决策树的复兴?结合神经网络,提升ImageNet分类准确率且可解释
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
鱼和熊掌我都要!BAIR公布神经支持决策树新研究,兼顾准确率与可解释性。


BAIR 博客地址:https://bair.berkeley.edu/blog/2020/04/23/decisions/
论文地址:https://arxiv.org/abs/2004.00221
开源项目地址:https://github.com/alvinwan/neural-backed-decision-trees
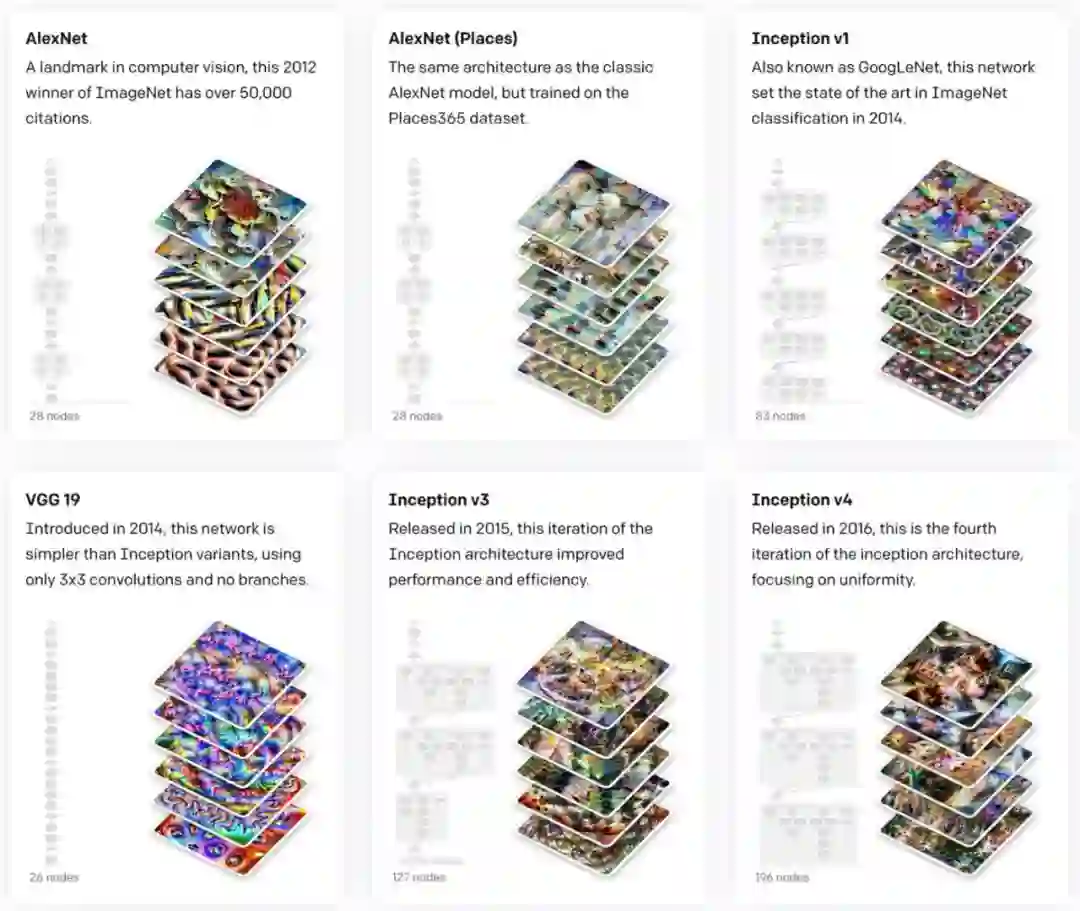
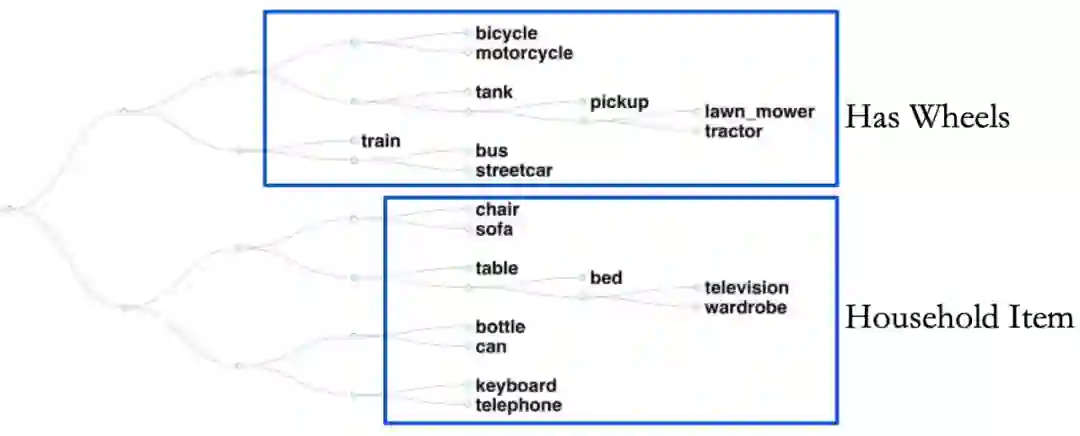
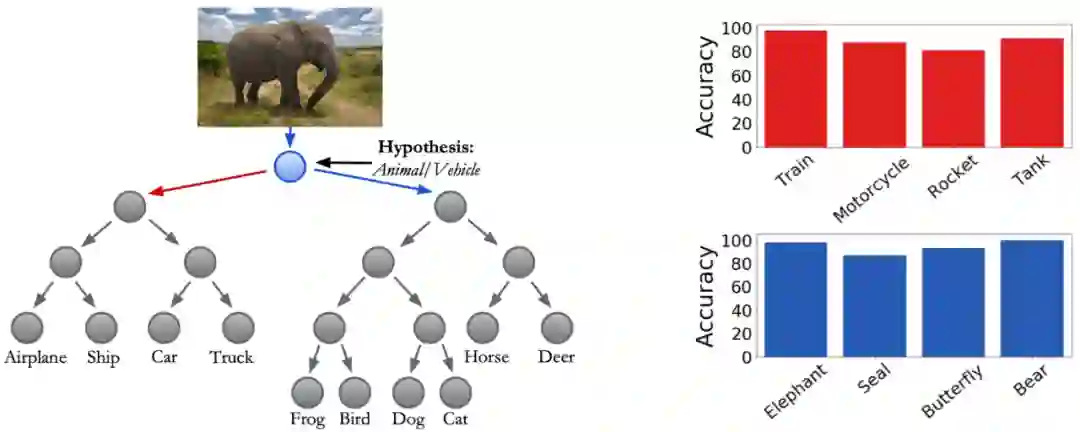
决策树的优势与缺陷
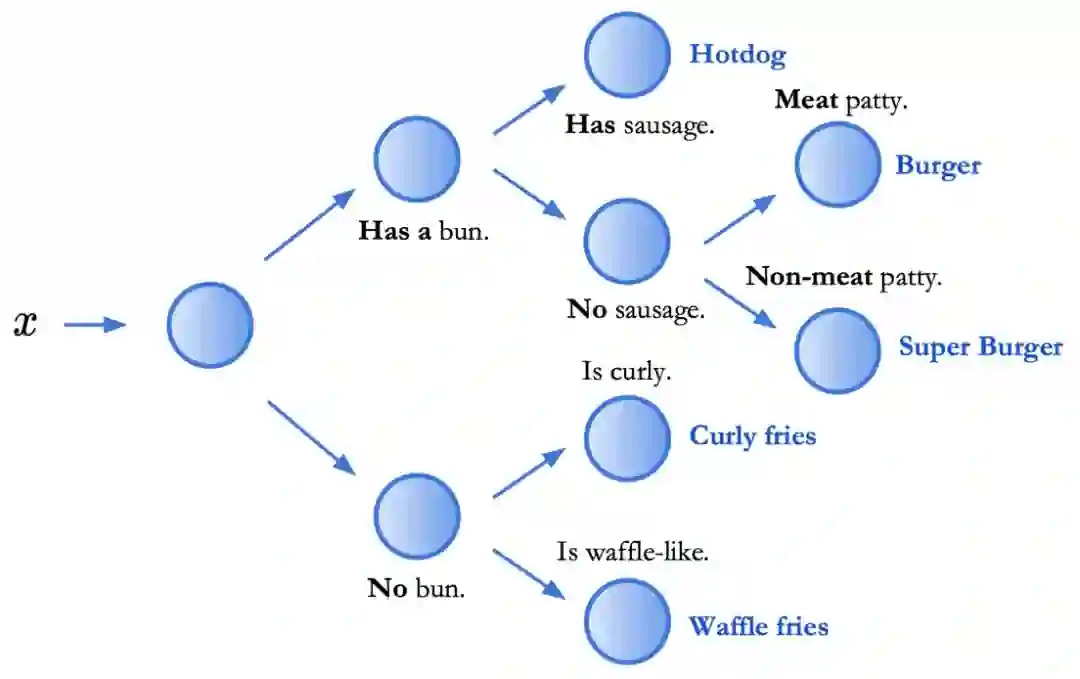
走近神经支持决策树
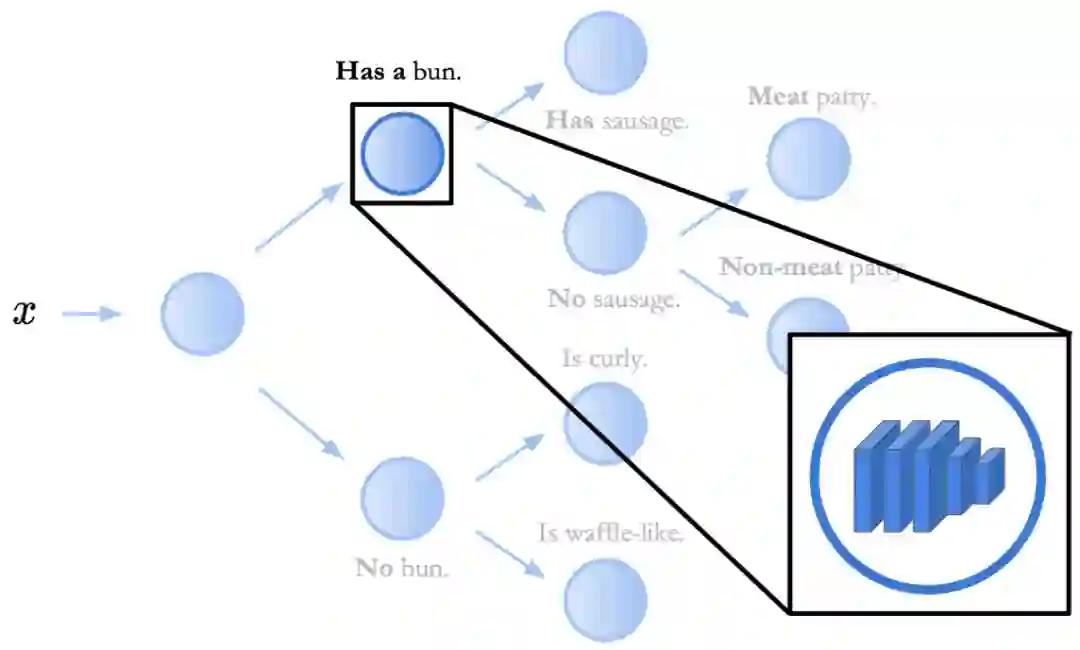
