如何在 Linux 中找到并删除重复文件 | Linux 中国

https://www.ostechnix.com/how-to-find-and-delete-duplicate-files-in-linux/
作者 | Sk
译者 | Andy Luo (pygmalion666) 🌟🌟共计翻译:2.0 篇 贡献时间:192 天
在编辑或修改配置文件或旧文件前,我经常会把它们备份到硬盘的某个地方,因此我如果意外地改错了这些文件,我可以从备份中恢复它们。但问题是如果我忘记清理备份文件,一段时间之后,我的磁盘会被这些大量重复文件填满 —— 我觉得要么是懒得清理这些旧文件,要么是担心可能会删掉重要文件。如果你们像我一样,在类 Unix 操作系统中,大量多版本的相同文件放在不同的备份目录,你可以使用下面的工具找到并删除重复文件。
提醒一句:
在删除重复文件的时请尽量小心。如果你不小心,也许会导致意外丢失数据[1]。我建议你在使用这些工具的时候要特别注意。
在 Linux 中找到并删除重复文件
出于本指南的目的,我将讨论下面的三个工具:
这三个工具是自由开源的,且运行在大多数类 Unix 系统中。
1. Rdfind
Rdfind 意即 redundant data find(冗余数据查找),是一个通过访问目录和子目录来找出重复文件的自由开源的工具。它是基于文件内容而不是文件名来比较。Rdfind 使用排序算法来区分原始文件和重复文件。如果你有两个或者更多的相同文件,Rdfind 会很智能的找到原始文件并认定剩下的文件为重复文件。一旦找到副本文件,它会向你报告。你可以决定是删除还是使用硬链接或者符号(软)链接[2]代替它们。
安装 Rdfind
Rdfind 存在于 AUR[3] 中。因此,在基于 Arch 的系统中,你可以像下面一样使用任一如 Yay[4] AUR 程序助手安装它。
$ yay -S rdfind
在 Debian、Ubuntu、Linux Mint 上:
$ sudo apt-get install rdfind
在 Fedora 上:
$ sudo dnf install rdfind
在 RHEL、CentOS 上:
$ sudo yum install epel-release
$ sudo yum install rdfind
用法
一旦安装完成,仅带上目录路径运行 Rdfind 命令就可以扫描重复文件。
$ rdfind ~/Downloads
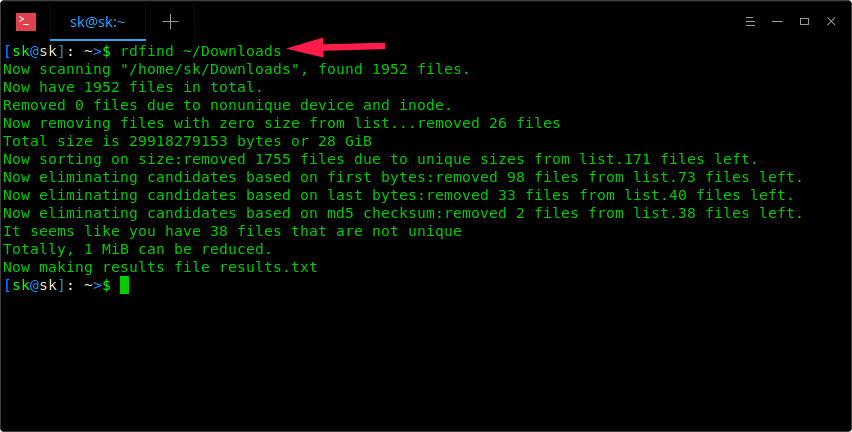
正如你看到上面的截屏,Rdfind 命令将扫描 ~/Downloads 目录,并将结果存储到当前工作目录下一个名为 results.txt 的文件中。你可以在 results.txt 文件中看到可能是重复文件的名字。
$ cat results.txt
# Automatically generated
# duptype id depth size device inode priority name
DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex
DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex
[...]
DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf
DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf
# end of file
通过检查 results.txt 文件,你可以很容易的找到那些重复文件。如果愿意你可以手动的删除它们。
此外,你可在不修改其他事情情况下使用 -dryrun 选项找出所有重复文件,并在终端上输出汇总信息。
$ rdfind -dryrun true ~/Downloads
一旦找到重复文件,你可以使用硬链接或符号链接代替他们。
使用硬链接代替所有重复文件,运行:
$ rdfind -makehardlinks true ~/Downloads
使用符号链接/软链接代替所有重复文件,运行:
$ rdfind -makesymlinks true ~/Downloads
目录中有一些空文件,也许你想忽略他们,你可以像下面一样使用 -ignoreempty 选项:
$ rdfind -ignoreempty true ~/Downloads
如果你不再想要这些旧文件,删除重复文件,而不是使用硬链接或软链接代替它们。
删除重复文件,就运行:
$ rdfind -deleteduplicates true ~/Downloads
如果你不想忽略空文件,并且和所哟重复文件一起删除。运行:
$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
更多细节,参照帮助部分:
$ rdfind --help
手册页:
$ man rdfind
2. Fdupes
Fdupes 是另一个在指定目录以及子目录中识别和移除重复文件的命令行工具。这是一个使用 C 语言编写的自由开源工具。Fdupes 通过对比文件大小、部分 MD5 签名、全部 MD5 签名,最后执行逐个字节对比校验来识别重复文件。
与 Rdfind 工具类似,Fdupes 附带非常少的选项来执行操作,如:
安装 Fdupes
Fdupes 存在于大多数 Linux 发行版的默认仓库中。
在 Arch Linux 和它的变种如 Antergos、Manjaro Linux 上,如下使用 Pacman 安装它。
$ sudo pacman -S fdupes
在 Debian、Ubuntu、Linux Mint 上:
$ sudo apt-get install fdupes
在 Fedora 上:
$ sudo dnf install fdupes
在 RHEL、CentOS 上:
$ sudo yum install epel-release
$ sudo yum install fdupes
用法
Fdupes 用法非常简单。仅运行下面的命令就可以在目录中找到重复文件,如:~/Downloads。
$ fdupes ~/Downloads
我系统中的样例输出:
/home/sk/Downloads/Hyperledger.pdf
/home/sk/Downloads/Hyperledger(1).pdf
你可以看到,在 /home/sk/Downloads/ 目录下有一个重复文件。它仅显示了父级目录中的重复文件。如何显示子目录中的重复文件?像下面一样,使用 -r 选项。
$ fdupes -r ~/Downloads
