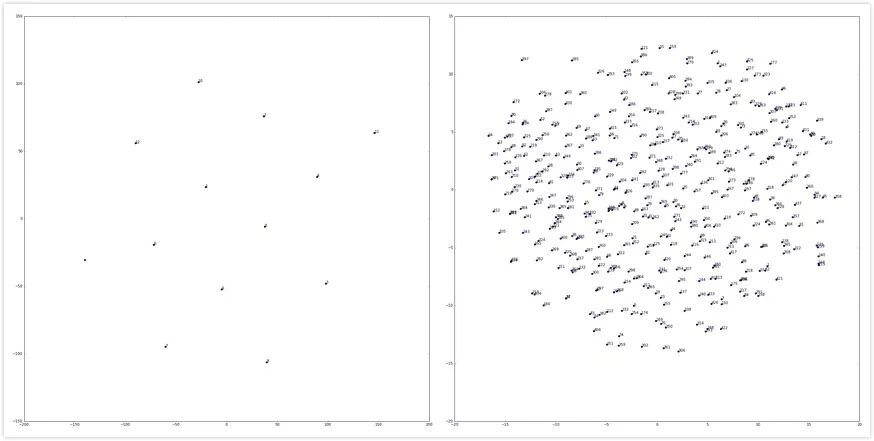
t-SNE降维
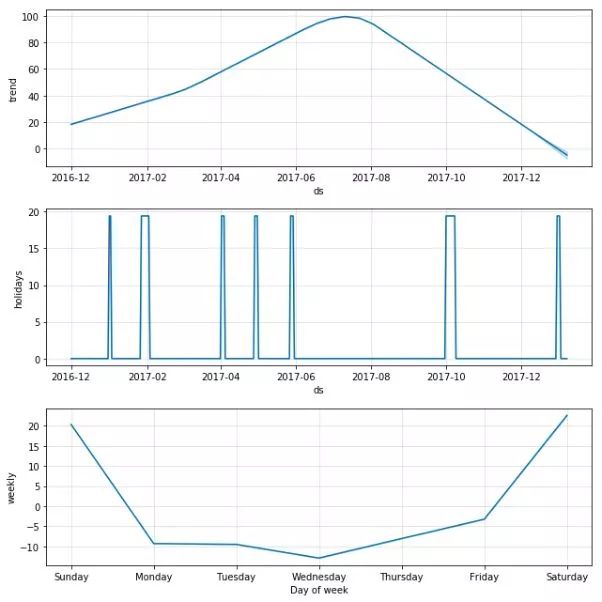
门店vs商品的节假日、周期性规律
接下来就是模型的选择和调试了。我们的基线是历史平均(平均绝对百分误差MAPE: 0.744),对比了时间序列模型、树模型、深度学习相关模型之后我们发现,在没有GPU的条件下,基于Keras + TensorFlow的神经网络表现一般(MAPE: 0.654),不如XGBoost(MAPE: 0.251)、LightGBM(MAPE: 0.256)。
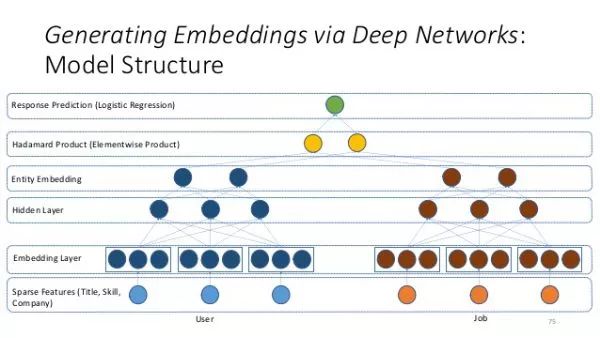
Embedding
虽然深度学习相关方法看起来很吸引人,感觉不用做复杂的特征工程了,但实际上各种网络的参数还是相当多的:embedding层的shape,全连接层的数量和大小,dropout设多少,要不要做batch norm,激活函数用什么,预测值要不要做成分类问题,还是做归一化转成sigmoid处理?
最终,我们选择了融合模型XGBoost、LightGBM、Random Forest,MAPE值为0.236。
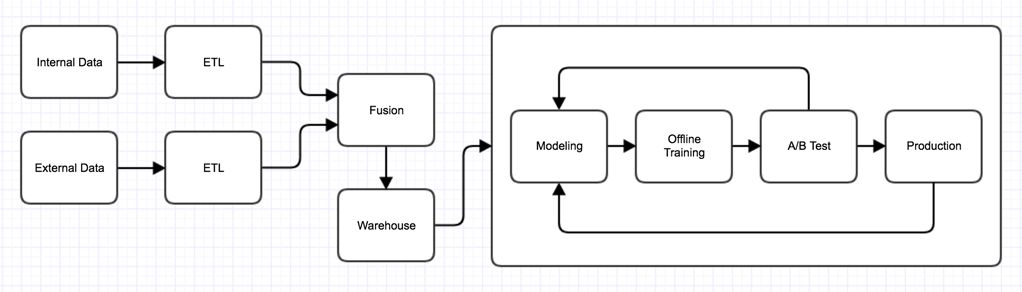
模型部署
嘉宾介绍
周远,花名字节。毕业于浙江大学电气工程学院,曾任职于微策略,阿里云从事软件性能优化,技术研发等工作。现作为观远数据技术合伙人,主要负责数据分析平台后端开发。
↑扫码进入直播间↑
黑客松冠军和你分享踩过的坑

五分钟,你可以掌握一个科学知识。
五分钟,你可以了解一个科技热点。
五分钟,你可以近观一个极客故事。
精确解构科技知识,个性表达投融观点。
欢迎关注线性资本。
Linear Path, Nonlinear Growth。