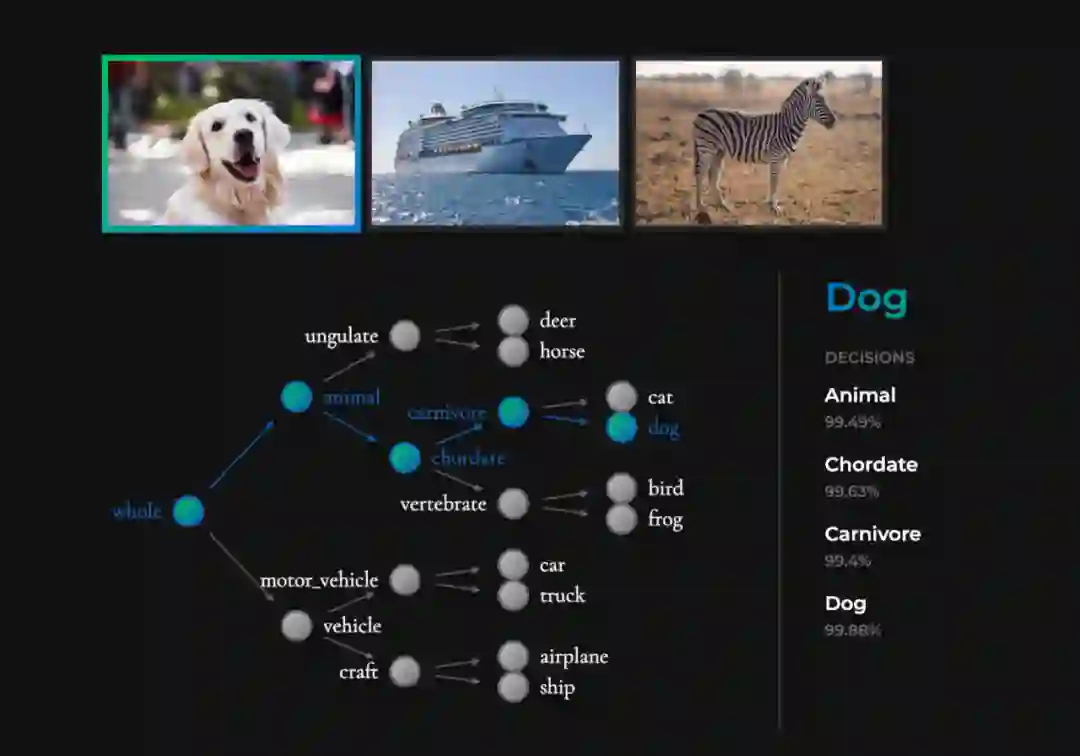
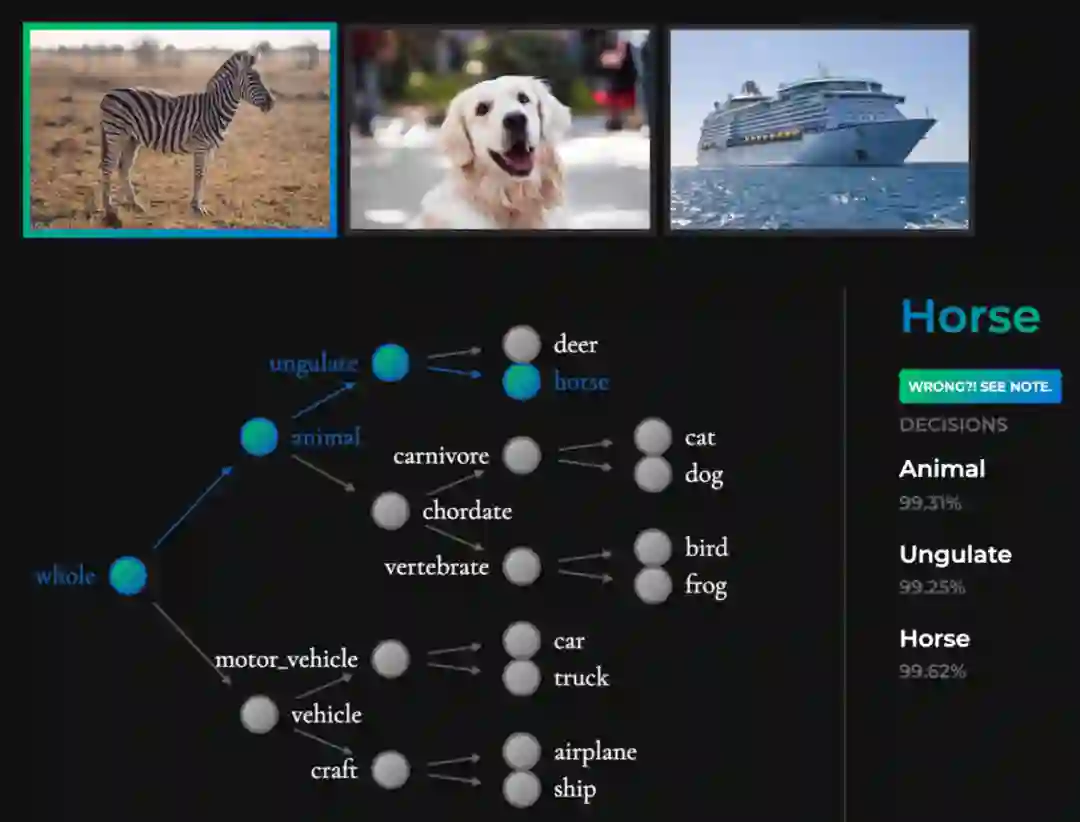
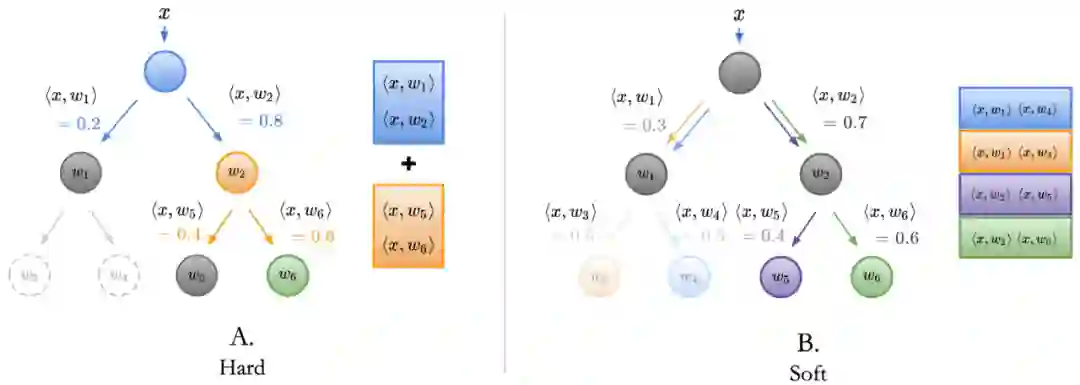
神经支持决策树是如何解释的
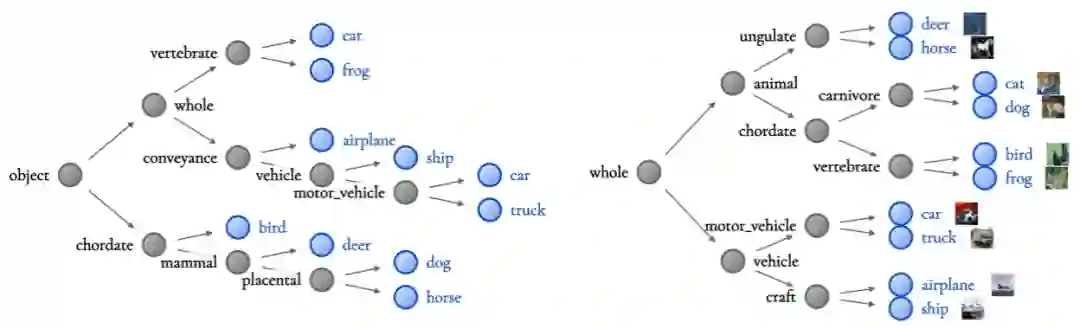
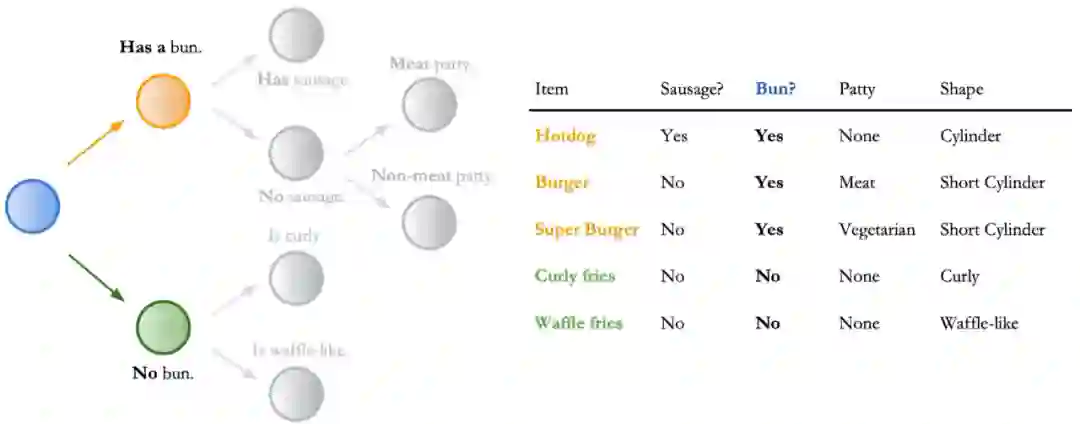
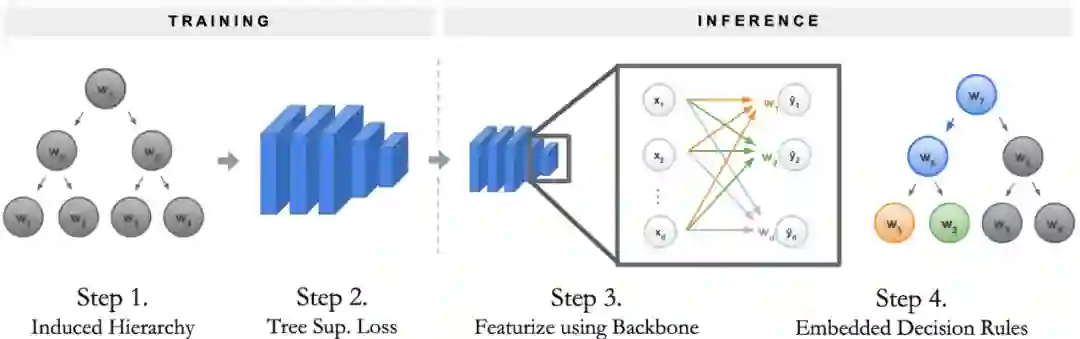
How it Works