现在你将看到 /home/sk/Downloads/ 目录以及子目录中的重复文件。
Fdupes 也可用来从多个目录中迅速查找重复文件。
$ fdupes ~/Downloads ~/Documents/ostechnix
你甚至可以搜索多个目录,递归搜索其中一个目录,如下:
$ fdupes ~/Downloads -r ~/Documents/ostechnix
上面的命令将搜索 ~/Downloads 目录,~/Documents/ostechnix 目录和它的子目录中的重复文件。
有时,你可能想要知道一个目录中重复文件的大小。你可以使用 -S 选项,如下:
$ fdupes -S ~/Downloads
403635 bytes each:
/home/sk/Downloads/Hyperledger.pdf
/home/sk/Downloads/Hyperledger(1).pdf
类似的,为了显示父目录和子目录中重复文件的大小,使用 -Sr 选项。
我们可以在计算时分别使用 -n 和 -A 选项排除空白文件以及排除隐藏文件。
$ fdupes -n ~/Downloads
$ fdupes -A ~/Downloads
在搜索指定目录的重复文件时,第一个命令将排除零长度文件,后面的命令将排除隐藏文件。
汇总重复文件信息,使用 -m 选项。
$ fdupes -m ~/Downloads
1 duplicate files (in 1 sets), occupying 403.6 kilobytes
删除所有重复文件,使用 -d 选项。
$ fdupes -d ~/Downloads
样例输出:
[1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf
[2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf
Set 1 of 1, preserve files [1 - 2, all]:
这个命令将提示你保留还是删除所有其他重复文件。输入任一号码保留相应的文件,并删除剩下的文件。当使用这个选项的时候需要更加注意。如果不小心,你可能会删除原文件。
如果你想要每次保留每个重复文件集合的第一个文件,且无提示的删除其他文件,使用 -dN 选项(不推荐)。
$ fdupes -dN ~/Downloads
当遇到重复文件时删除它们,使用 -I 标志。
$ fdupes -I ~/Downloads
关于 Fdupes 的更多细节,查看帮助部分和 man 页面。
$ fdupes --help
$ man fdupes
3. FSlint
FSlint 是另外一个查找重复文件的工具,有时我用它去掉 Linux 系统中不需要的重复文件并释放磁盘空间。不像另外两个工具,FSlint 有 GUI 和 CLI 两种模式。因此对于新手来说它更友好。FSlint 不仅仅找出重复文件,也找出坏符号链接、坏名字文件、临时文件、坏的用户 ID、空目录和非精简的二进制文件等等。
安装 FSlint
FSlint 存在于 AUR[5],因此你可以使用任一 AUR 助手安装它。
$ yay -S fslint
在 Debian、Ubuntu、Linux Mint 上:
$ sudo apt-get install fslint
在 Fedora 上:
$ sudo dnf install fslint
在 RHEL,CentOS 上:
$ sudo yum install epel-release
$ sudo yum install fslint
一旦安装完成,从菜单或者应用程序启动器启动它。
FSlint GUI 展示如下:
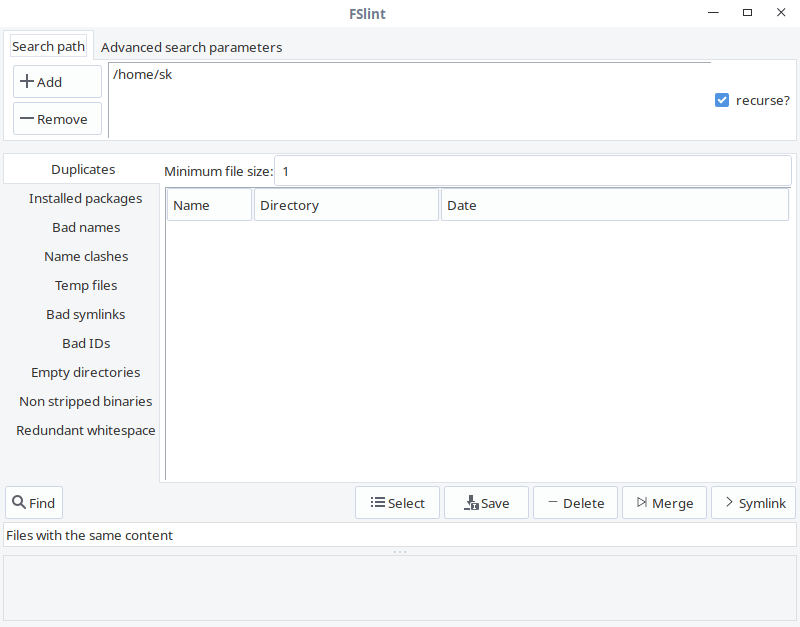
如你所见,FSlint 界面友好、一目了然。在 “Search path” 栏,添加你要扫描的目录路径,点击左下角 “Find” 按钮查找重复文件。验证递归选项可以在目录和子目录中递归的搜索重复文件。FSlint 将快速的扫描给定的目录并列出重复文件。
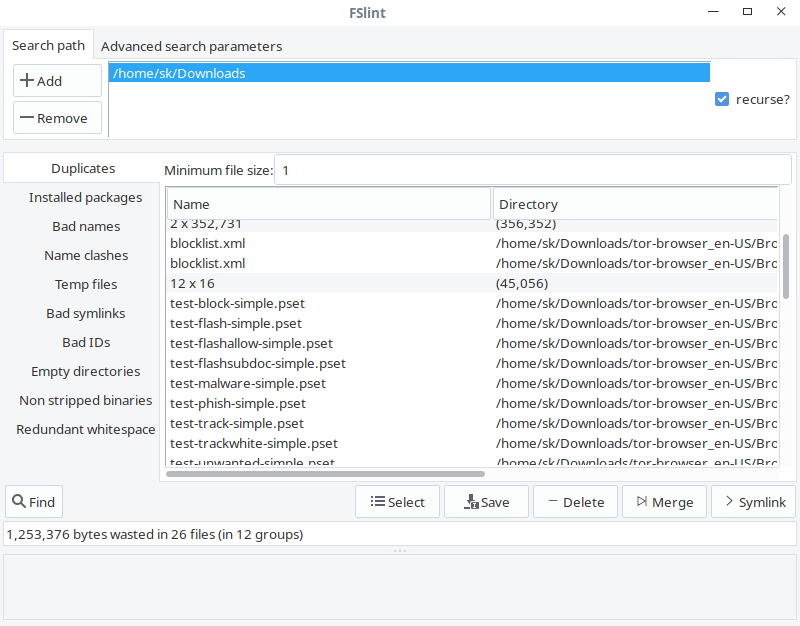
从列表中选择那些要清理的重复文件,也可以选择 “Save”、“Delete”、“Merge” 和 “Symlink” 操作他们。
在 “Advanced search parameters” 栏,你可以在搜索重复文件的时候指定排除的路径。
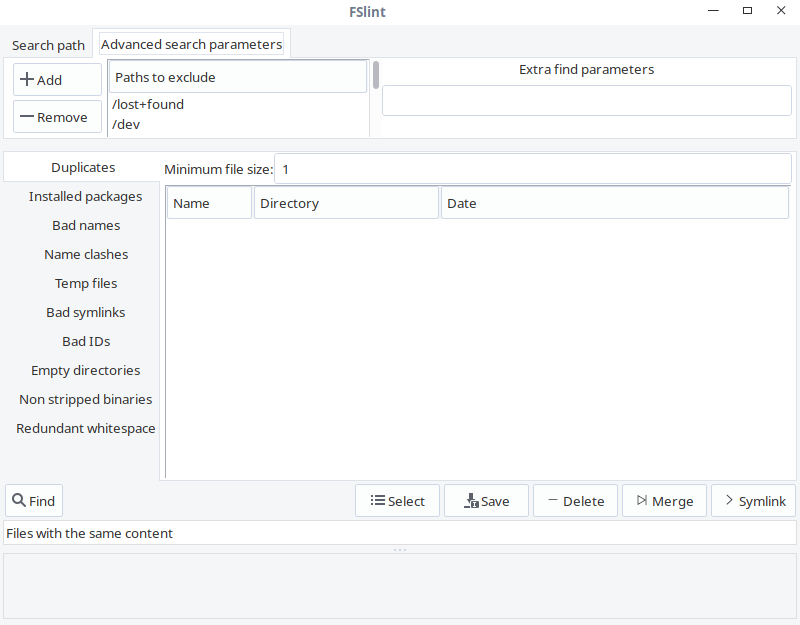
FSlint 命令行选项
FSlint 提供下面的 CLI 工具集在你的文件系统中查找重复文件。
findup — 查找重复文件
findnl — 查找名称规范(有问题的文件名)
findu8 — 查找非法的 utf8 编码的文件名
findbl — 查找坏链接(有问题的符号链接)
findsn — 查找同名文件(可能有冲突的文件名)
finded — 查找空目录
findid — 查找死用户的文件
findns — 查找非精简的可执行文件
findrs — 查找文件名中多余的空白
findtf — 查找临时文件
findul — 查找可能未使用的库
zipdir — 回收 ext2 目录项下浪费的空间
所有这些工具位于 /usr/share/fslint/fslint/fslint 下面。
例如,在给定的目录中查找重复文件,运行:
$ /usr/share/fslint/fslint/findup ~/Downloads/
类似的,找出空目录命令是:
$ /usr/share/fslint/fslint/finded ~/Downloads/
获取每个工具更多细节,例如:findup,运行:
$ /usr/share/fslint/fslint/findup --help
关于 FSlint 的更多细节,参照帮助部分和 man 页。
$ /usr/share/fslint/fslint/fslint --help
$ man fslint
总结
现在你知道在 Linux 中,使用三个工具来查找和删除不需要的重复文件。这三个工具中,我经常使用 Rdfind。这并不意味着其他的两个工具效率低下,因为到目前为止我更喜欢 Rdfind。好了,到你了。你的最喜欢哪一个工具呢?为什么?在下面的评论区留言让我们知道吧。
就到这里吧。希望这篇文章对你有帮助。更多的好东西就要来了,敬请期待。
谢谢!
via: https://www.ostechnix.com/how-to-find-and-delete-duplicate-files-in-linux/
作者:SK[7] 选题:lujun9972 译者:pygmalion666 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出