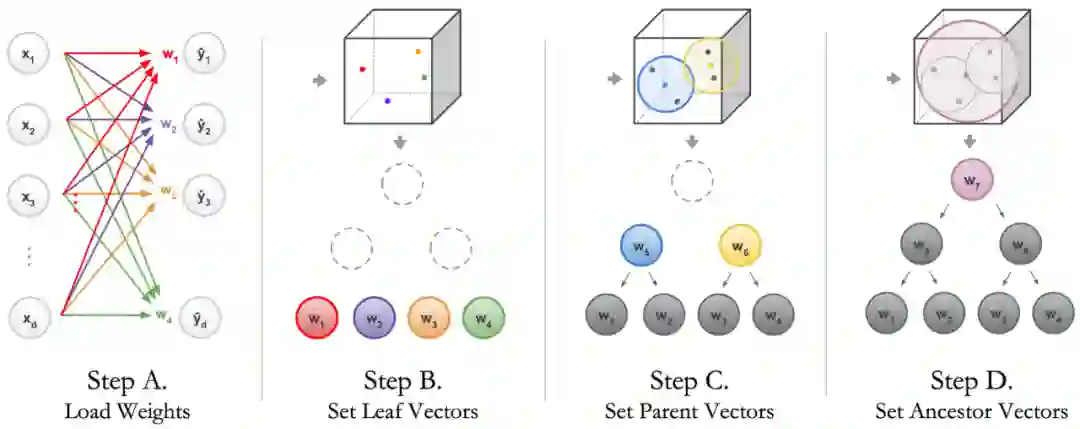
为决策树构建称为诱导层级「Induced Hierarchy」的层级;
该层级产生了一个称为树监督损失「Tree Supervision Loss」的独特损失函数;
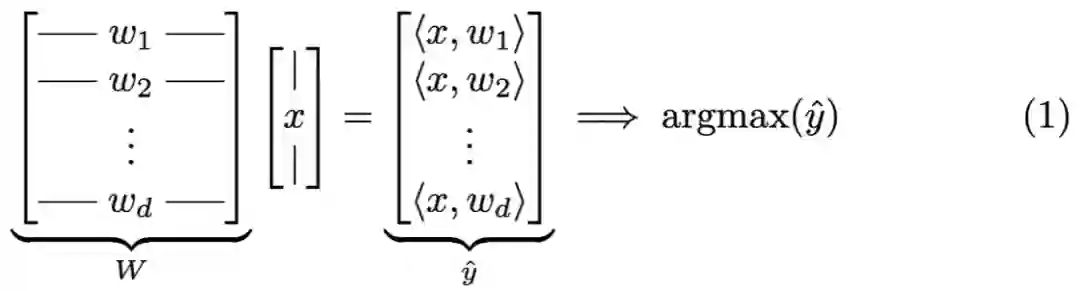
通过将样本传递给神经网络主干开始推断。在最后一层全连接层之前,主干网络均为神经网络;
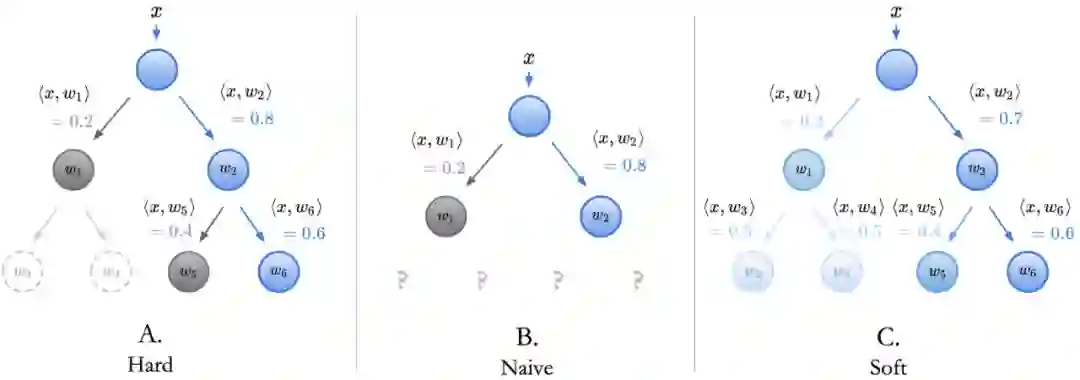
以序列决策法则方式运行最后一层全连接层结束推断,研究者将其称为嵌入决策法则「Embedded Decision Rules」。
使用指南
pip install nbdt
nbdt https://images.pexels.com/photos/
126407/pexels-photo
-126407.jpeg?auto=compress&cs=tinysrgb&dpr=
2&w=
32
# OR run on a local image
nbdt /imaginary/path/to/local/image.png
Demo:http://nbdt.alvinwan.com/demo/
Colab:http://nbdt.alvinwan.com/notebook/
from nbdt.model
import SoftNBDT
from nbdt.models
import ResNet18, wrn28_10_cifar10, wrn28_10_cifar100, wrn28_10
# use wrn28_10 for TinyImagenet200
model = wrn28_10_cifar10()
model = SoftNBDT(
pretrained=
True,
dataset=
'CIFAR10',
arch=
'wrn28_10_cifar10',
model=model)
推荐阅读:


△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~

登录查看更多
相关内容

决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
专知会员服务
14+阅读 · 2020年1月1日



相关VIP内容
专知会员服务
14+阅读 · 2020年1月1日
相关资讯
相关论文